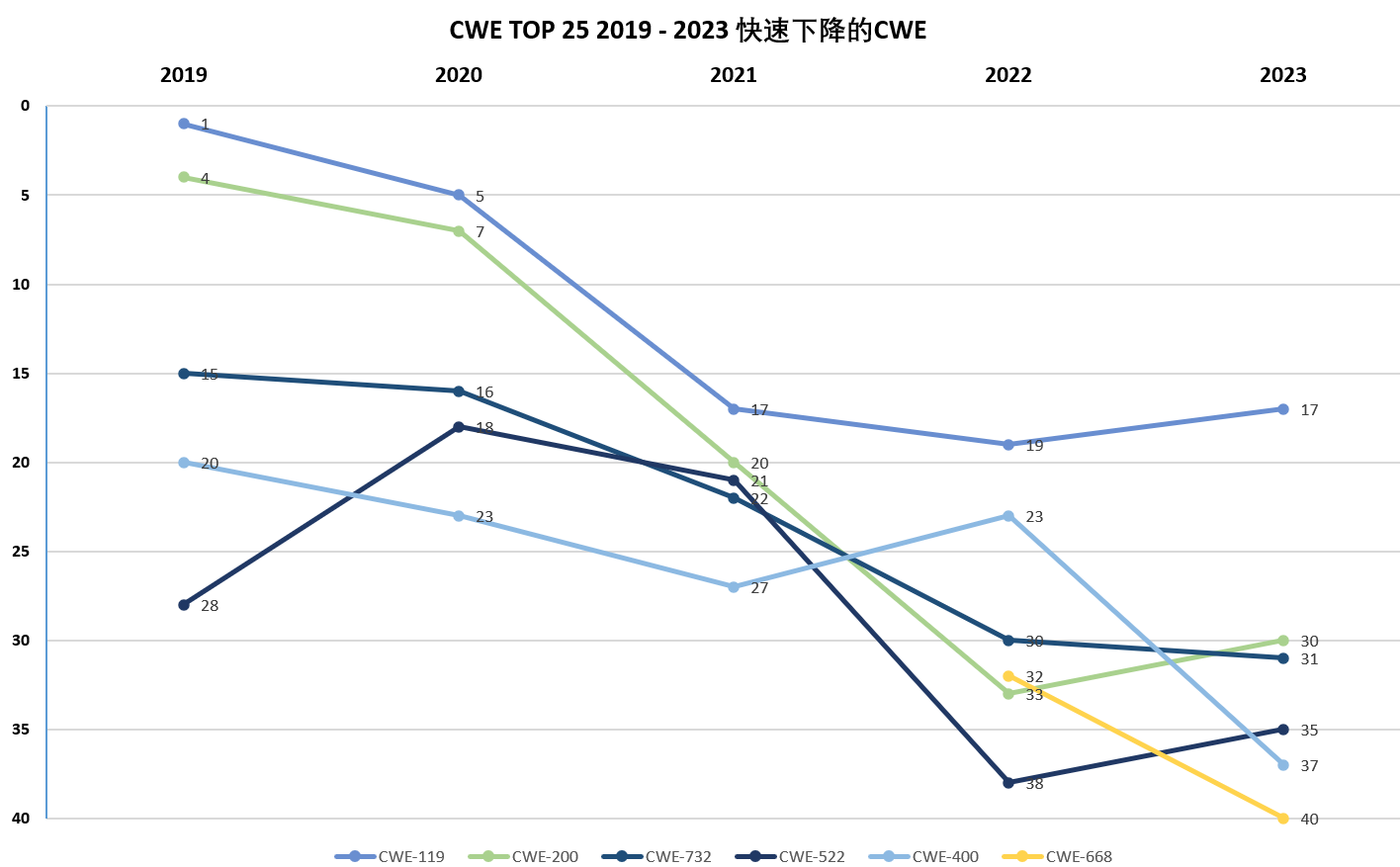
Scrapy是一个用于爬取数据的Python框架。下面是Scrapy框架的基本操作步骤:
-
安装Scrapy:首先,确保你已经安装好了Python和pip。然后,在命令行中运行以下命令安装Scrapy:
pip install scrapy -
创建Scrapy项目:使用Scrapy提供的命令行工具创建一个新的Scrapy项目。在命令行中切换到你想要创建项目的目录,并执行以下命令:
scrapy startproject project_name。其中,project_name是你自己定义的项目名称。 -
定义爬虫:进入项目目录,并在命令行中执行以下命令创建一个新的爬虫:
scrapy genspider spider_name website.com。其中,spider_name是你自己定义的爬虫名称,website.com是你要爬取数据的目标网站的域名。 -
编写爬虫代码:在项目目录下的
spiders文件夹中找到你创建的爬虫文件(以.py结尾),使用文本编辑器打开该文件。在爬虫代码中,你可以定义如何发送请求、处理响应和提取数据等操作。你可以参考Scrapy官方文档来了解更多关于编写爬虫代码的详细信息。 -
配置爬虫:如果需要,你可以在项目目录下的
settings.py文件中配置爬虫的相关设置,例如设置请求头、设置User-Agent等。