嗨,亲爱的爬虫开发者们!在当今的数据驱动时代,大规模数据的爬取对于许多领域的研究和应用至关重要在本文中,我将与你分享大规模数据爬取的实战经验,重点介绍增量和分布式爬虫架构的应用,帮助你高效地处理海量数据。
1.增量爬虫
增量爬虫是指只爬取新增或更新的数据,而不是重新爬取整个网站的所有数据。这种方式可以大大提高爬虫的效率和性能。
实现方法:
-记录数据状态:对已经爬取的数据进行标记或记录,例如使用数据库或缓存来保存已经访问的URL和相关数据的状态。
-定期检查更新:定期运行增量爬虫,通过比对已有数据和目标网站的差异来确定新增或更新的内容。
-增量数据处理:对新增或更新的数据进行处理,例如存储到数据库、更新索引或进行进一步的分析。
2.分布式爬虫架构
分布式爬虫架构是指将爬虫任务分解为多个子任务,并在多台机器上并行执行,以提高爬取效率和处理能力。
实现方法:
-任务分配和调度:使用任务调度器将爬虫任务分配给不同的爬虫节点,确保任务的均衡分布和高效执行。
-数据通信和同步:爬虫节点之间需要进行数据通信和同步,例如使用消息队列或分布式存储系统来传递任务和数据。
-分布式数据处理:将爬取的数据分布式存储,例如使用分布式数据库或文件系统来存储和管理海量数据。
应用场景:
-搜索引擎索引:分布式爬虫架构可用于搜索引擎的网页抓取和索引构建,以提供准确和及时的搜索结果。
-大数据分析:大规模数据爬取和增量更新可用于大数据分析和机器学习任务,帮助挖掘有价值的信息和模式。
-商业情报收集:分布式爬虫可以帮助企业收集竞争对手的信息、市场趋势和用户反馈,支持决策和战略规划。
下面提供两组对应的爬虫示例代码:
pytho import requests from bs4 import BeautifulSoup #增量爬虫示例 def incremental_crawler(): #获取已爬取的URL列表 crawled_urls=get_crawled_urls_from_database()#从数据库中获取已爬取的URL列表 #获取目标网站的最新数据 url='https://www.example.com'#替换为目标网站的URL response=requests.get(url) if response.status_code==200: soup=BeautifulSoup(response.text,'html.parser') links=soup.find_all('a')#根据实际网页结构修改选择器 for link in links: href=link.get('href') if href not in crawled_urls: #处理新增的链接 process_link(href) #将已爬取的URL保存到数据库 save_crawled_url_to_database(href) else: print('Failed to retrieve data from the website.') #分布式爬虫架构示例 def distributed_crawler(): #任务分配和调度代码 #爬虫节点代码 def crawler(url): response=requests.get(url) if response.status_code==200: #数据处理代码 process_data(response.text) else: print('Failed to retrieve data from',url) #数据通信和同步代码 #分布式数据处理代码 def process_data(data): #数据存储或进一步处理的代码 #主程序 if __name__=='__main__': #获取待爬取的URL列表 urls=get_urls_to_crawl_from_queue()#从任务队列中获取待爬取的URL列表 #并行执行爬虫任务 for url in urls: crawler(url) #运行示例代码 if __name__=='__main__': incremental_crawler() print('---') ditributed_crawler()
请注意,以上示例代码只提供了一个基本的框架,具体的实现方式需要根据实际需求和系统架构进行调整。同时,在进行大规模数据爬取时,需要遵守相关的法律法规和网站的使用条款,确保合法合规地进行数据爬取和处理。
大规模数据爬取是一个复杂而挑战性的任务,但通过使用增量和分布式爬虫架构,我们可以提高爬虫的效率和性能,更好地处理海量数据。希望以上实战经验对你在大规模数据爬取的旅程中有所帮助!如果你有任何问题或想法,请在评论区分享!让我们一起探索大数据爬取的精彩世界!
希望以上示例代码和实战经验对你在大规模数据爬取的实践中有所帮助!如果您有更多的见解,欢迎评论区留言讨论
Eclipse
批量重命名
并发编程
自述
民商法
Tableau Desktop
镜像复制
数码管
服务监控
四大分析工具
CountDownLatch
cisp题库
tornado
汇编求解一元二次方程的解
推荐算法
自动装配原理之Starter
接口日志归档删除
运维开发
springboot二手交易
splunk
大规模数据爬取 - 增量和分布式爬虫架构实战
相关文章

PostgreSQL数据库定时备份脚本
大多数数据库管理系统都提供了自带的备份工具,可以使用这些工具来进行备份操作。 例如:
MySQL:使用 mysqldump 命令进行备份。PostgreSQL:使用 pg_dump 命令进行备份。 以下是一个用于定时备份 PostgreSQL 数据库的示例脚本。这个…
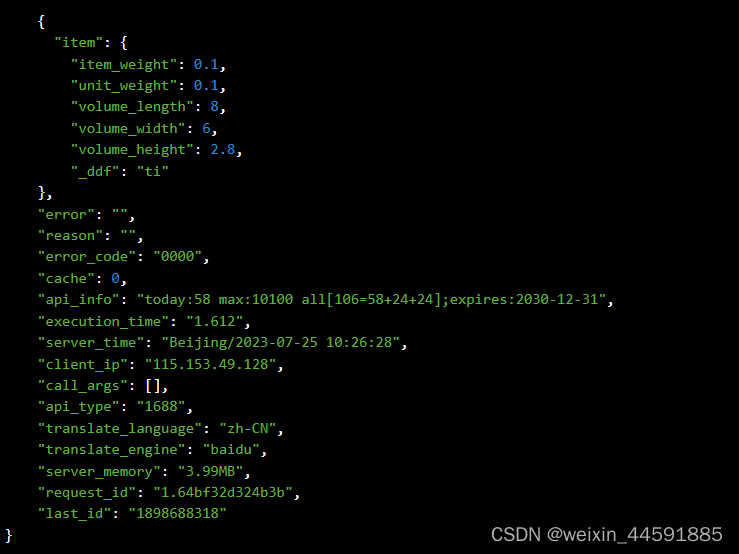
Java“牵手”1688商品跨境属性数据,1688API接口申请指南
1688平台商品详情跨境属性数据接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取1688商品的标题、价格、库存、月销量、总销量、库存、详情描述、图片,重量,详情描述等详细信息 。
获取商品详情接口API是一种用于…

Fooocus:一个简单且功能强大的Stable Diffusion webUI
Stable Diffusion是一个强大的图像生成AI模型,但它通常需要大量调整和提示工程。Fooocus的目标是改变这种状况。
Fooocus的创始人Lvmin Zhang(也是 ControlNet论文的作者)将这个项目描述为对“Stable Diffusion”和“ Midjourney”设计的重新…
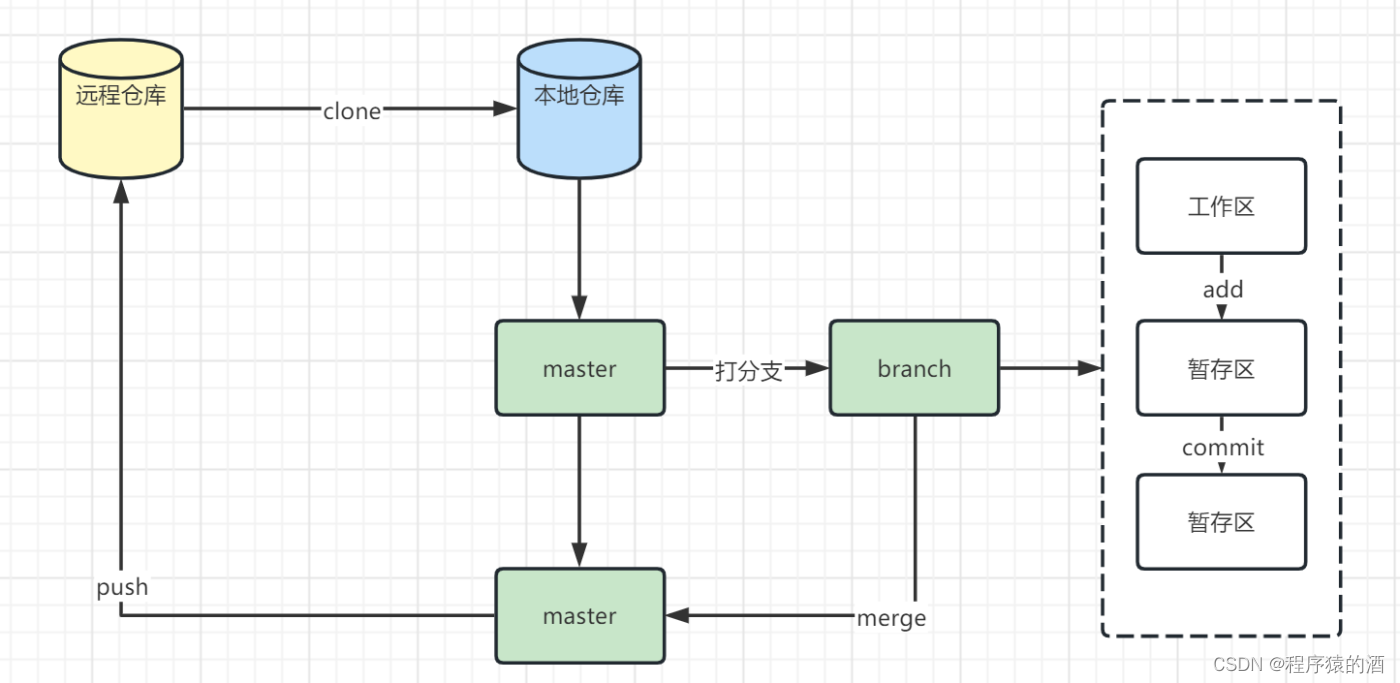
【Java架构-版本控制】-Git基础
本文摘要 Git作为版本控制工具,使用非常广泛,在此咱们由浅入深,分三篇文章(Git基础、Git进阶、Gitlab搭那家)来深入学习Git 文章目录 本文摘要1.Git仓库基本概念1.1 远程仓库(Remote)1.2 本地库(Repository) 2. Git仓库…

文件上传漏洞之条件竞争
这里拿upload-labs的第18关做演示 首先先看代码
$is_upload false;
$msg null;if(isset($_POST[submit])){$ext_arr array(jpg,png,gif);$file_name $_FILES[upload_file][name];$temp_file $_FILES[upload_file][tmp_name];$file_ext substr($file_name,strrpos($file_…

Element Plus 日期选择器的使用和属性
element plus 日期选择器如果如果没有进行处理 他会返回原有的属性值data格式 如果想要获取选中的日期时间就需要通过以下的代码来实现选中的值 format"YYYY/MM/DD" value-format"YYYY-MM-DD" <el-date-pickerv-model"formInline.date" type&…
【摆烂之小左】Maven配置IDEA教程
Maven是什么
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件。 Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则有较高的可重用性,所以常…
Druid配置类、Dubbo配置类、Captcha配置类、Redis配置类、RestTemplate配置类
DruidConfig配置类package com.xdclass.app.config;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.beans.factory.annotation.V…
最新文章
- Pandas库学习之DataFrame.head()函数
- Java流的概念及API
- vue3 vue页面根目录增加注释 keep-alive 不生效 需避开此位置
- “信息科技风险管理”和“IT审计智能辅助”两个大模块的部分功能详细介绍:
- 深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销
- Android13 应用代码中修改热点默认密码
- 简易Windows media player
- Android OkHttp完全解析 是时候来了解OkHttp了
- Win32环境下动态链接库(DLL)编程原理
- 母亲 (转)
- .Net多线程总结(二)-BackgroundWorker
- [dotNET]“ThreadPool 对象中没有足够的自由线程来完成操作”的现象和解决办法