从本篇博客正式开始深度学习项目的记录,实例代码只会放通用的代码,数据集和训练数据也是不会全部放出。
系列文章:
基于Yolov5目标检测的物体分类识别及定位(一) -- 数据集原图获取与标注
基于Yolov5目标检测的物体分类识别及定位(二) -- yolov5运行环境搭建及label格式转换
目录
原图获取
分析
爬取图片
数据标注
labelme介绍
labelme%E5%AE%89%E8%A3%85-toc" style="margin-left:80px;">labelme安装
启动自动化
labelme%E4%BD%BF%E7%94%A8-toc" style="margin-left:80px;">labelme使用
原图获取
分析
想要让人工智能有智能,得先训练它,训练要有数据集,制作数据集要有原始数据。
所以搭建系统的第一步,就是从网上爬一些图片来构建数据集,为什么是爬虫爬取呢,因为太多了,手动下载根本不现实。
爬取图片
写个爬虫在百度谷歌爬取图片,搜索关键字然后下拉界面到底(设置一个超级大的数或者一直下拉),获取所有的图片元素。
比如百度图片搜索结果的
@class="imgitem" 标签的 data-objurl 属性(图片原图的绝对地址),注意不能获取 @class="main_img img-hover" 标签元素里的 src 和 data-imgurl 属性,这两个里的链接都是缩略图,不是原图。
部分代码展示如下(稍作修改即可复用):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import sys
import urllib
import urllib.request
import requests
class PicSpider(object):
def main(self):
chrome_options = Options()
chrome_options.add_argument('--headless')
self.browser1 = webdriver.Chrome(chrome_options=chrome_options)
get_url = 'https://www.baidu.com'
self.browser1.get(get_url)
time.sleep(5)
keys_search = ['cat', 'dog']
key_cur = 0
key_max = len(keys_search) - 1
while True:
pic_count = 0
if key_cur > key_max:
break
the_keyword = keys_search[key_cur]
search_url = 'https://image.baidu.com/search/index?tn=baiduimage'\
'&ct=201326592&lm=-1&cl=2&ie=gb18030'\
'&word=' + the_keyword + \
'&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=000000'
self.browser1.get(search_url)
time.sleep(5)
pre_height = 0
now_height = 0
print(self.browser1.execute_script(
"return document.documentElement.scrollHeight;"))
while True:
self.browser1.execute_script("scrollBy(0,10000)")
time.sleep(3)
now_height = self.browser1.execute_script(
"return document.documentElement.scrollHeight;")
print(now_height)
if now_height == pre_height:
break
if now_height >= 10000000:
break
pre_height = now_height
time.sleep(15)
try:
es = self.browser1.find_elements_by_xpath('//li[@class="imgitem"]')
except Exception as e:
print(e)
if len(es) == 0:
break
for ae in es:
try:
aurl = ae.get_attribute('data-objurl')
except Exception as e:
print(e)
else:
pic_count += 1
try:
urllib.request.urlretrieve(aurl, './'+the_keyword+'/'+the_keyword+'_%s.jpg'%pic_count)
except Exception as e:
print('图片下载异常:' + str(e))
else:
print('下载成功', pic_count)
key_cur += 1
self.browser1.quit()
if __name__ == '__main__':
spider = PicSpider()
spider.main()
数据标注
图片爬完,分类放在几个文件夹里,然后就可以开始数据标注了。
我们选择labelme来进行这一步工作。
labelme介绍
Labelme 是一个图形界面的图像标注软件,其设计灵感来自于 http://labelme.csail.mit.edu/
它是用 Python 语言编写的,图形界面使用的是 Qt(PyQt)
对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。
对图像进行进行 flag 形式的标注(可用于图像分类 和 清理 任务)。
视频标注
生成 VOC 格式的数据集(for semantic / instance segmentation)
生成 COCO 格式的数据集(for instance segmentation)
labelme%E5%AE%89%E8%A3%85">labelme安装
这里介绍Windows的anaconda安装方法(个人办公习惯)
更多安装参考:数据标注软件labelme详解_黑暗星球-CSDN博客_labelme(感谢)
conda create --name=labelme python=3.6
conda activate labelme
pip install pyqt5
pip install labelme
conda install pillow=4.0.0 # Windows 上的 Pillow5 会导致 dll 加载错误,所以请安装 Pillow4。启动自动化
接下来是启动labelme进行标注,相关命令如下
labelme # 启动的命令
labelme data_annotated/ # 指定图像文件夹的命令然后我把命令放在了bat文件中,以便直接双击启动label
CALL conda activate labelme # 不用CALL来启动conda的话,cmd程序就会闪退
labelme D:\Python\yolov5\datas\f16\labelme%E4%BD%BF%E7%94%A8">labelme使用
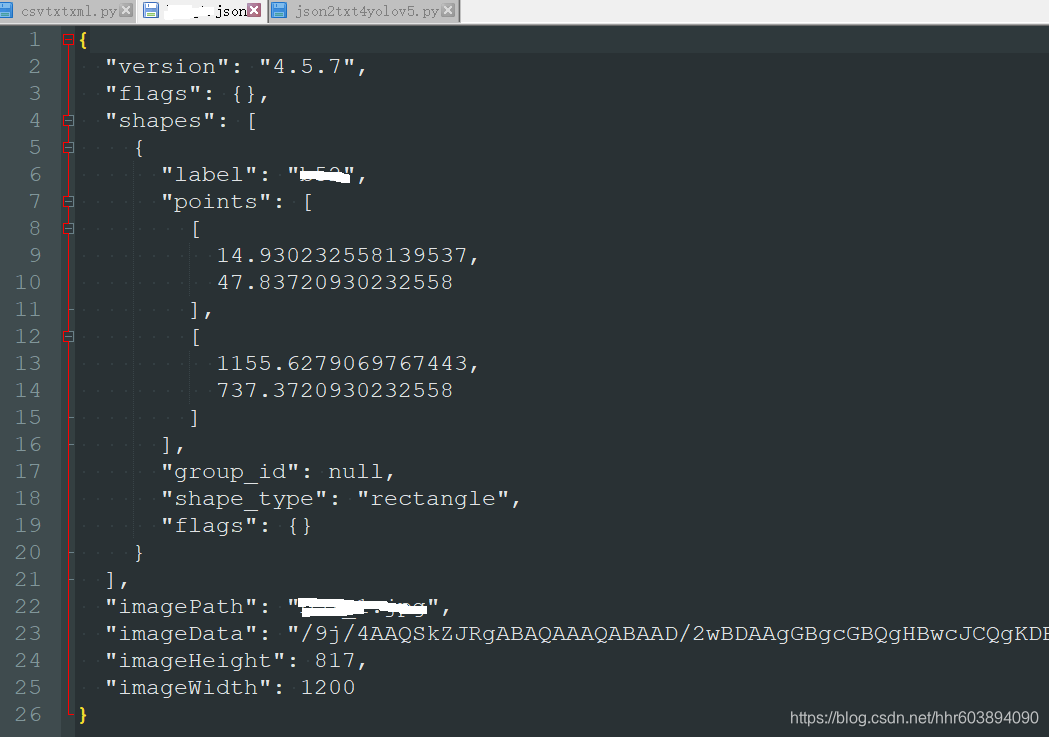
最常用的是矩形框标注 create rectangle,点击矩形对角的两个点,命名object label,然后save,保存为json格式文件,存在Annotations文件夹中,以备后用。内容示例图如下:
接下来就是大量的单调还带着繁琐的数据清洗和标注了,在用yolov5训练之前还需要把json转为其需要的txt文件格式,这个放在后续博客中。
参考文章: