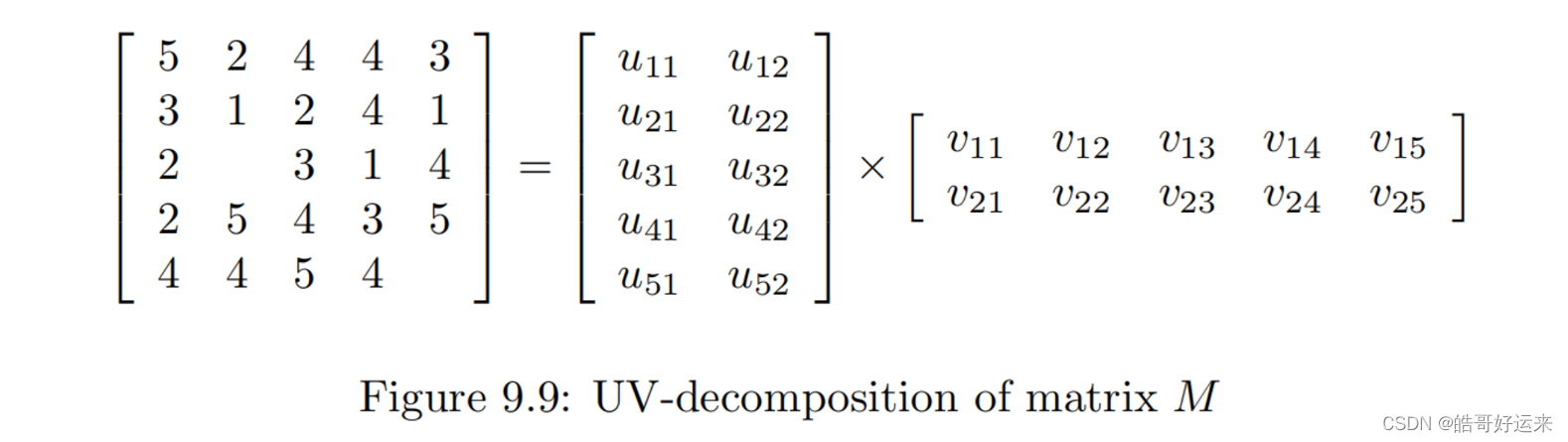
前言

今天,我们将采集某小说数据,通过这个案例,加深我们对正则表达式的理解。我们今天来通过使用正则表达式来获取我们想要的文本。
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独