翻页请求实现
继https://blog.csdn.net/ssslq/article/details/130747686之后,本篇详述在获取了页面第一页之后,如何获取剩余页的标题内容。
网页:https://books.toscrape.com
找规律
同样还是进行页面的检查,切到网络一栏,找到头部对应的URL。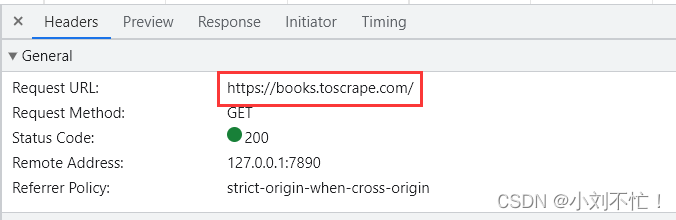
然后切到第二页,再去观察URL是否变化:
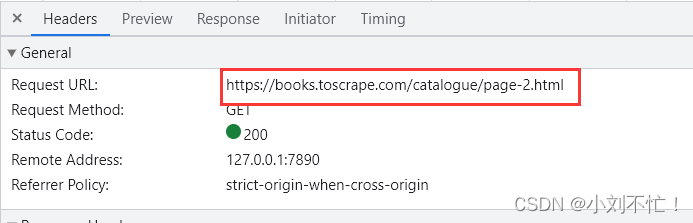
现在发现后面多了路径/catalogue/page-2.html,第二页对应了2.html,那么第一页是否是对应了1.html,试验一下:
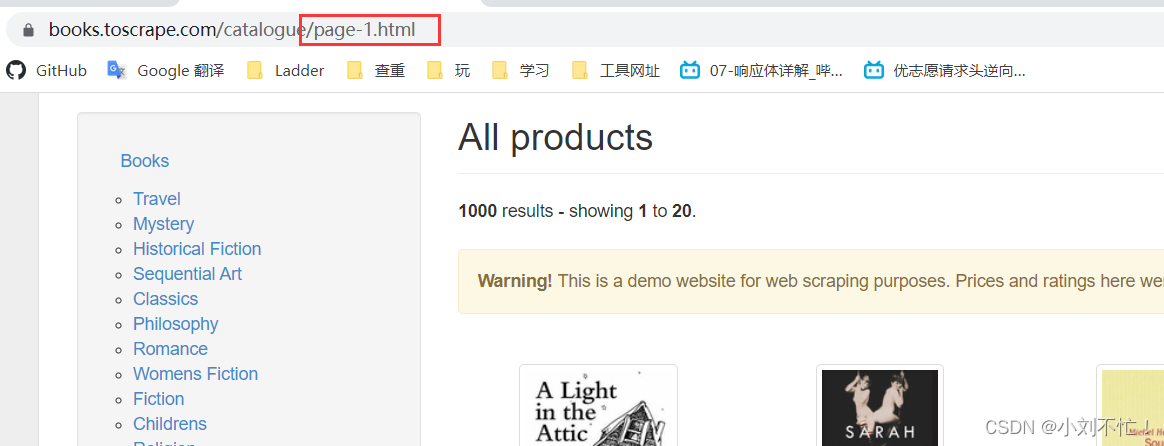
发现使用了1.html之后返回到了首页,也就是第一页,现在大概明白了,每一页都可以使用X.html进行访问。这个页面总共有50页可以进行选择,既然第一页的书名已经进行了输出,那如果要访问50页,那就需要使用循环进行输出。

仅第一页代码
from bs4 import BeautifulSoup
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}#请求头改成自己的
url = "https://books.toscrape.com/catalogue/page-1.html"
responce = requests.get(url,headers=headers).text
soup = BeautifulSoup(responce,"html.parser")
all_title = soup.findAll("h3")
for i in all_title:
title = i.find("a")
print(title.string)
加循环后的代码
from bs4 import BeautifulSoup
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}#请求头改成自己的
for j in range(1,51):
url = f"https://books.toscrape.com/catalogue/page-{j}.html"
responce = requests.get(url,headers=headers).text
soup = BeautifulSoup(responce,"html.parser")
all_title = soup.findAll("h3")
for i in all_title:
title = i.find("a")
print(title.string)
代码注释:
-
from bs4 import BeautifulSoup: 导入BeautifulSoup库,这是为了使用其中的解析和提取功能。 -
import requests: 导入requests库,这是为了发送HTTP请求获取网页内容。 -
headers = {...}: 定义了一个字典类型的变量headers,其中包含了请求头信息。这个请求头信息中设置了User-Agent字段,模拟浏览器发送请求。 -
for j in range(1,51):: 这是一个循环语句,从1到50循环遍历,用于处理多个页面。 -
url = f"https://books.toscrape.com/catalogue/page-{j}.html": 根据循环变量j的值构建每个页面的URL地址。f-string用于在字符串中插入变量的值。 -
response = requests.get(url, headers=headers).text: 发送HTTP GET请求到指定的URL,并获取响应对象。.text将响应内容以文本形式返回。将获取到的响应文本赋值给response变量。 -
soup = BeautifulSoup(response, "html.parser"): 使用BeautifulSoup库将获取到的响应文本进行解析,创建一个BeautifulSoup对象。传入参数response作为要解析的文档内容,以及解析器类型"html.parser"。 -
all_title = soup.findAll("h3"): 使用BeautifulSoup对象的findAll方法,查找所有<h3>标签,并将结果存储在变量all_title中。findAll返回一个列表,其中包含了所有匹配的标签。 -
for i in all_title:: 对于all_title列表中的每个元素进行迭代。 -
title = i.find("a"): 在当前迭代的<h3>标签中,使用find方法查找第一个<a>标签,并将结果存储在变量title中。 -
print(title.string): 打印title标签的文本内容,即书籍的标题。使用.string获取标签内的文本。
这段代码的作用是从多个页面中爬取书籍标题信息,并将其打印出来。通过循环遍历不同的页面,每个页面的URL地址中的页码部分会随着循环变量j的值而改变。代码使用requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析网页并提取所需信息。最后通过循环打印出每个页面中的书籍标题。
具体爬还要多实践,才能越来越熟练。