一、爬虫
1、定向爬虫
定向爬虫可行性太低,因为网站可能发生改版、且网站类型较多。
2、规律
考情分析大多是找到相关文档,所需要的数据的行为模式基本都是从列表页进–>文章页,而具体的文章就是在这里插入图片描述
我们需要的数据。如下面中公教育的网站提供的公告数据。

3、爬取策略
不针对某个特定的网站进行爬取,而是针对于所有数据源进行爬取。
以列表的形式列举出全国各省市区的公告信息网(或者就是现在的一千多条数据源)。
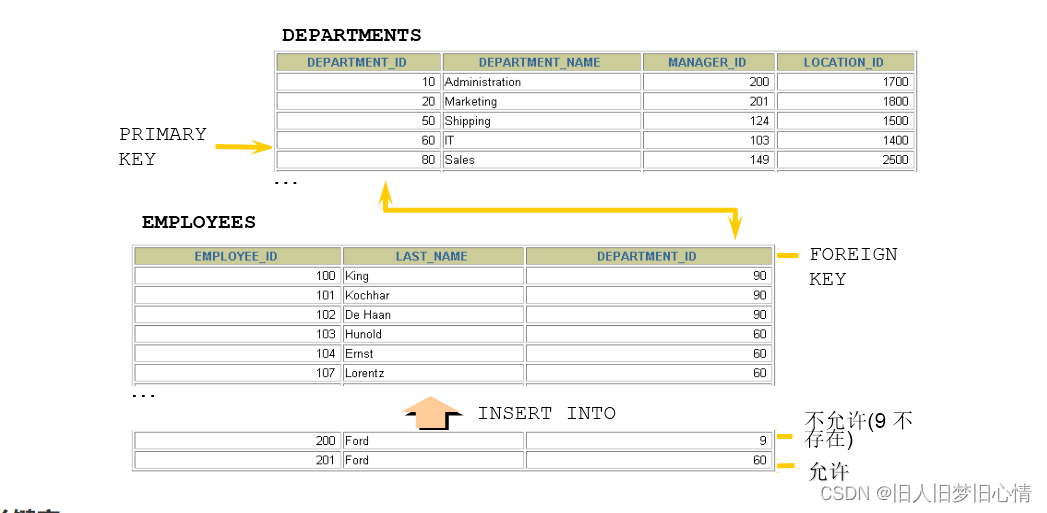
- 获取首页URL地址:公告官网列表中的每一个条目是通过模板for标签动态显示的,数据来源于数据源,该数据源中存储了每一个官网的名字和URL地址。
2.当确定建立某一个官网的词库后,查询id值对应的门户网站的首页地址,爬虫便从该地址开始爬取。 - 爬虫API获取网页信息:门户网站中有许多子网页,可以采用DFS和BFS来获取每一个子网页信息。在设置请求头后,使用request.get方法来抓取网页的标题、内容、URL等信息。
- 解析网页及分词:对于每一个子网页,在获取了页面的源码后,标题和内容是一起的,可以用BeautifulSoup来解析网页内容,解析出网页的标题和内容,随后使用Python的jieba中文分词库进行中文的分词,使连续的内容变成一个个单词。分词的结果可以放在list里面,后续可以使用,如考试时间的排序,考试内容的筛选等。
- 存入数据表:经过上述对网页信息的处理后,构建两张数据表。一个存储url、title等,另一个存储网页内容分词后的中文词语。
6.成功爬取多个网页后,数据得到汇总。
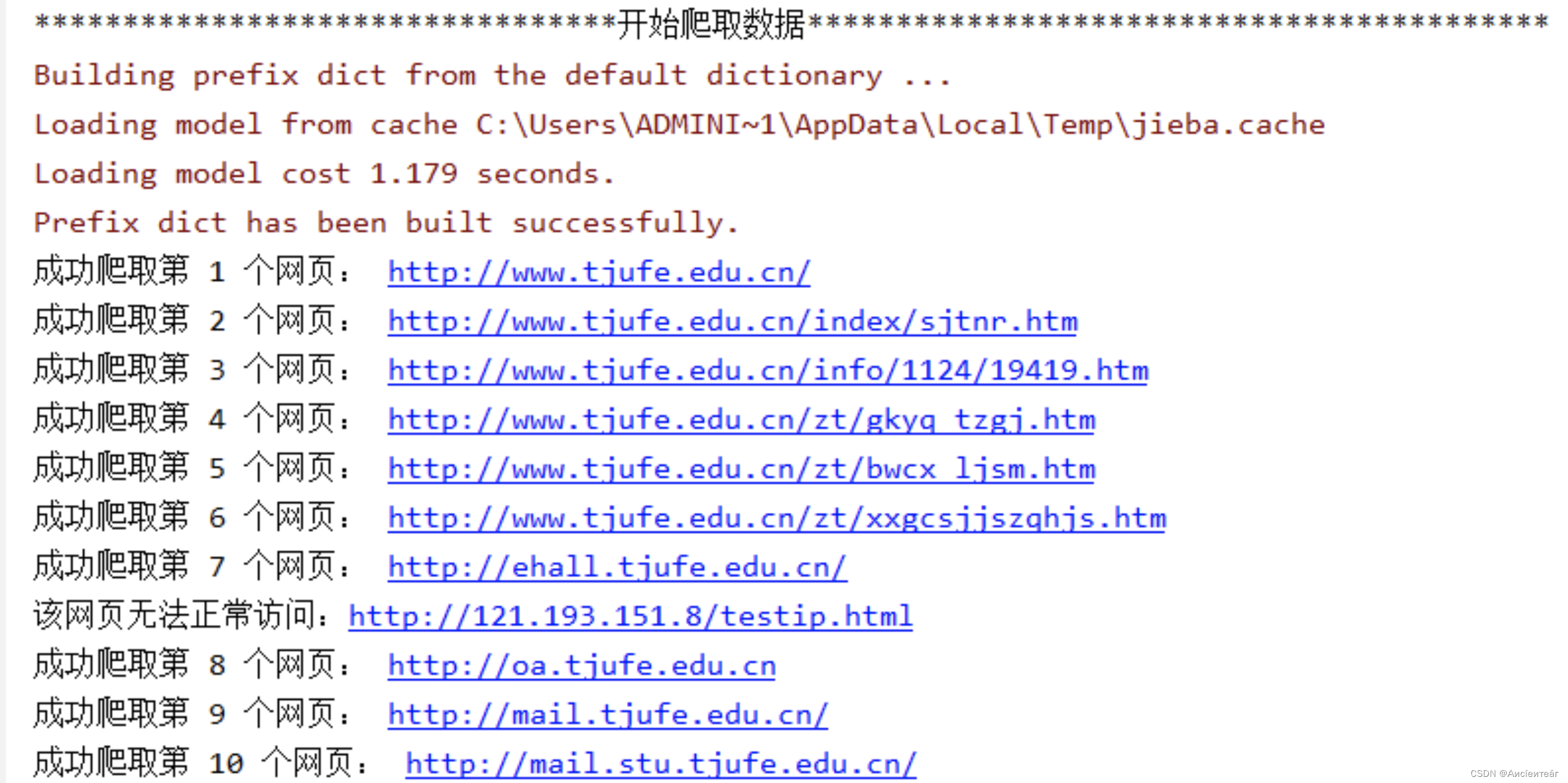
4、整页抓取
进入文章后,不是只抓取特定字段,而是整页抓取,后续进行相对应的文本提取和操作。
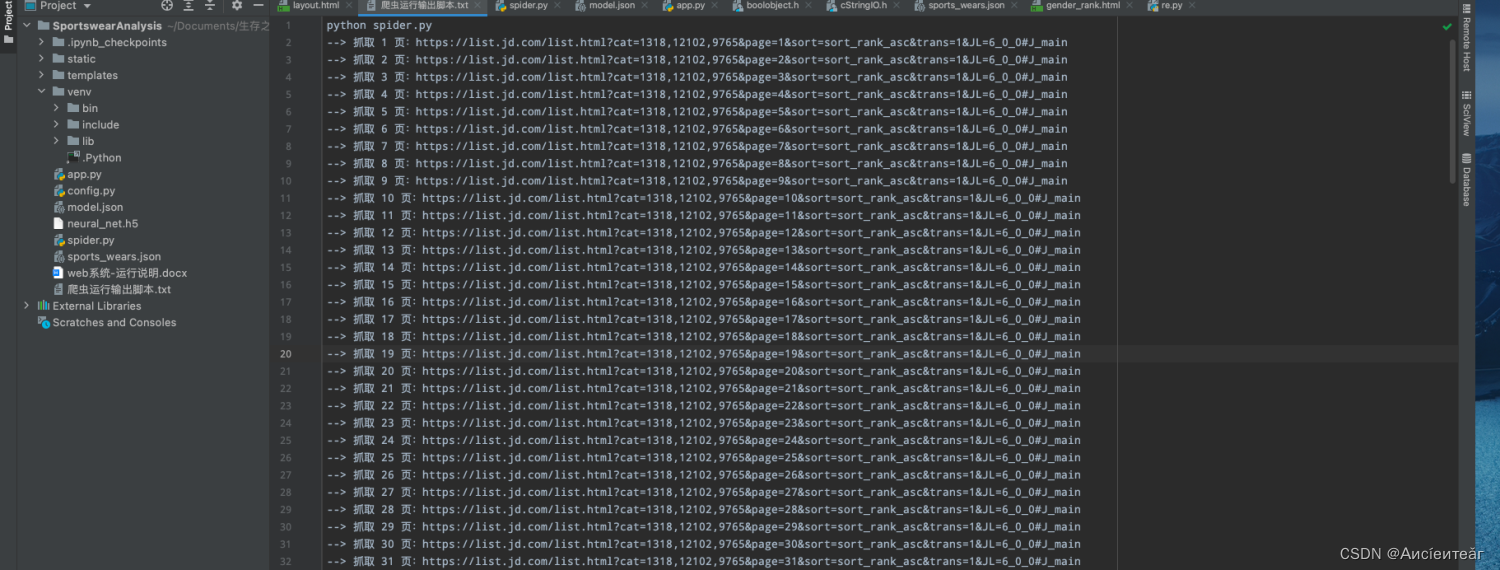
5、爬取方案
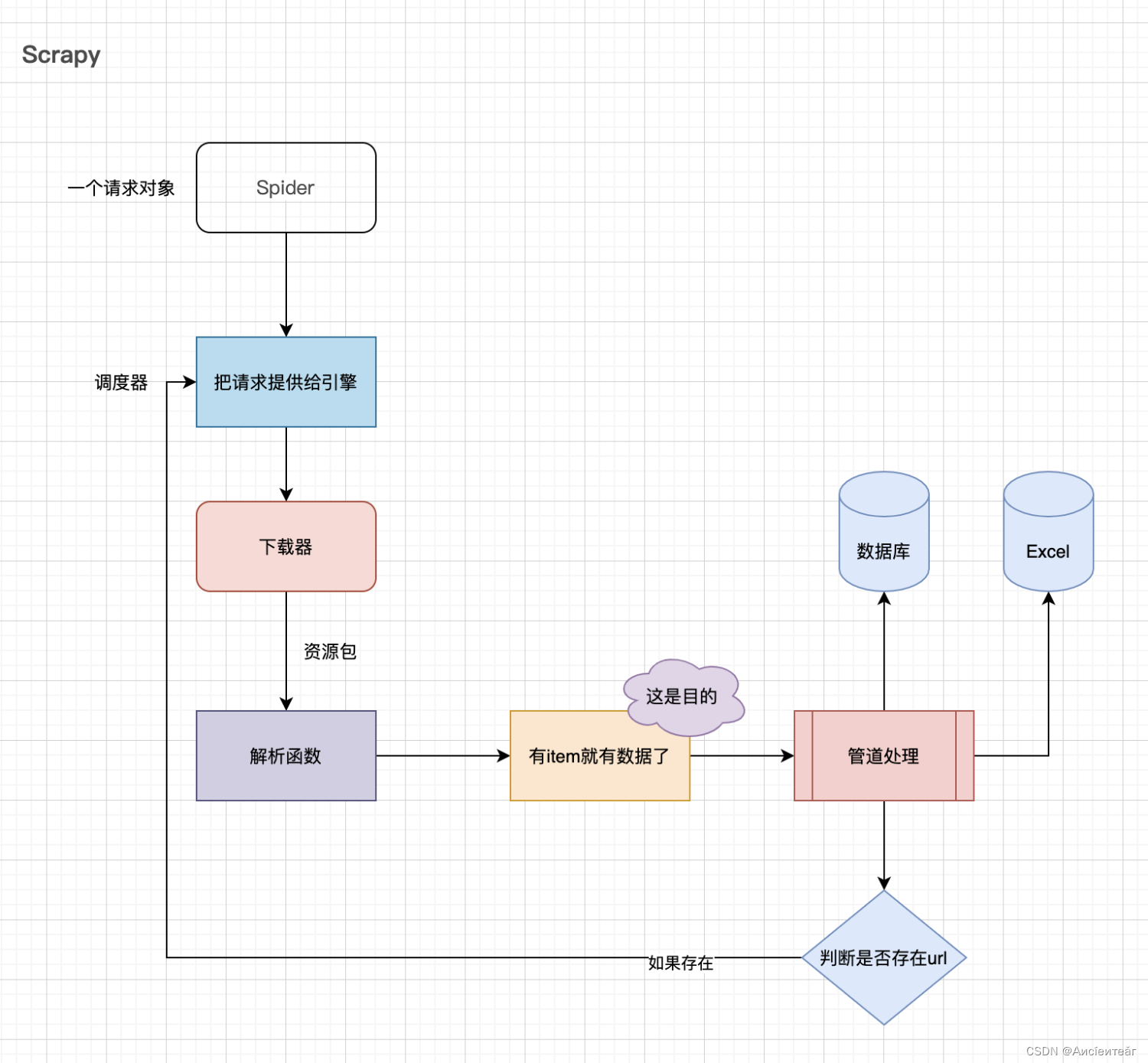
5.1 Scrapy
这里的调度器是个队列,出队后进入到下载器。
item就是想要的数据包。
如果管道处理后仍然有url,可以将其加入到队列,如广度优先搜索一样将相关页面都入队,入队后依次出队进入下载器。
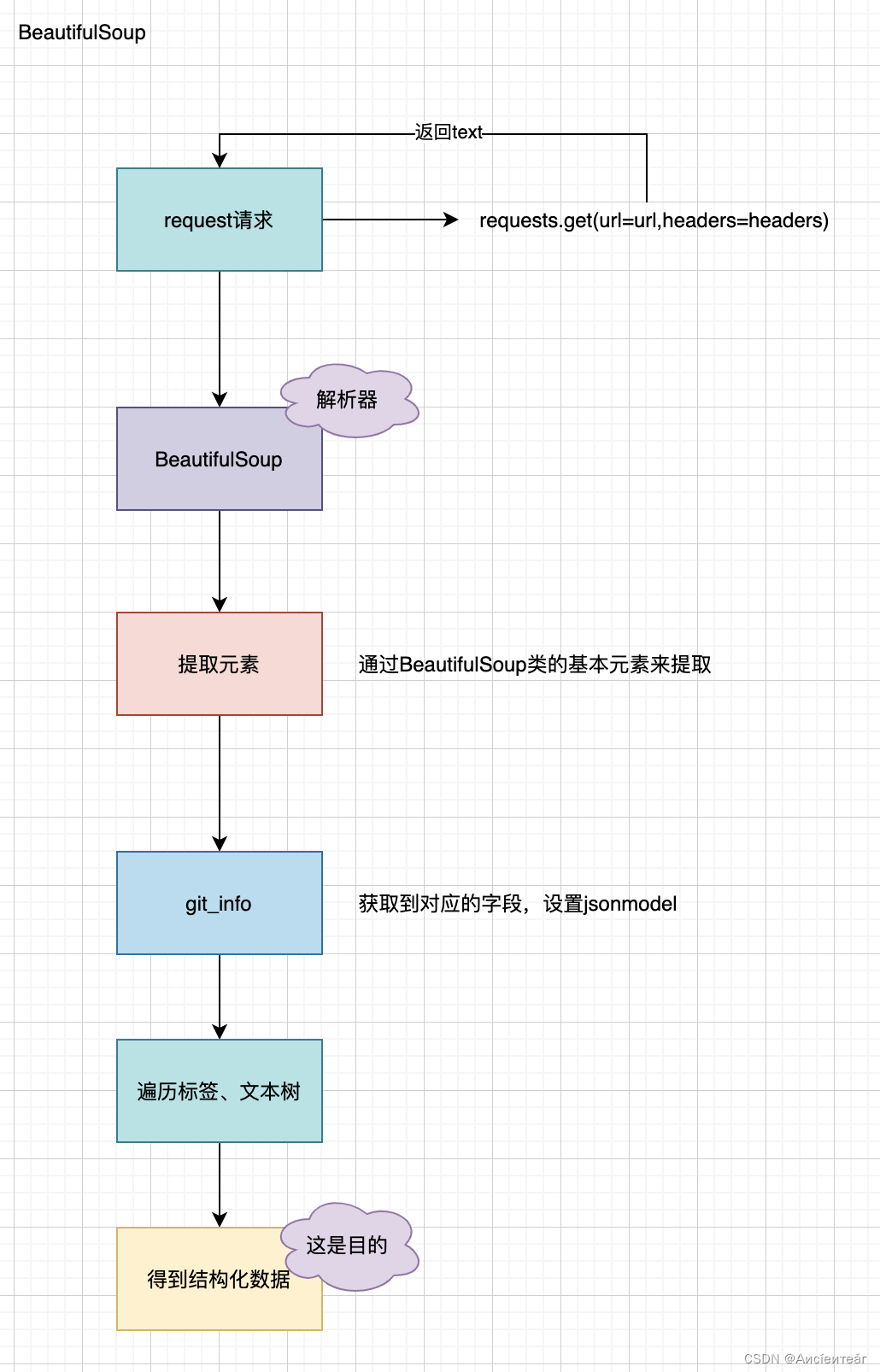
5.2 BeautifulSoup
这个三方主要是借助于BeautifulSoup来进行解析,其实里面就是一些属性,通过属性来进行获取,如name、content等信息,在获取信息的时候通过一些label或者是h1、h2等
二、文本提取
因为不确定最后需要的数据到底有什么,所以没有准确的定位。
如果是提取公告内部的信息,可以进行文本提取。可以使用xpath获取文本信息,也就是根据前端的文本格式来获取文字信息。思路是遍历内部的所有子标签并获取标签文本,最后拼接。
如果是获取报名时间等具体的内容,可以进行中文分词,分词后筛选出重要信息,根据重要信息去做别的事情。
三、问题
1.我想要通过数据了解什么?
2.类似于BOSS提供职位方便用户进行筛选,这个筛选是根据地区、考试时间,对考试公告进行筛查吗?
3.这个考情,指的是考试情况,还是考试情况分析。是只需要汇总考试时间、内容吗?还是说也会针对历年的考试情况如报考人数和录取比例进行职位的推荐?
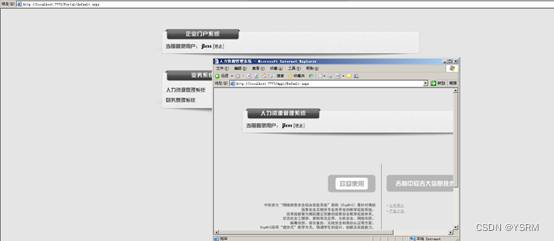
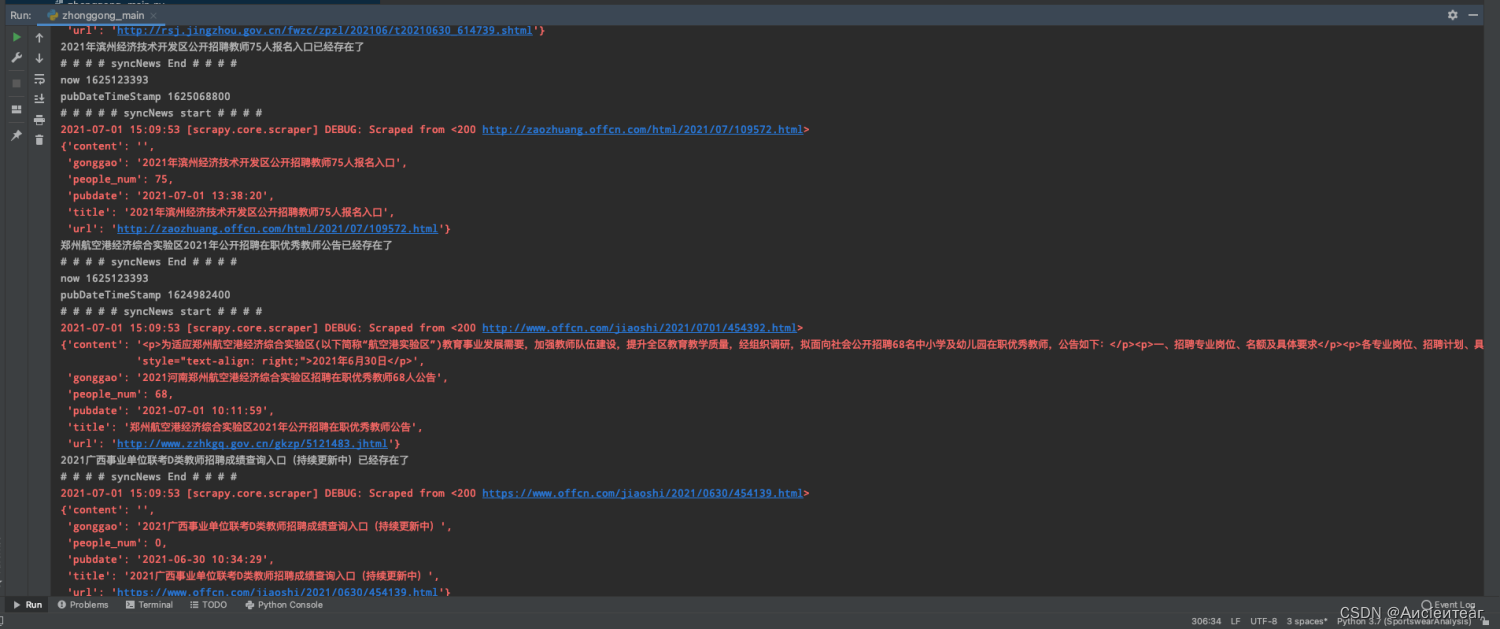
4.目前对中公教育网站,爬虫内容主要是有:该考试公告的更新时间、名字、标题、公告链接等,如下图所示,并没有具体考试数据的提取(如考试时间和考试科目等),是否满足现在的需求?
四、数据源建模调研
背景:考情主要依赖于平台和模型外部数据源,不同的门户网站间的算法是不统一的。如果每个数据源都依赖于一个模型,那么时间成本太高。考虑动态模型融合,按照标准化和加权融合的搭配一个统一的模型。
方案:基于现有数据源,找几个典型的数据源,构建模型,看模型可以被哪些数据源所覆盖。
具体:
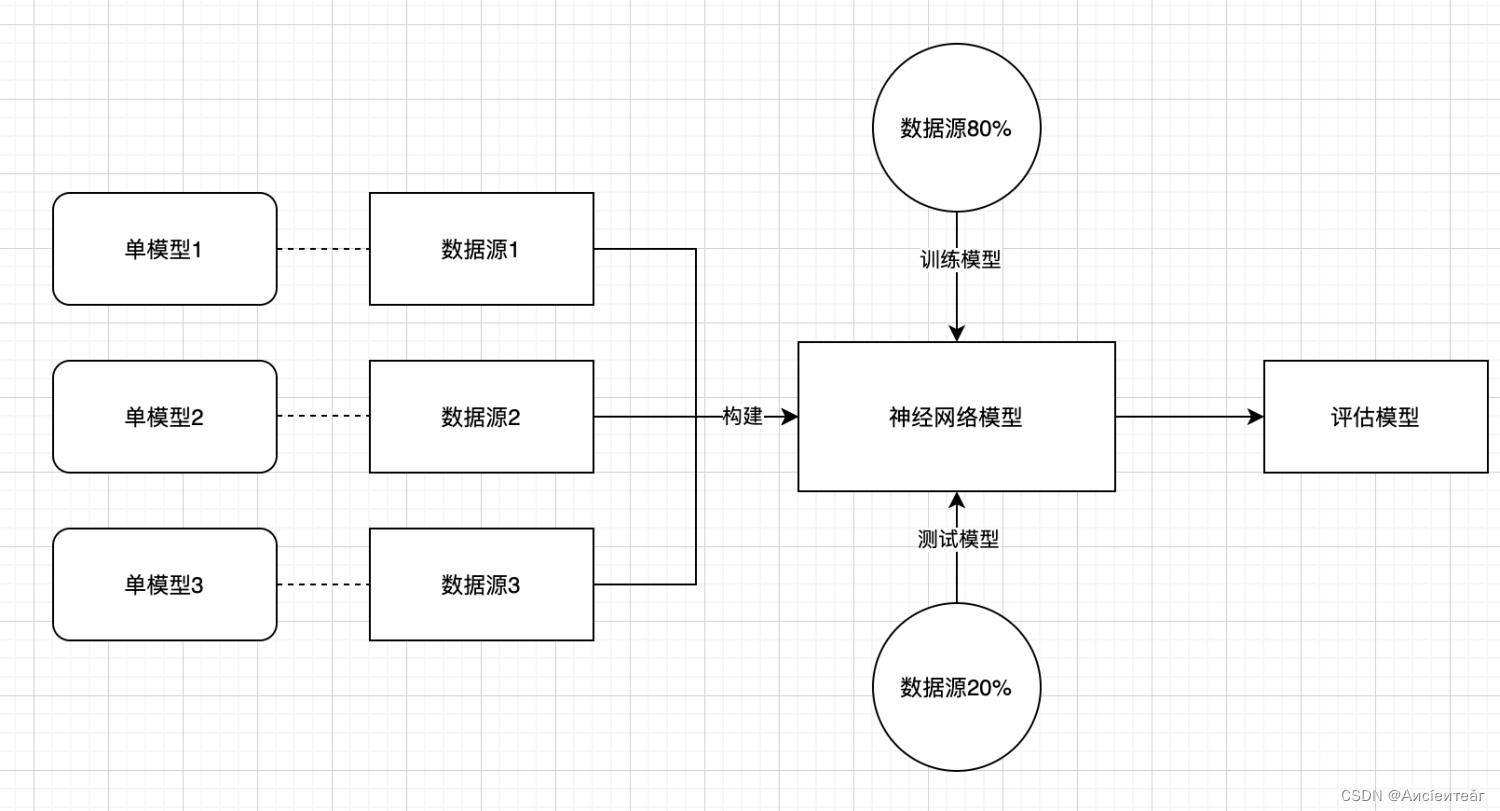
1、每种数据源一个单模型。
2、对多模型,进行训练,通过机器学习,训练模型,来多元化适配不同的数据源,在不断的数据源加入的过程中,模型会越来越准确。
3、对模型,可以参考某种权重进行标准化。
暂时不确定可行性。后续需进一步了解。
感觉应该是这个意思: