前言

大家好,今天我们来给大家分享一个很实用的东西。最近,有粉丝私信我,能不能做一个大学习自动核对名单的程序,我这个粉丝呢,她作为班级团支书,每次核对大学习的名单感到特别的头疼。那我接下来就来写一个能够自动核对大学习名单的小程序。
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
- os
os 就是 “operating system” 的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。
- csv
它是一种文件格式,一般也被叫做逗号分隔值文件,可以使用 Excel 软件或者文本文档打开 。其中数据字段用半角逗号间隔(也可以使用其它字符),使用 Excel 打开时,逗号会被转换为分隔符。csv 文件是以纯文本形式存储了表格数据,并且在兼容各个操作系统。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
python"> 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
想法和思路
编写程序:
我们可以编写一个程序,用于帮助我们核对qn大学习学习名单。这个程序可以根据我们输入的学习名单,自动检查名单中的每个人是否已经完成了学习任务。我们可以使用编程语言(如Python)来编写这个程序。
但是,我们发现这个方法太麻烦,这个和我一个一个对比,有什么区别呢。我就想到了直接构建列表就好了啊。省时省力。
功能实现
我们首先,我们爬取班级学习的名单,然后,和班级所有同学的名单做对比,程序自动输出未完成青年大学习的名单,如何操作,看我一步一步的操作。
获取大学习期数
我们这里获取大学习的期数,我们就可以不用修改table_name的值了,我们这里默认的是最新一期的大学习。
python">url = 'http://dxx.ahyouth.org.cn/api/peopleRankList?level1=%E7%9B%B4%E5%B1%9E%E9%AB%98%E6%A0%A1'
url_res = requests.get(url)
name = url_res.json()['list'][0]['name']
table_name = url_res.json()['list'][0]['table_name']
print("你正在查询",name,"青年大学习\n")
运行我们的程序,今天是第10期的大学习,说明,我们的程序没有问题的,我们继续往下走。
你正在查询 2023年 - 第10期 大学习
获取名单
接下来,就是最重要的一步,构建下面的地址。找到自己班级大学习的名单的地址,大家会使用开发者工具的话直接找到下面的地址,不会使用也没有关系,我们可以直接修改下面level后面的值。
python">url = 'http://dxx.ahyouth.org.cn/api/peopleRankStage'
data = {
'table_name': table_name,
'level1': '直属高校',
'level2': '某某大学',
'level3': '数理学院',
'level4': '数学类2101',
}
res = requests.get(url, params=data)level1是直属高校,我们这里可以不用修改。
level2是大家学校的名字,大家填自己学校的名字就好。

level3是大家学院的名字,大家填自己学院的名字就好。我们这里以安庆师范大学为例,大家需要注意的是,填写名字要和我们看到的名字一模一样。尤其是班级的名字。后面,就不过多赘述。
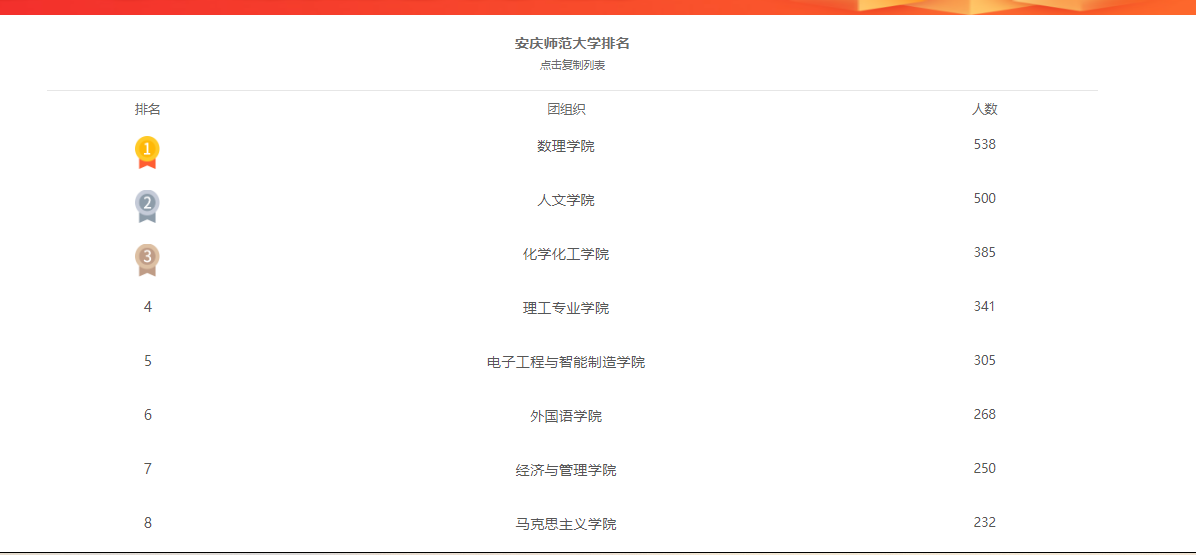
level4是大家班级的名字,大家填自己班级的名字就好。

我们接下来以"数学类2101"为例,讲解后面的代码。我们这里调用 requests 库中的 get() 方法,传入这个 URL 和 data 字典,可以获取服务器返回的结果。这个结果是一个字典,其中包含了查询的结果,就是学习的名单。
我们发现返回res.text就会乱码,我们可以转码,或者直接json解决。
python">html_lists = res.json()['list']['list']这段代码把 res.json() 返回的是一个包含多个字典的列表,每个字典代表一个用户的信息。['list']['list'] 表示字典中的第一个键对应的列表,即用户的名字和学习时间。
我们看看效果:
 名单对比
名单对比
接下来,也就是我们最重要的环节,对比我们的名单。
我们接着看看后面的程序:
python">
for html_list in html_lists:
username = html_list['username']
yixue_list.append(username)我们接下来循环处理 html_lists 列表中的每个字典,获取其中的 username 键,将其添加到 yixue_list 列表中。这样,循环结束后,yixue_list 列表中就包含了班级所有学习了大学习的名字。
python">weixue_list = list(set(list_all) - set(yixue_list))
if not weixue_list:
print("全部完成青年大学习")
else:
print("未完成的名单如下\n", weixue_list)我们这段代码使用了 Python 的集合(set)和列表(list)操作。
首先,它使用 set 将所有用户的名字转换为集合,去除了重复的名字。然后,它使用 set 将 yixue_list 中的名字转换为集合,再使用 set 将两个集合的差转换为新的集合。
接着,它检查新集合是否为空,如果为空,则说明所有用户都已经完成了大学习,程序输出一条消息。否则,它输出未完成青年大学习同学的名单,并将其打印出来。
我们这里把我们班级所有同学的名字都放到一个list_all列表里面。到这里,我们的功能就实现了。
python">list_all = ['张三', '李四', '王二麻子']效果
到这里,我们的程序就实现了,回头,我把程序封装一下,大家就可以直接使用了。

我们把py程序封装成exe文件,我们看看运行效果吧。

完整代码
下面我把完整的代码放在下面,大家有什么不懂的可以在评论区留言。
python">import requests
yixue_list = []
list_all = ['张三', '李四', '王二麻子']# 班级同学名单
url = 'http://dxx.ahyouth.org.cn/api/peopleRankList?level1=%E7%9B%B4%E5%B1%9E%E9%AB%98%E6%A0%A1'
url_res = requests.get(url)
name = url_res.json()['list'][0]['name']
table_name = url_res.json()['list'][0]['table_name']
print("你正在查询", name, "青年大学习\n")
url = 'http://dxx.ahyouth.org.cn/api/peopleRankStage'
data = {
'table_name': table_name,
'level1': '直属高校',
'level2': '学校名字',
'level3': '学院名字',
'level4': '班级名字',
}
res = requests.get(url, params=data)
html_lists = res.json()['list']['list']
print(html_lists)
for html_list in html_lists:
username = html_list['username']
yixue_list.append(username)
weixue_list = list(set(list_all) - set(yixue_list))
if not weixue_list:
print("全部完成青年大学习")
else:
print(len(weixue_list))
print("未完成的名单如下\n", weixue_list)