目录
- 1. 什么是re解析
- 2. 正则规则
- 元字符
- 量词
- 匹配模式测试
- 3. 正则案例
- 4. re模块的使用
- 4.1 findall: 匹配字符串中所有的符合正则的内容
- 4.2 finditer: 匹配字符串中所有的内容[返回的是迭代器]
- 4.3 search, 找到一个结果就返回, 返回的结果是match对象
- 4.4 match 从头开始匹配,必须把10086放在待匹配的字符串开头才能匹配成功
- 4.5 compile 预加载正则表达式
- 4.6 (?P<变量名>匹配规则)
- 5. 综合实战
- 总结
1. 什么是re解析
Regular Expression, 正则表达式, ⼀种使⽤表达式的⽅式对字符串,进⾏匹配的语法规则(按照一定规则的查找)
⽹⻚源代码本质上就是⼀个超⻓的字符串, 用正则就好像是在我们的txt中查找指定内容一样。
正则的优点:速度快, 效率⾼, 准确性⾼
正则的缺点:难度⾼
2. 正则规则
元字符
元字符: 具有固定含义的特殊符号 常⽤元字符
python">1 . 匹配除换⾏符以外的任意字符
2 \w 匹配字⺟或数字或下划线
3 \s 匹配任意的空⽩符
4 \d 匹配数字
5 \n 匹配⼀个换⾏符
6 \t 匹配⼀个制表符
7
8 ^ 匹配字符串的开始
9 $ 匹配字符串的结尾
10
11 \W 匹配⾮字⺟或数字或下划线
12 \D 匹配⾮数字
13 \S 匹配⾮空⽩符
14 a|b 匹配字符a或字符b
15 () 匹配括号内的表达式,也表示⼀个组
16 [...] 匹配字符组中的字符
17 [^...] 匹配除了字符组中字符的所有字符
量词
python">1 * 重复零次或更多次
2 + 重复⼀次或更多次
3 ? 重复零次或⼀次
4 {n} 重复n次
5 {n,} 重复n次或更多次
6 {n,m} 重复n到m次
匹配模式测试
| 符号 | 意义 |
|---|---|
| .* | 惰性匹配 |
| .*? | 贪婪匹配 |
爬⾍⽤的最多的就是这个惰性匹配.,就是尽可能减少所搜索到的目标(搜索会更加精确,用到了回溯的思想)
3. 正则案例
正则在线测试网站:https://tool.oschina.net/regex/
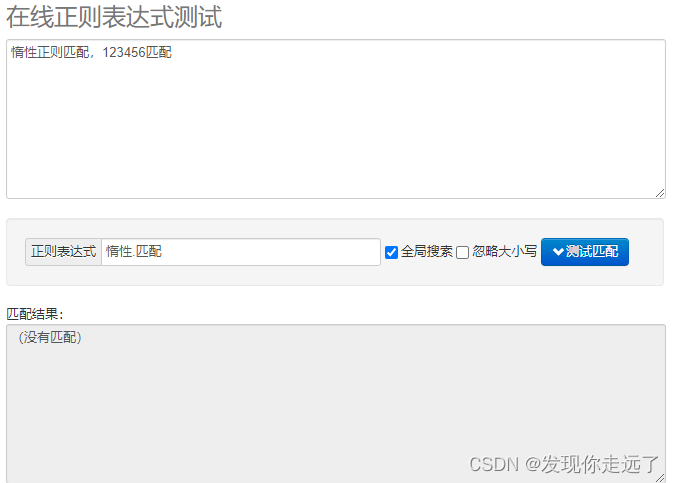
- 案例1:
待匹配文本:
python">惰性正则匹配,123456匹配
匹配规则匹配的内容–>惰性(任意一个字符)匹配
python">惰性.匹配
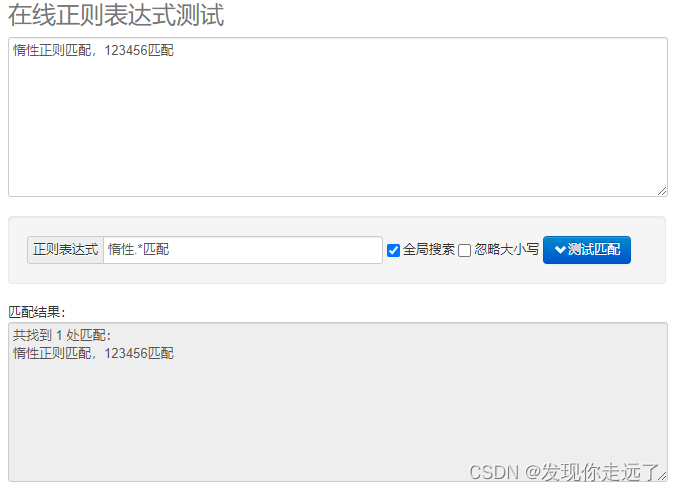
- 案例2
待匹配文本:
python">惰性正则匹配,123456匹配
匹配规则匹配的内容–>惰性(任意多个个字符)匹配
python">惰性.*匹配
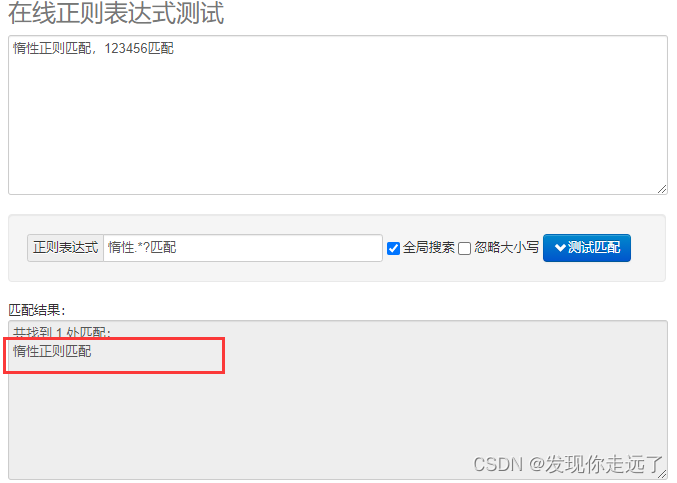
- 案例3
待匹配文本:
python">惰性正则匹配,123456匹配
匹配规则匹配的内容–>惰性(任意多个个字符)匹配,要求找到最小范围的匹配项
python">惰性.*?匹配
原理在于第一步找到了案例2中的 惰性正则匹配,123456匹配字符串之后继续对这个字符串回溯,查看这个字符串中是否能够再找到更小单位的匹配对象,只返回最小长度的匹配对象。
4. re模块的使用
匹配规则解释: “\d” 表示匹配数字 “+” 表示1个或多个
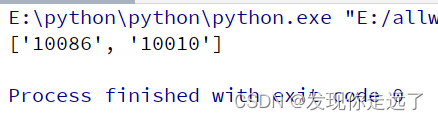
4.1 findall: 匹配字符串中所有的符合正则的内容
返回值是列表
python">import re
lst = re.findall(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
# 也就是匹配所有数字串
print(lst)
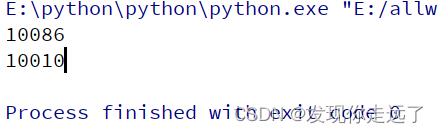
4.2 finditer: 匹配字符串中所有的内容[返回的是迭代器]
从迭代器中拿到内容需要.group()
python">import re
it = re.finditer(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
for i in it:#迭代器for循环输出
print(i.group())
4.3 search, 找到一个结果就返回, 返回的结果是match对象
拿数据需要.group(),匹配失败返回None
python">import re
s = re.search(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
print(s.group())
4.4 match 从头开始匹配,必须把10086放在待匹配的字符串开头才能匹配成功
真正意义上的从头开始,从待匹配文本的0位字符开始匹配,一般用的不多,功能不如search强大。
python">import re
s = re.match(r"\d+", "10086, 我女朋友的电话是:10010")
print(s.group())#10086
s = re.match(r"\d+", "我女朋友的电话是:10010,10086")
print(s)#None

4.5 compile 预加载正则表达式
预先定义一个正则的对象,后面只需要调用对象的方法就好了,不用每次都写一遍正则表达式,节省资源,提高效率
python">import re
# 预加载正则表达式
obj = re.compile(r"\d+")
#预先定义一个正则的对象,后面只需要调用对象的方法就好了,
# 不用每次都写一遍正则表达式,节省资源,提高效率
ret = obj.finditer("qwer233qwer566")
for it in ret:
print(it.group())
ret = obj.findall("qwer233qwer899")
print(ret)
4.6 (?P<变量名>匹配规则)
(?P<变量名>匹配规则) 表示把符合这个匹配规则的内容存入对应变量名
python">import re
obj = re.compile(r"(?P<number>\d+)")# number的值就是匹配得到的数字
ret = obj.finditer("qwer233qwer566")
for it in ret:
print(it.group("number"))
5. 综合实战
python">import re
s = """
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思哲</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
# (?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>", re.S) # re.S: 让.能匹配换行符
result = obj.finditer(s)
for it in result:
print(it.group("id")+"->"+it.group("name"))

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1