网络爬虫—Scrapy实战演示
- Scrapy Shell简介
- 进入shell调试网站
- 启动Scrapy Shell
- 查看目标网站
- 获取网站源代码
- 常用方法
- 调试xpath
- 提取数据
- Scrapy请求子页面
- 请求及返回处理
- 创建项目
- 创建爬虫
- 数据解析
- 写入csv文件
- 后记
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🧾 🧾第十六篇文章《网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
🎁🎁《Python网络爬虫》专栏累计发表十七篇文章,上榜七篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
Scrapy Shell简介
🧾 🧾Scrapy是一个开源的Python框架,用于快速、高效地爬取网站数据。Scrapy提供了一组功能强大的工具和组件,使开发人员可以轻松地从网站上提取所需的数据。
🧾 🧾Scrapy Shell是一个命令行工具,可以让开发人员交互式地调试和探索网站。使用Scrapy Shell,开发人员可以轻松地测试Web爬虫并查看网站上的数据。
🧾 以下是Scrapy Shell的一些主要特点:
-
轻松进入交互式Shell:只需输入“scrapy shell”命令即可进入交互式Shell。
-
可以直接访问网站并查看HTML源代码:使用Scrapy Shell,您可以直接访问网站并查看其HTML源代码。这使您可以轻松地查找要提取的数据的位置。
-
支持XPath选择器和CSS选择器:在Scrapy Shell中,您可以使用XPath或CSS选择器快速选择和提取所需的数据。
-
可以在Scrapy Shell中测试爬虫:使用Scrapy Shell,您可以测试和调试Web爬虫,以确保其能够正确提取所需的数据。
-
支持调用各种Python函数和库:在Scrapy Shell中,您可以轻松调用各种Python函数和库,以进一步处理所提取的数据。
Scrapy Shell是一个非常强大的工具,可以帮助开发人员快速而方便地开发和调试Web爬虫,提取所需的数据。
进入shell调试网站
启动Scrapy Shell
🧾 🧾打开命令行终端,并进入一个Scrapy项目根目录,输入以下命令启动Scrapy Shell:
scrapy shell url
🎯这里以百度为例:
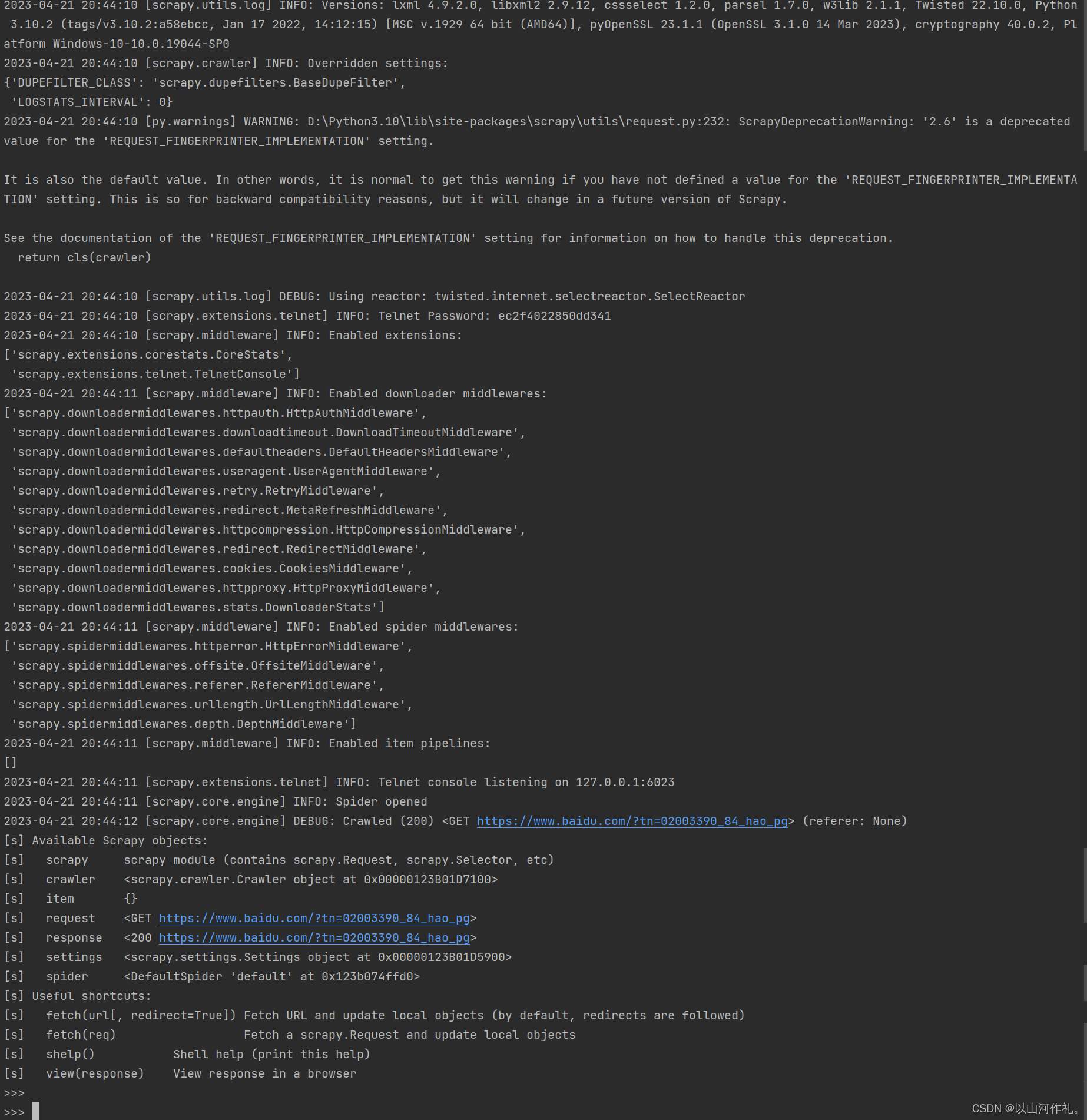
scrapy shell https://www.baidu.com/?tn=02003390_84_hao_pg&
🎯运行结果:
查看目标网站
🧾 🧾使用Scrapy Shell可以查看目标网站的内容,具体步骤如下:
- 打开命令行终端,在命令行中键入以下命令开始进入Scrapy Shell:
scrapy shell <url> 其中,`<url>`是目标网站的网址。
- 等待一段时间,直到Scrapy Shell加载完毕,显示下面的信息:
In [1]:
- 在Scrapy Shell中输入以下命令,获取目标网站的内容:
response.body
- 输入以下命令可以查看HTTP头信息:
response.headers
- 输入以下命令可以查看目标网页的标题:
response.xpath('//title/text()').get()
- 如需退出Scrapy Shell,请输入以下命令:
exit()
view(response)

获取网站源代码
response.body

常用方法
🧾 🧾输入response. 在这个时候按下键盘上的Tab键就可以实现参数选择
response.url # 当前响应的url地址
response.request.url # 当前响应对应的请求的url地址
response.text # html字符串,str类型
response.body # 广义上二进制的响应,bytes类型,相当于是response.content
response.body.decode() # 对bytes类型的字符串进行解码,将其变为str类型,相当于是response.content.decode()
response.xpath() # 调试我们的xpath表达式写地是否正确
response.xpath('//ul[@class="clears"]/li/div[@class="main_mask"]/h2[1]/text()').extract()
response.headers # 响应头
response.request.headers # 当前响应的请求头
调试xpath
🎯先将文本打印出来
response.text
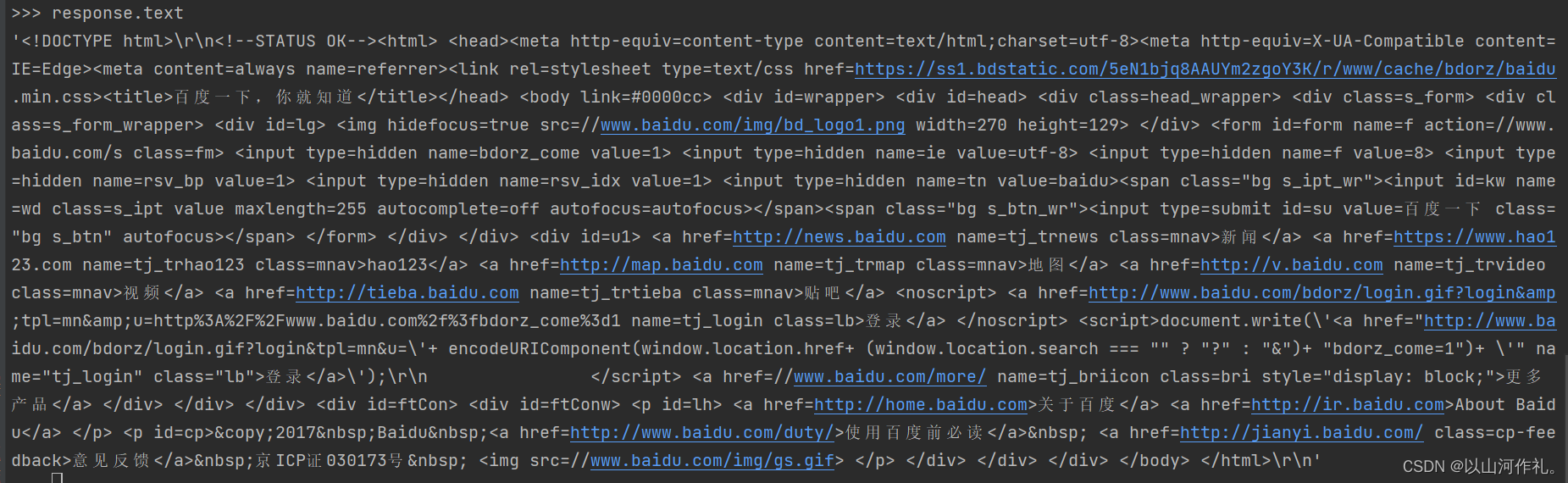
response.xpath('/html/head/title/text()')

提取数据
response.xpath('/html/head/title/text()').extract()

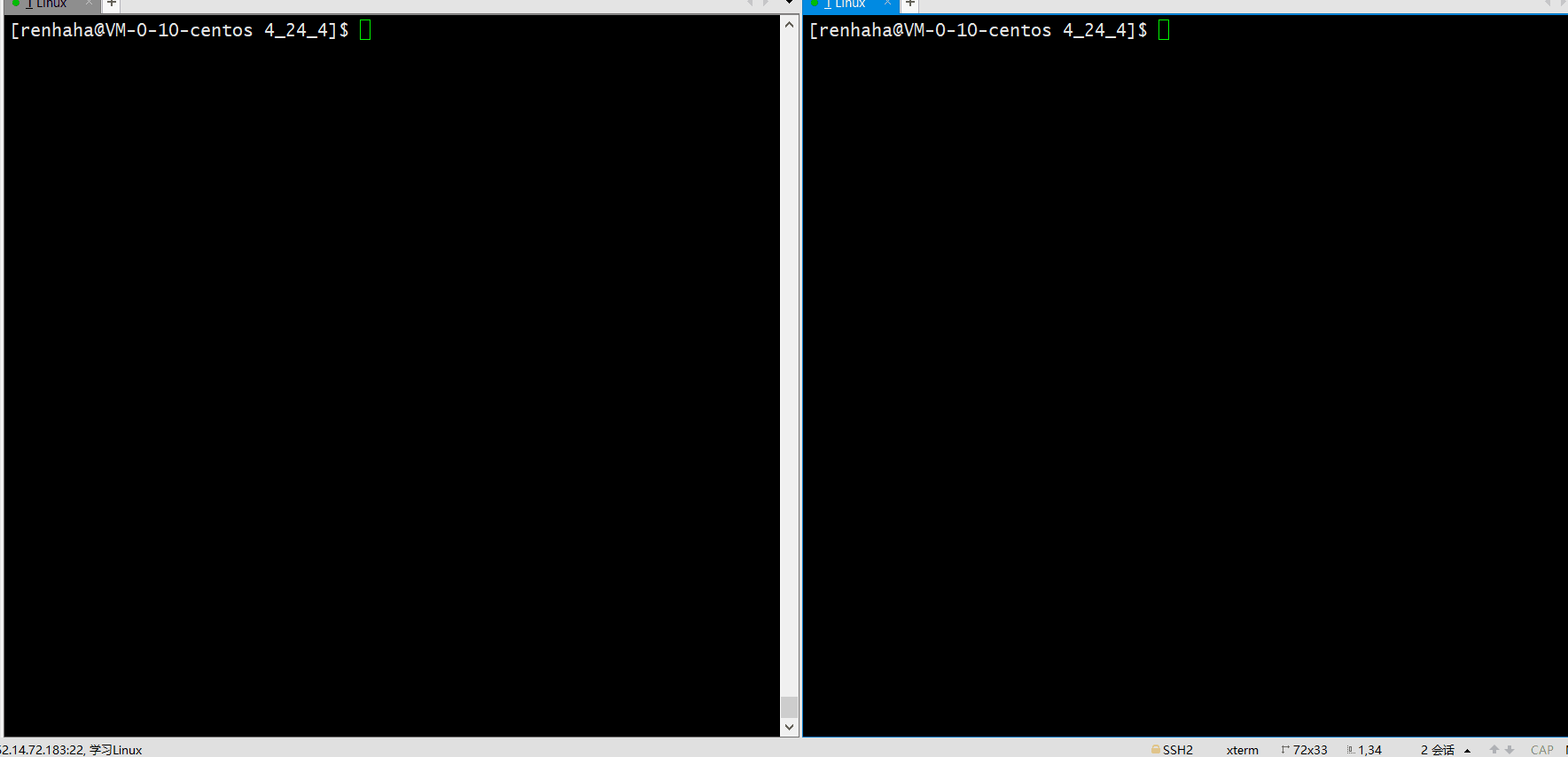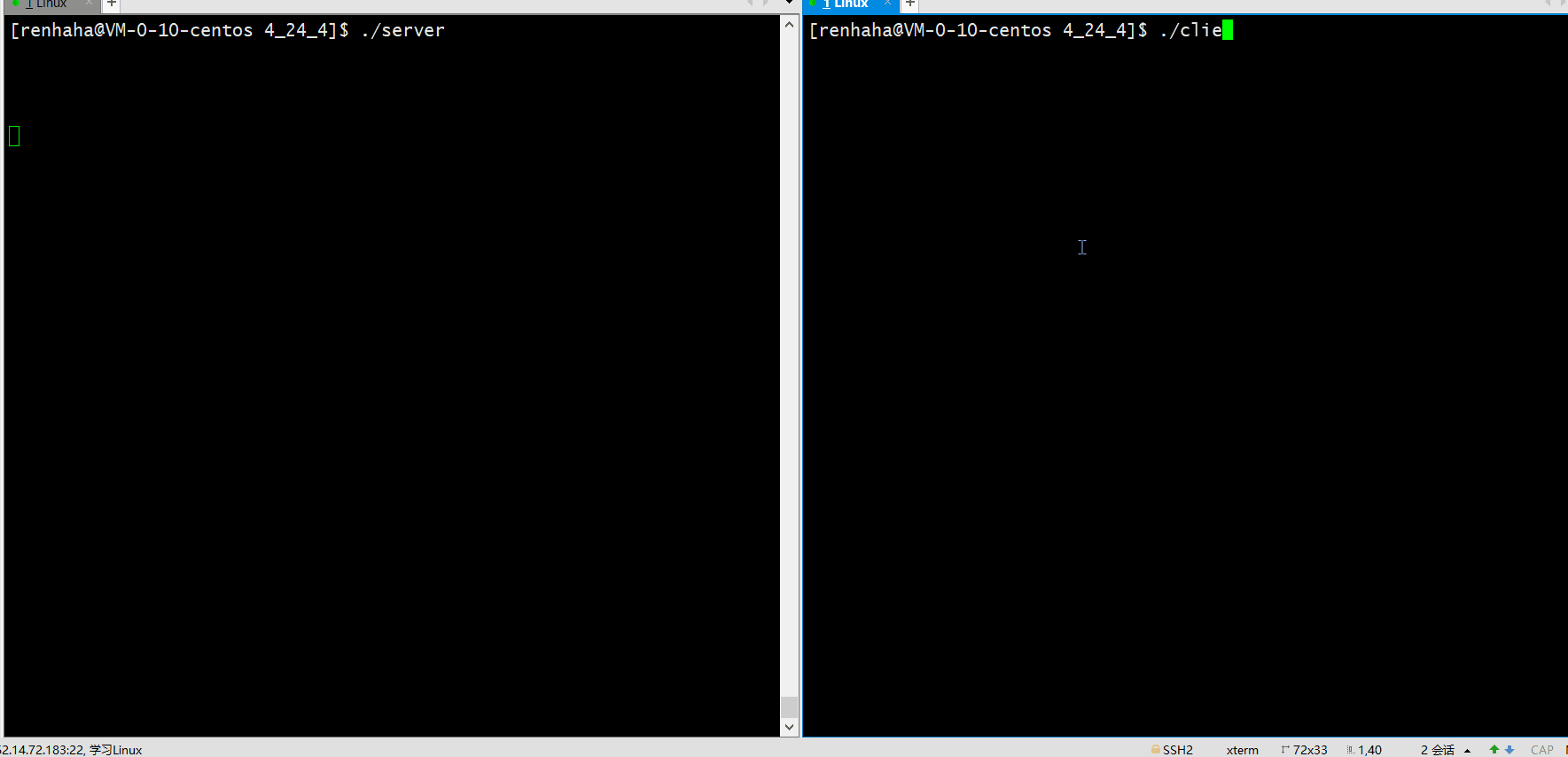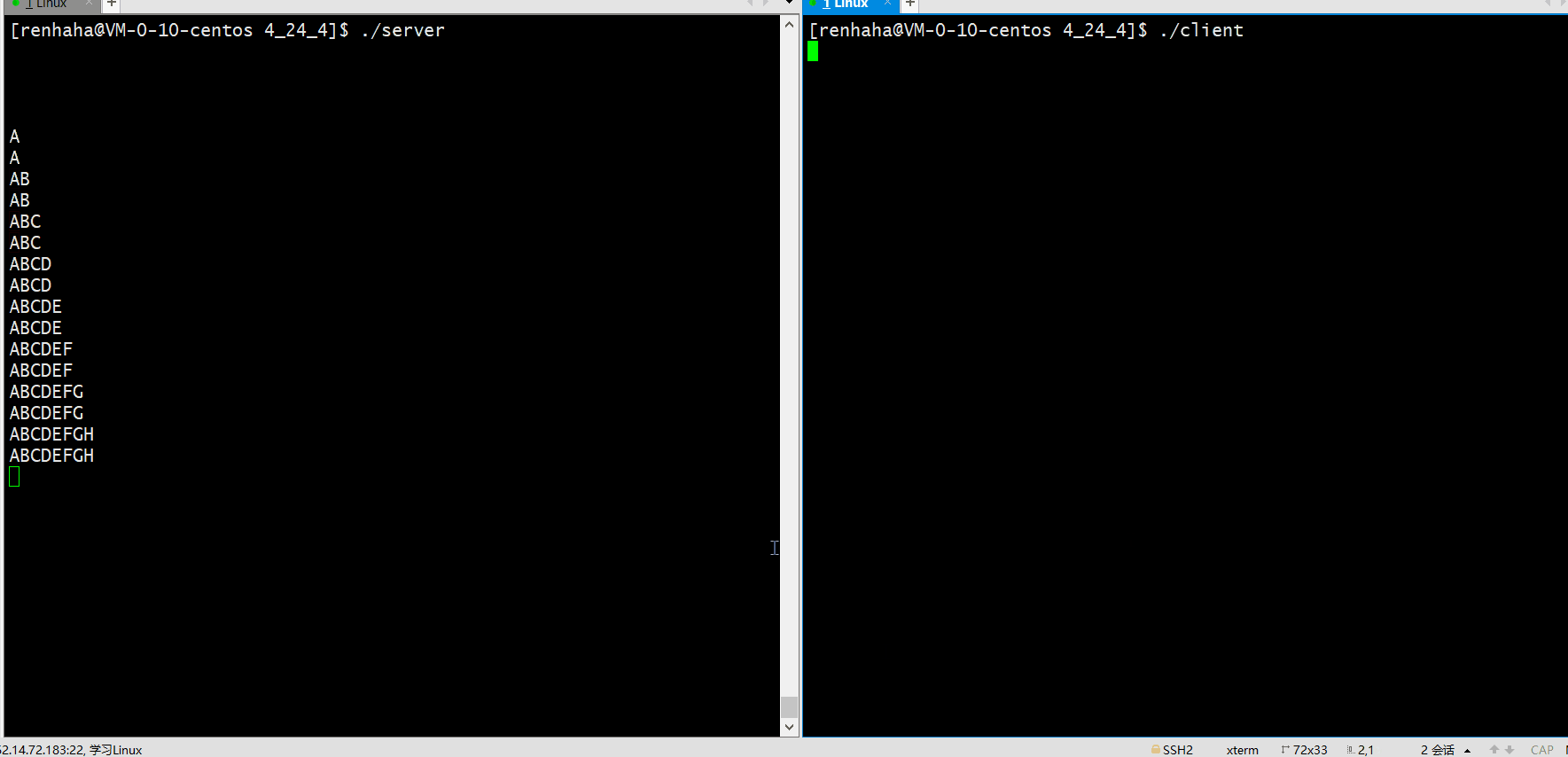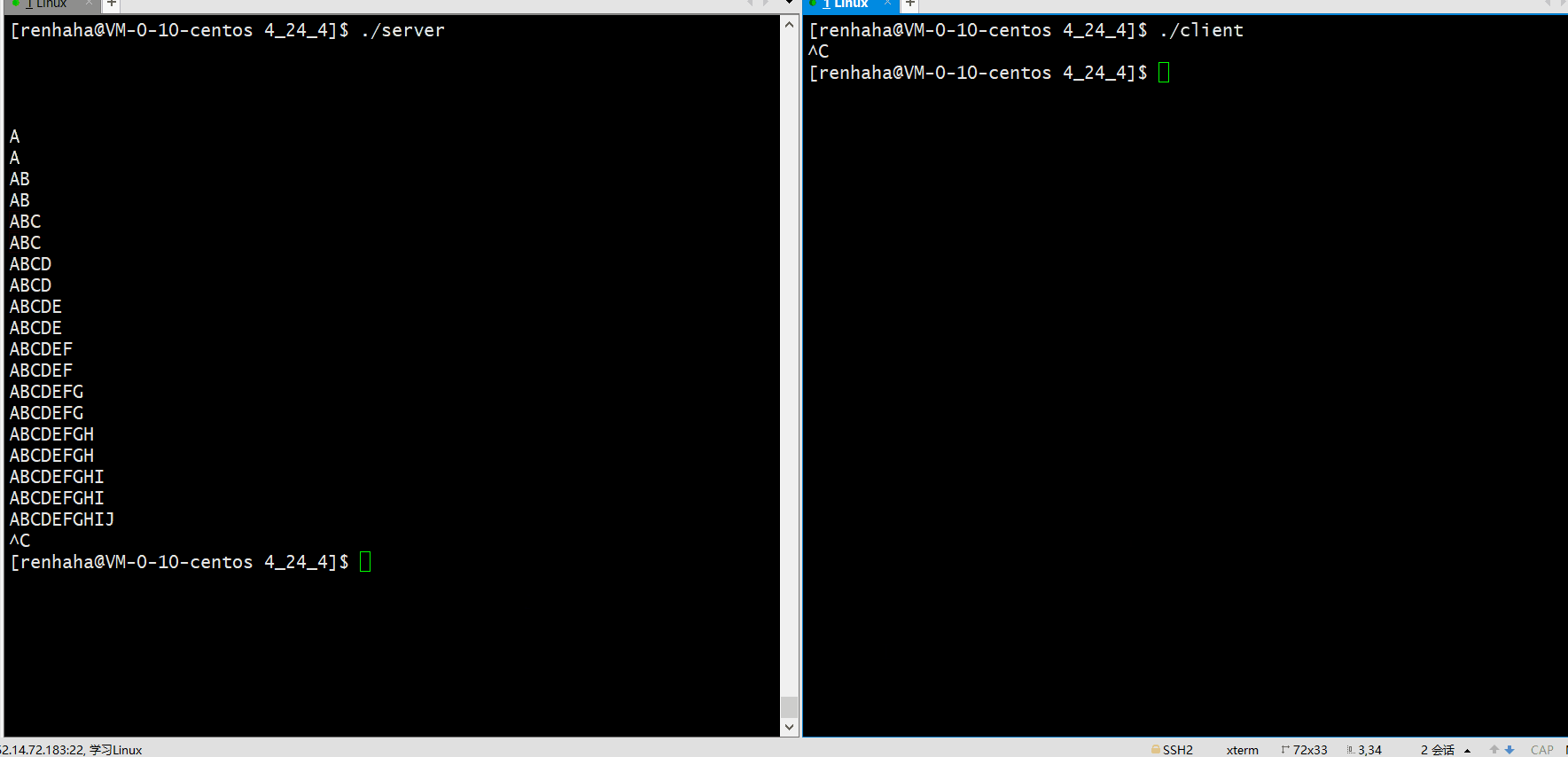
Scrapy请求子页面
请求及返回处理
创建项目
scrapy startproject douban_movie

创建爬虫
🎯进入到spiders文件下创建创建爬虫文件
cd douban_movie\douban_movie\spiders
创建爬虫
🎯命令[scrapy genspider 爬虫的名称 爬虫网站]
scrapy genspider movie movie.douban.com
创建成功

数据解析
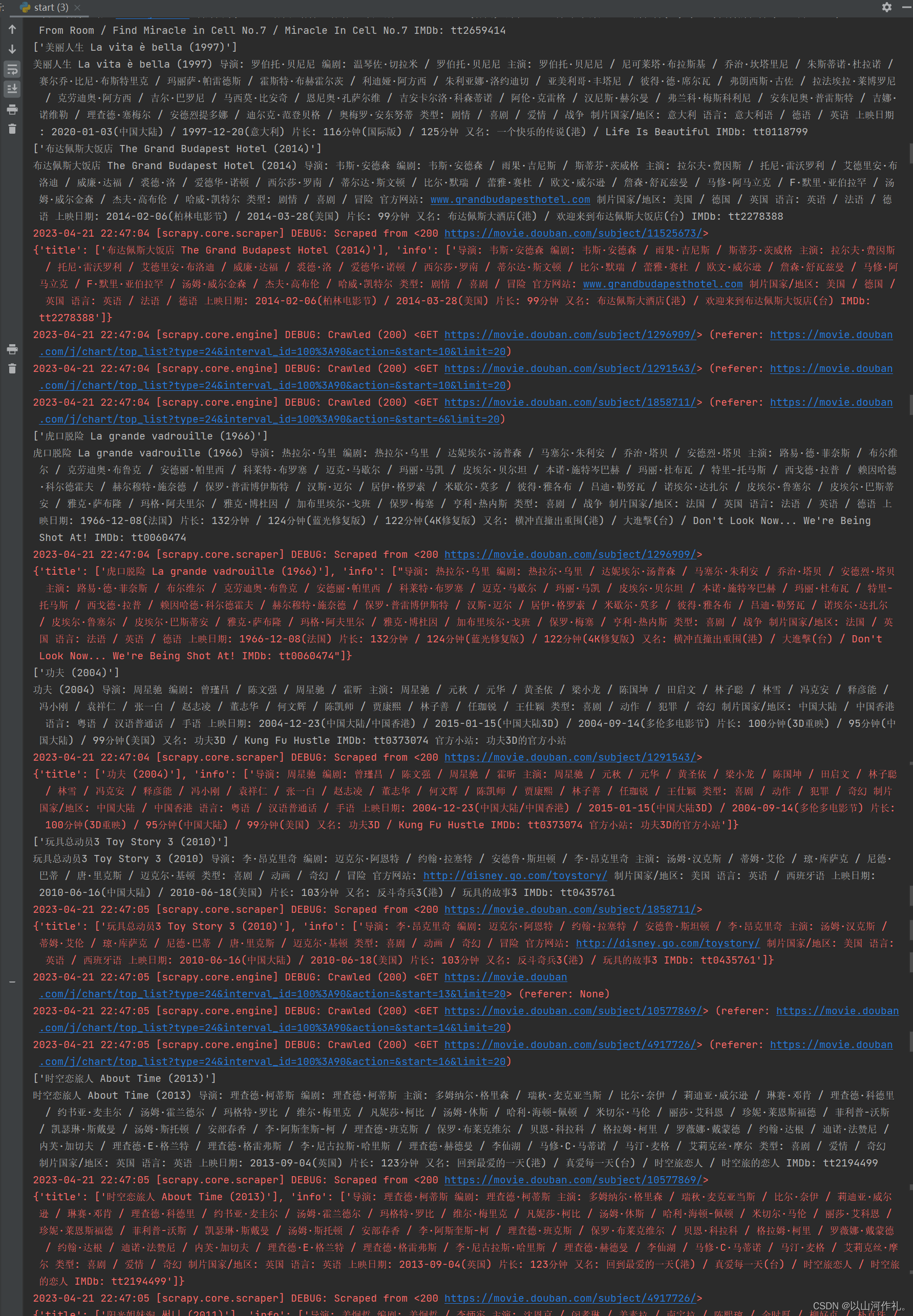
title = response.xpath('normalize-space(string(//div[@id="content"]/h1))').extract()
info = response.xpath('normalize-space(string(//div[@id="info"]))').extract()
import scrapy
class MovieSpider(scrapy.Spider):
name = "movie"
allowed_domains = ["movie.douban.com"]
start_urls = [
f'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start={i}&limit=20'
for i in range(0, 100)]
def parse(self, response, *_):
urls = [i['url']for i in response.json()]
yield from response.follow_all(urls=urls, callback=self.parse_t)
def parse_t(self,response,*_):
title = response.xpath('normalize-space(string(//div[@id="content"]/h1))').extract()
info = response.xpath('normalize-space(string(//div[@id="info"]))').extract()
print(title)
# yield {
# 'title': title,
# 'info': info
# }
zip(title, info)
for i in zip(title, info):
print(i[0], i[1])
yield {
'title': title,
'info': info
}
写入csv文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import csv
class DoubanMoviePipeline:
def __init__(self):
self.f = open('电影.csv', 'w+', encoding='utf', newline='')
self.csv_f = csv.writer(self.f)
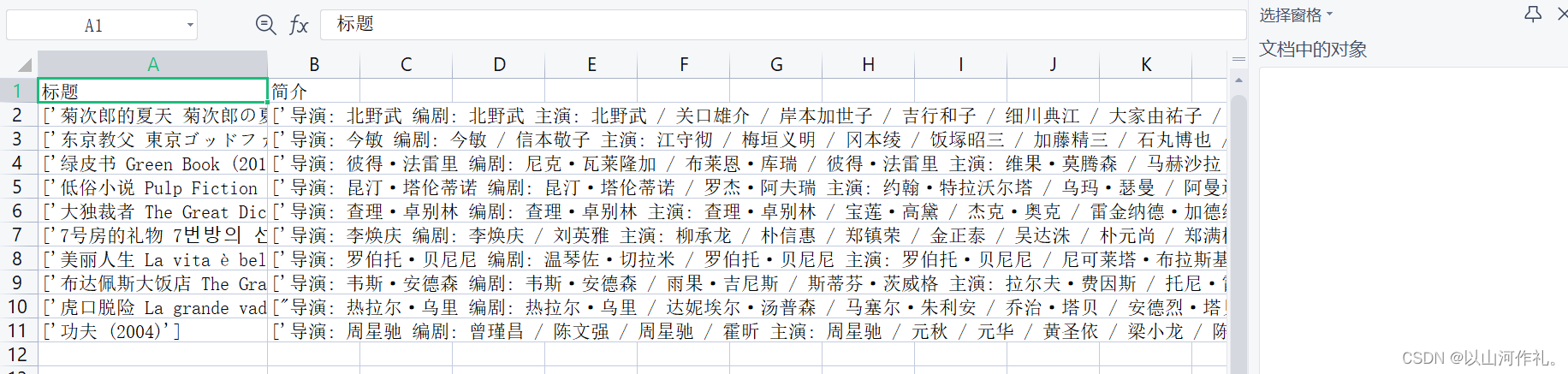
self.csv_f.writerow(['标题', '简介'])
def process_item(self, item, spider):
self.csv_f.writerow([item['title'], item['info']])
return item
def close_spider(self):
self.f.close()
print("信息写入完成!")
后记
👉👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹