- 作者:20岁爱吃必胜客(坤制作人),近十年开发经验, 跨域学习者,目前于海外某世界知名高校就读计算机相关专业。
- 荣誉:
阿里云博客专家认证、腾讯开发者社区优质创作者,在CTF省赛校赛多次取得好成绩。跨领域学习,喜欢摄影、弹吉他、咏春拳。文章深入浅出、语言风趣;爱吃必胜客社区创立者,旨在“发现美 欣赏美
- 🏆 学习系列专栏
。🏅 Python学习宝库
。🏅 网络安全学习宝库


文章目录
- ⭐️前言
- 🌟 了解爬虫
- 🌟 准备
- ☀️获取名字
- ⭐️完整版
- 🌟 持久化保存
- zip函数-打包为元组的列表
⭐️前言
python爬虫爬取网络的信息,非常好用,我们要学会,拿来下载自己喜欢的图,放到服务器使劲爬,不用自己复制粘贴。
有非常好的现实意义!
🌟 了解爬虫
就是B/S结构,我们直接用python装成浏览器去访问server就ok!
然后把响应保存即可。
🌟 准备
python">import requests
# 发送请求
url="https://nba.hupu.com/stats/players"
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"}
resp=requests.get(url=url,headers=headers)
print(resp.text)
# 处理结果
# 解析响应数据
# 是否保存
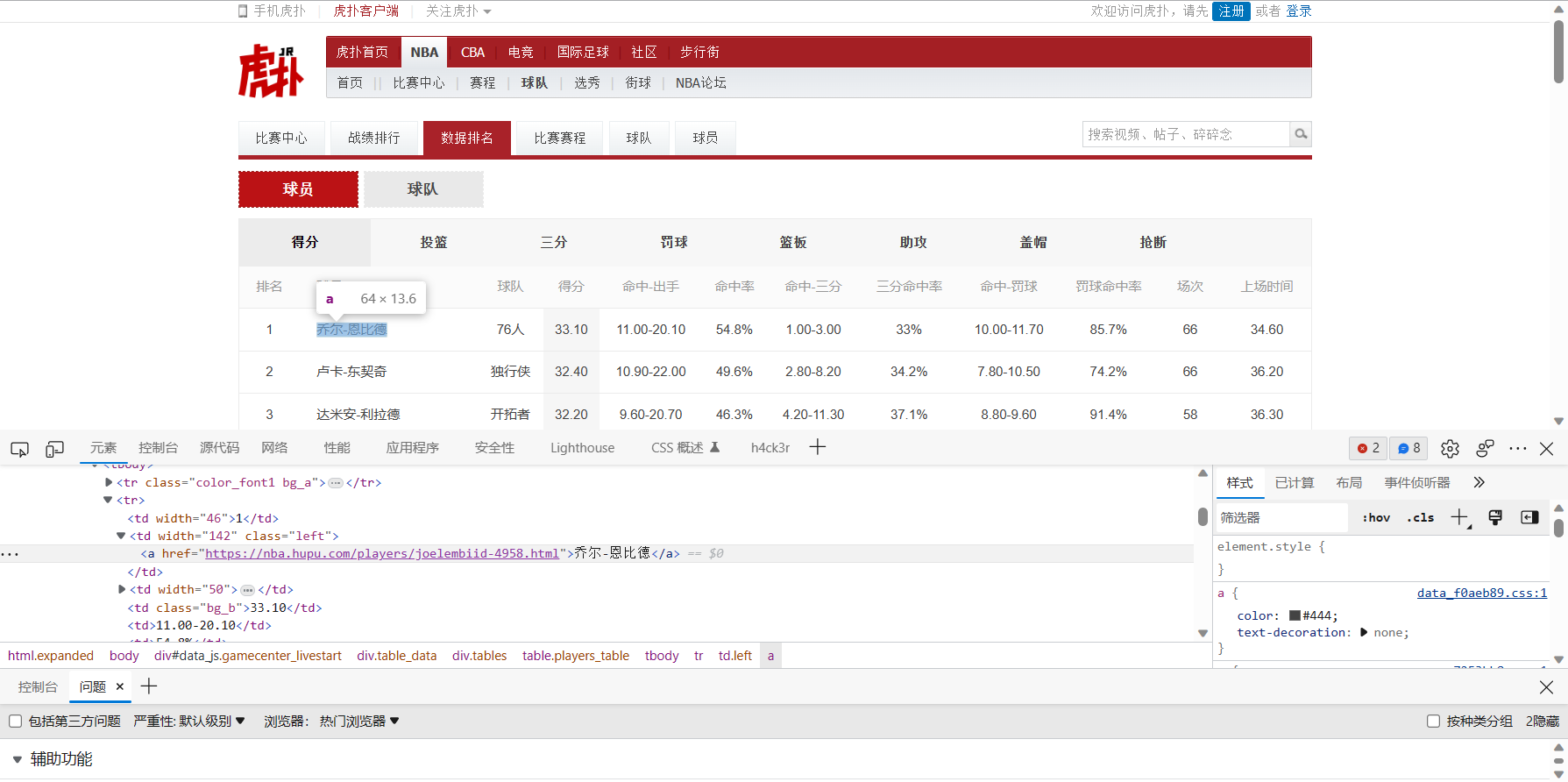
☀️获取名字
python">import requests
from lxml import etree
# 发送请求
url="https://nba.hupu.com/stats/players"
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"}
resp=requests.get(url=url,headers=headers)
# 处理结果
e=etree.HTML(resp.text)
# 解析响应数据
names=e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
# 是否保存
print(names)
python">['乔尔-恩比德', '卢卡-东契奇', '达米安-利拉德', '谢伊-吉尔杰斯-亚历山大', '扬尼斯-阿德托昆博', '杰森-塔特姆', '多诺万-米切尔', '杰伦-布朗', '贾-莫兰特', '特雷-杨', '劳里-马尔卡宁', '朱利叶斯-兰德尔', '达龙-福克斯', '扎克-拉文', '安东尼-爱德华兹', '德马尔-德罗赞', '尼古拉-约基奇', '帕斯卡尔-西亚卡姆', '杰伦-布伦森', '克里斯塔普斯-波尔津吉斯', '吉米-巴特勒', '杰伦-格林', '凯尔登-约翰逊', '克莱-汤普森', '达里厄斯-加兰', '博扬-波格丹诺维奇', '德斯蒙德-贝恩', '凯尔-库兹马', '安芬尼-西蒙斯', '特里-罗齐尔', '詹姆斯-哈登', 'CJ-麦科勒姆', '乔丹-克拉克森', '杰拉米-格兰特', '德章泰-默里', '巴姆-阿德巴约', '乔丹-普尔', '泰雷斯-马克西', '泰勒-希罗', '保罗-班切罗', '贾马尔-默里', 'RJ-巴雷特', '弗雷德-范弗利特', '朱-霍勒迪', '小凯文-波特', '多曼塔斯-萨博尼斯', '小贾伦-杰克逊', '弗朗茨-瓦格纳', '迈尔斯-特纳', '德安德烈-艾顿']
python">['76人', '独行侠', '开拓者', '雷霆', '雄鹿', '凯尔特人', '骑士', '凯尔特人', '灰熊', '老鹰', '爵士', '尼克斯', '国王', '公牛', '森林狼', '公牛', '掘金', '猛龙', '尼克斯', '奇才', '热火', '火箭', '马刺', '勇士', '骑士', '活塞', '灰熊', '奇才', '开拓者', '黄蜂', '76人', '鹈鹕', '爵士', '开拓者', '老鹰', '热火', '勇士', '76人', '热火', '魔术', '掘金', '尼克斯', '猛龙', '雄鹿', '火箭', '国王', '灰熊', '魔术', '步行者', '太阳']
⭐️完整版
python">import requests
from lxml import etree
# 发送请求
url="https://nba.hupu.com/stats/players"
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"}
resp=requests.get(url=url,headers=headers)
# 处理结果
e=etree.HTML(resp.text)
# 解析响应数据
nos=e.xpath('//table[@class="players_table"]//tr/td[1]/text()')
names=e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
teams=e.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
scores=e.xpath('//table[@class="players_table"]//tr/td[4]/text()')
# 是否保存
for i,j,k,l in zip(nos,names,teams,scores):
print(f"编号:{i} 姓名:{j} 球队:{k} 得分:{l}")
python">编号:排名 姓名:乔尔-恩比德 球队:76人 得分:得分
编号:1 姓名:卢卡-东契奇 球队:独行侠 得分:33.10
编号:2 姓名:达米安-利拉德 球队:开拓者 得分:32.40
编号:3 姓名:谢伊-吉尔杰斯-亚历山大 球队:雷霆 得分:32.20
编号:4 姓名:扬尼斯-阿德托昆博 球队:雄鹿 得分:31.40
编号:5 姓名:杰森-塔特姆 球队:凯尔特人 得分:31.10
编号:6 姓名:多诺万-米切尔 球队:骑士 得分:30.10
编号:7 姓名:杰伦-布朗 球队:凯尔特人 得分:28.30
编号:8 姓名:贾-莫兰特 球队:灰熊 得分:26.60
编号:9 姓名:特雷-杨 球队:老鹰 得分:26.20
编号:9 姓名:劳里-马尔卡宁 球队:爵士 得分:26.20
编号:11 姓名:朱利叶斯-兰德尔 球队:尼克斯 得分:25.60
编号:12 姓名:达龙-福克斯 球队:国王 得分:25.10
编号:13 姓名:扎克-拉文 球队:公牛 得分:25.00
编号:14 姓名:安东尼-爱德华兹 球队:森林狼 得分:24.80
编号:15 姓名:德马尔-德罗赞 球队:公牛 得分:24.60
编号:16 姓名:尼古拉-约基奇 球队:掘金 得分:24.50
编号:16 姓名:帕斯卡尔-西亚卡姆 球队:猛龙 得分:24.50
编号:18 姓名:杰伦-布伦森 球队:尼克斯 得分:24.20
编号:19 姓名:克里斯塔普斯-波尔津吉斯 球队:奇才 得分:24.00
编号:20 姓名:吉米-巴特勒 球队:热火 得分:23.20
编号:21 姓名:杰伦-格林 球队:火箭 得分:22.90
编号:22 姓名:凯尔登-约翰逊 球队:马刺 得分:22.10
编号:23 姓名:克莱-汤普森 球队:勇士 得分:22.00
编号:24 姓名:达里厄斯-加兰 球队:骑士 得分:21.90
编号:25 姓名:博扬-波格丹诺维奇 球队:活塞 得分:21.60
编号:25 姓名:德斯蒙德-贝恩 球队:灰熊 得分:21.60
编号:27 姓名:凯尔-库兹马 球队:奇才 得分:21.50
编号:28 姓名:安芬尼-西蒙斯 球队:开拓者 得分:21.20
编号:29 姓名:特里-罗齐尔 球队:黄蜂 得分:21.10
编号:29 姓名:詹姆斯-哈登 球队:76人 得分:21.10
编号:31 姓名:CJ-麦科勒姆 球队:鹈鹕 得分:21.00
编号:32 姓名:乔丹-克拉克森 球队:爵士 得分:20.90
编号:33 姓名:杰拉米-格兰特 球队:开拓者 得分:20.80
编号:34 姓名:德章泰-默里 球队:老鹰 得分:20.50
编号:34 姓名:巴姆-阿德巴约 球队:热火 得分:20.50
编号:36 姓名:乔丹-普尔 球队:勇士 得分:20.40
编号:36 姓名:泰雷斯-马克西 球队:76人 得分:20.40
编号:38 姓名:泰勒-希罗 球队:热火 得分:20.30
编号:39 姓名:保罗-班切罗 球队:魔术 得分:20.10
编号:40 姓名:贾马尔-默里 球队:掘金 得分:20.00
编号:40 姓名:RJ-巴雷特 球队:尼克斯 得分:20.00
编号:42 姓名:弗雷德-范弗利特 球队:猛龙 得分:19.60
编号:43 姓名:朱-霍勒迪 球队:雄鹿 得分:19.30
编号:43 姓名:小凯文-波特 球队:火箭 得分:19.30
编号:45 姓名:多曼塔斯-萨博尼斯 球队:国王 得分:19.20
编号:46 姓名:小贾伦-杰克逊 球队:灰熊 得分:19.10
编号:47 姓名:弗朗茨-瓦格纳 球队:魔术 得分:18.60
编号:47 姓名:迈尔斯-特纳 球队:步行者 得分:18.60
编号:49 姓名:德安德烈-艾顿 球队:太阳 得分:18.00
进程已结束,退出代码0
🌟 持久化保存
python">import requests
from lxml import etree
# 发送请求
url="https://nba.hupu.com/stats/players"
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48"}
resp=requests.get(url=url,headers=headers)
# 处理结果
e=etree.HTML(resp.text)
# 解析响应数据
nos=e.xpath('//table[@class="players_table"]//tr/td[1]/text()')
names=e.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
teams=e.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
scores=e.xpath('//table[@class="players_table"]//tr/td[4]/text()')
# 是否保存
with open("nba.txt","w",encoding="utf-8") as f:
for i,j,k,l in zip(nos,names,teams,scores):
f.write(f"编号:{i} 姓名:{j} 球队:{k} 得分:{l}\n")
zip函数-打包为元组的列表
zip([iterable, …])
参数说明:
iterable – 一个或多个迭代器;
返回元组列表。
实例
以下两个实例分别展示了 Python2.x 与 Python3.x zip 的使用方法:
实例(Python 2.0+)
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
实例(Python 3.0+)
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) # 返回一个对象
zipped
<zip object at 0x103abc288>
list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
a1, a2 = zip(zip(a,b)) # 与 zip 相反,zip() 可理解为解压,返回二维矩阵式
list(a1)
[1, 2, 3]
list(a2)
[4, 5, 6]