今天继续给大家介绍Python爬虫相关知识,本文主要内容是Python爬虫登录后token处理。
tokentoken_1">一、网页token及token作用
在上文Python爬虫登录后cookie处理中,我们介绍过使用使用Python爬虫解决cookie及网页登录访问问题。
然而,有的网站,例如DVWA,为了防止CSRF等攻击(CSRF漏洞是常见的安全漏洞之一,关于CSRF可以参考文章:CSRF漏洞简介),会设置token字段。
我们可以使用浏览器开发者工具检查登录页面HTML源代码如下所示:
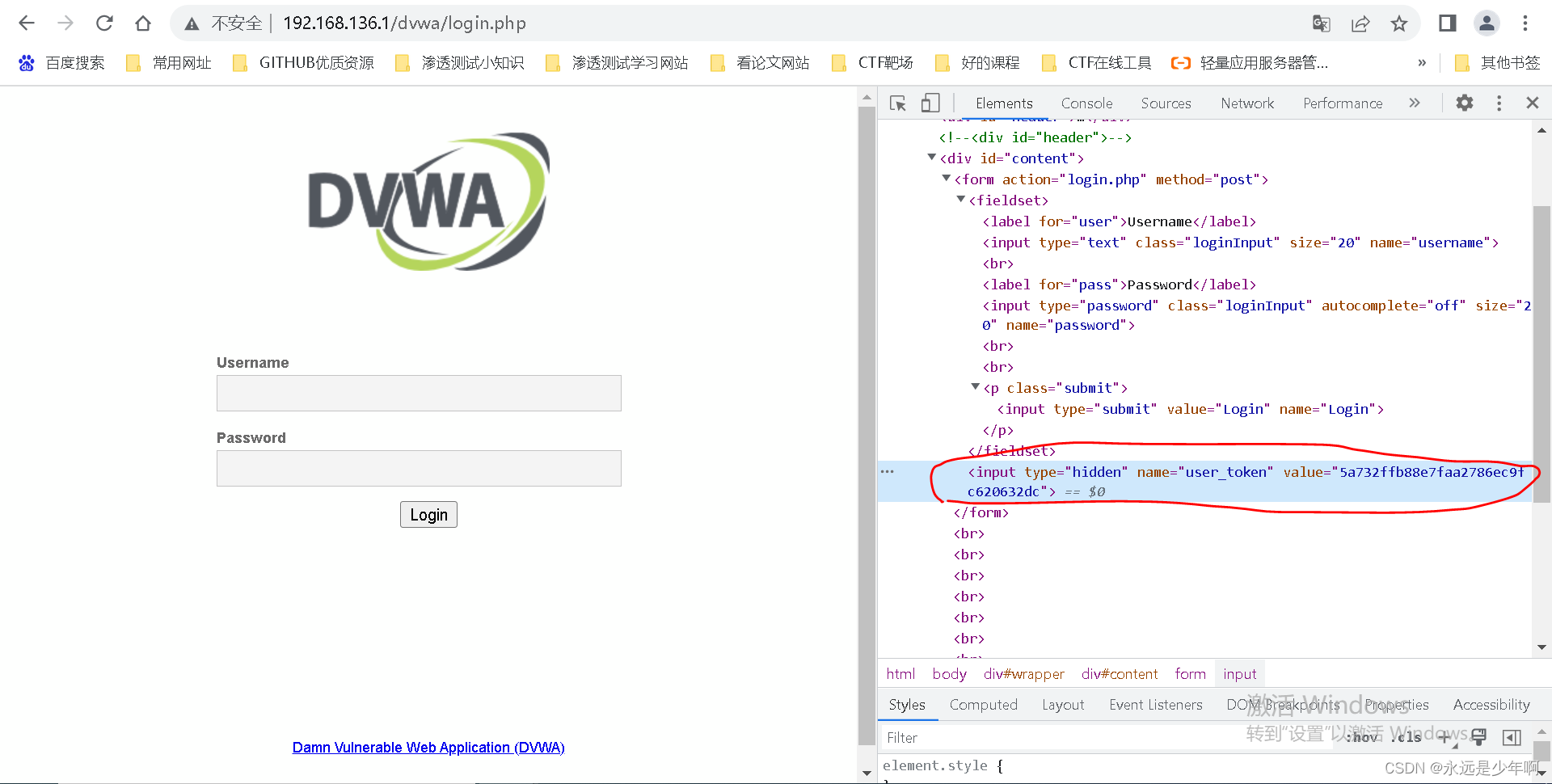
从上图中可以看出,在页面中有一个隐藏的input标签,因为该标签属性设置位了hidden,因此该标签不会显示在浏览器中,不会影响页面整体效果。但是该input标签是存在name和value的,因此当我们点击浏览器中的Login按钮时,该input标签中的name和value也会被当作POST提交数据的一部分进行提交。最麻烦的是,该字段的值会随着我们对页面的刷新而变化,这意味着我们无法从浏览器复制该值后粘贴到Python代码中!
token_7">二、Python爬虫token问题解决
为了解决这一问题,我们就必须先访问站点的登录页面,获取token值,在获取token值之后,将其作为登录数据包的POST提交数据的一部分,与用户名和密码一起提交。这样就解决了token的验证问题。
针对DVWA网站,我们实现的简单登录后爬取主页数据Python爬虫代码如下所示:
python">token keyword">import requests
token keyword">from lxml token keyword">import etree
url1token operator">=token string">"http://192.168.136.1/dvwa/login.php"
url2token operator">=token string">"http://192.168.136.1/dvwa/index.php"
headerstoken operator">=token punctuation">{token string">"User-Agent"token punctuation">:token string">"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"token punctuation">}
sessiontoken operator">=requeststoken punctuation">.sessiontoken punctuation">(token punctuation">)
response1token operator">=sessiontoken punctuation">.gettoken punctuation">(urltoken operator">=url1token punctuation">,headerstoken operator">=headerstoken punctuation">)
page_text1token operator">=response1token punctuation">.text
treetoken operator">=etreetoken punctuation">.HTMLtoken punctuation">(page_text1token punctuation">)
tokentoken operator">=treetoken punctuation">.xpathtoken punctuation">(token string">'//*[@id="content"]/form/input/@value'token punctuation">)token punctuation">[token number">0token punctuation">]
token keyword">printtoken punctuation">(tokentoken punctuation">)
datatoken operator">=token punctuation">{
token string">"username"token punctuation">:token string">"admin"token punctuation">,
token string">"password"token punctuation">:token string">"password"token punctuation">,
token string">"Login"token punctuation">:token string">"login"token punctuation">,
token string">"user_token"token punctuation">:token
token punctuation">}
response2token operator">=sessiontoken punctuation">.posttoken punctuation">(urltoken operator">=url1token punctuation">,headerstoken operator">=headerstoken punctuation">,datatoken operator">=datatoken punctuation">)
response3token operator">=sessiontoken punctuation">.gettoken punctuation">(urltoken operator">=url2token punctuation">,headerstoken operator">=headerstoken punctuation">)
page_texttoken operator">=response3token punctuation">.text
fptoken operator">=token builtin">opentoken punctuation">(token string">"./dvwa.html"token punctuation">,token string">'w'token punctuation">)
fptoken punctuation">.writetoken punctuation">(page_texttoken punctuation">)
fptoken punctuation">.closetoken punctuation">(token punctuation">)
在上述代码中,我们一共发起了3次session请求,第一次请求是为了获取token,第二次请求是为了成功登录,并获取登录后的cookie,第三次请求是为了拿到登录后的主页数据。上述代码执行后,我们成功下载到了登录后的源码数据,结果如下所示:
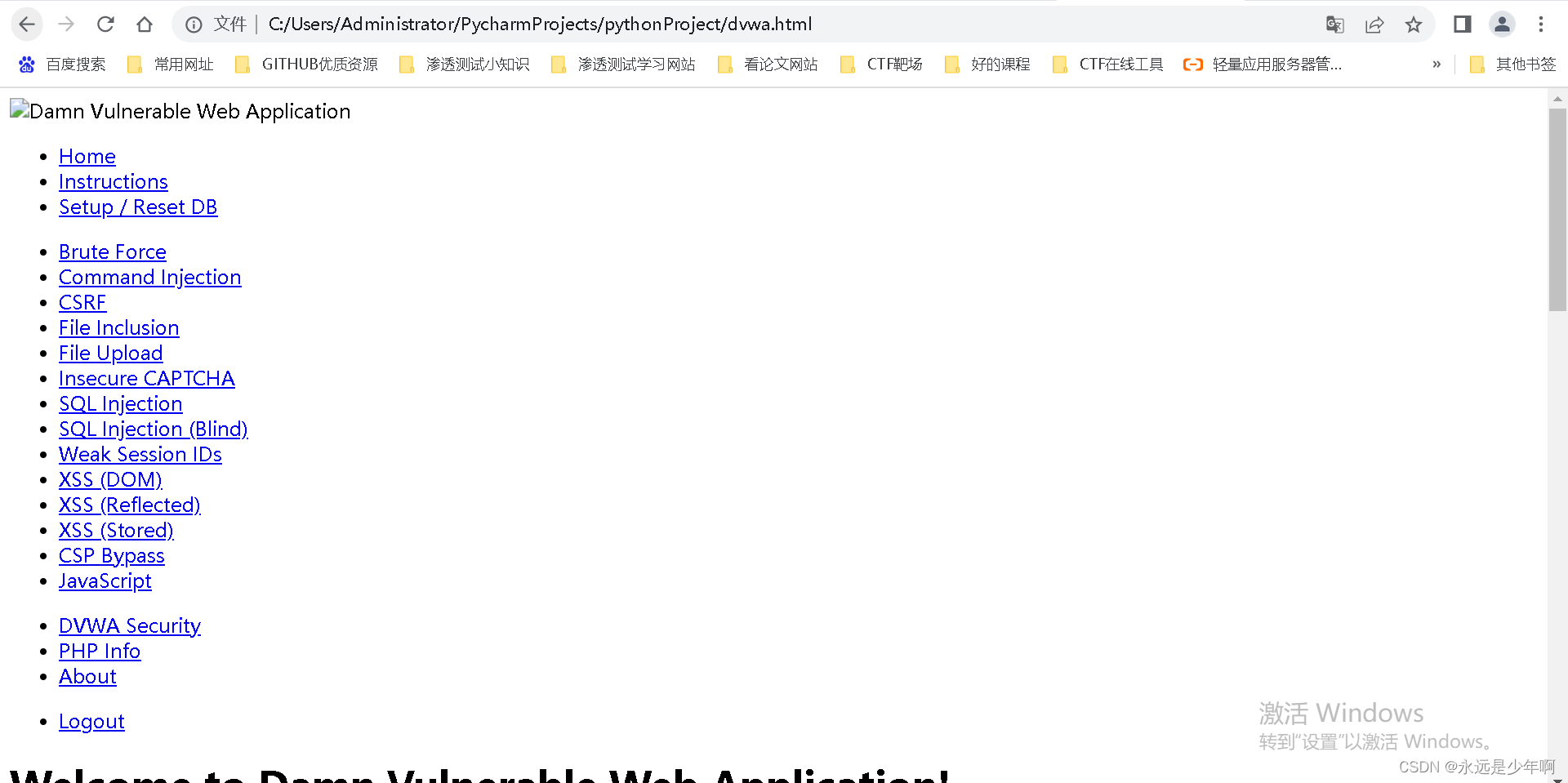
从上图可以看出,我们使用Python爬虫处理token成功!
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200