前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅!
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一, 第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八,欢迎阅读!
🎈🎈欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

正则表达式(Regular Expression)
正则表达式(Regular Expression)是一种用于匹配字符串的工具,它可以根据特定的规则来匹配字符串。正则表达式通常由一组字符和字符集合组成,其中字符集合定义了匹配的字符类型和位置。
re.I
🧾 🧾 语法: re.IGNORECASE 或简写为 re.I
🧾 🧾 含义: 进行忽略大小写匹配。
在Python中,可以使用re模块中的re.IGNORECASE标志来实现正则表达式的忽略大小写。例如,如果要匹配字符串apple,可以使用以下代码:
python">import re
pattern = re.compile('apple', re.I)
text = 'The apple is red'
match = pattern.search(text)
if match:
print(match.group())
else:
print('未找到匹配的字符串')
运行结果:
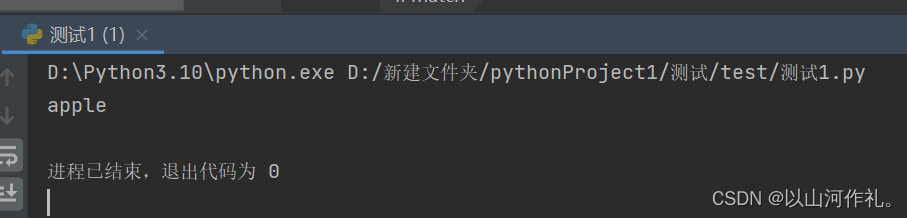
在上面的代码中,re.I标志被用来匹配字符串apple,这意味着在匹配时忽略大小写。pattern.search(text) 函数返回一个Match对象,如果找到匹配的字符串,则match.group()方法将被调用并打印出来,否则打印出未找到匹配的字符串。
re.A
🧾 🧾 语法: re.ASCII 或简写为 re.A
🧾 🧾 作用: ASCII表示ASCII码的意思,让 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII,而不是Unicode。
当使用re模块进行正则表达式匹配时,可以使用re.ASCII或re.A标志来匹配ASCII字符集,而不是Unicode字符集。这意味着,\w、\W、\b、\B、\d、\D、\s和\S只会匹配ASCII字符,而不是Unicode字符。
以下是一个使用re.ASCII或re.A标志的简单示例:
python">import re
# 匹配ASCII字符集中的数字和字母
pattern = re.compile(r'\w+', flags=re.ASCII)
text = 'Hello 世界 123'
match = pattern.findall(text)
print(match)
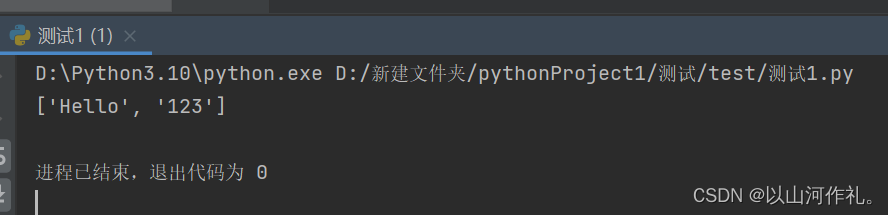
在上面的示例中,我们使用re.compile()函数创建了一个正则表达式对象,该对象使用了re.ASCII标志。然后,我们使用该对象的findall()方法在文本中查找匹配项。由于我们使用了re.ASCII标志,所以只有ASCII字符集中的数字和字母被匹配到,而中文字符被忽略。因此,输出结果为[‘Hello’,
‘123’],而不包括’世界’这个中文字符。
re.S
🧾🧾 语法: re.DOTALL 或简写为 re.S
🧾🧾 作用: DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。默认模式下.是不能匹配行符\n的。
re.DOTALL或简写为re.S是re模块的一个标志,用于指定正则表达式匹配时,".“符号是否能够匹配换行符。当re.DOTALL或re.S标志被设置时,”.“符号将匹配任何字符,包括换行符。如果没有设置这个标志,”."符号将不匹配换行符。
以下是一个使用re.DOTALL标志的示例:
python">import re
text = 'hello\nworld'
pattern = re.compile('.*', re.DOTALL)
match = pattern.match(text)
print(match.group(0))
运行结果:
python">'hello\nworld'
可以看到,因为使用了re.DOTALL标志,"."符号匹配了换行符,所以整个文本都被匹配了。
需要注意的是,re.DOTALL标志只对"."符号起作用,其他的元字符和字符类仍然按照原来的规则匹配。
如果需要匹配包括换行符在内的所有字符,可以使用如下的正则表达式:
python">pattern = re.compile('.*', re.DOTALL | re.MULTILINE)
这里使用了re.MULTILINE标志,表示多行匹配,以便"."符号能够匹配换行符。
re.M
🧾 🧾 语法: re.MULTILINE 或简写为 re.M
🧾 🧾 含义: 多行模式,当某字符串中有换行符\n,默认模式下是不支持换行符特性的,比如:行开头和行结尾,而多行模式下是支持匹配行开头的。
在Python中,可以使用re模块中的re.MULTILINE标志来实现正则表达式的多行匹配。
例如,如果要匹配字符串apple,可以使用以下代码:
python">
import re
pattern = re.compile('apple', re.MULTILINE)
text = 'The apple is red'
match = pattern.search(text)
if match:
print(match.group())
else:
print('未找到匹配的字符串')
运行结果:
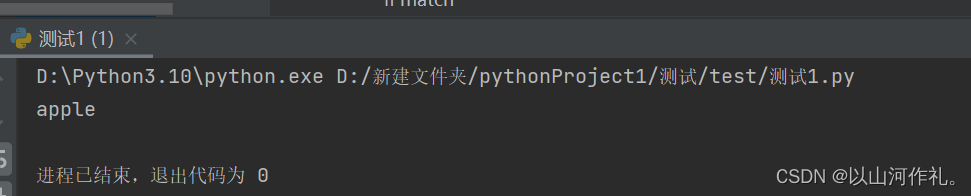
在上面的代码中,re.MULTILINE标志被用来匹配字符串apple,这意味着可以在一行中匹配多个字符串。pattern.search(text)函数返回一个Match对象,如果找到匹配的字符串,则match.group()方法将被调用并打印出来,否则打印出未找到匹配的字符串。
注意:正则语法中^匹配行开头、\A匹配字符串开头,单行模式下它两效果一致,多行模式下\A不能识别\n。
re.X
🧾 🧾 语法: re.VERBOSE 或简写为 re.X
🧾 🧾 作用: 详细模式,可以在正则表达式中加注解!
re.VERBOSE 或简写为 re.X 是 re.compile()函数中的一个可选参数,用于在正则表达式中添加注释。它允许在正则表达式中使用空格、换行符和注释,从而使正则表达式更易于阅读和理解。
例如:
python">import re
# 匹配电子邮件地址
pattern = re.compile(r'''
^ # 匹配字符串开头
[\w\.\+\-]+ # 用户名,可以包含字母、数字、点、加号和减号
@ # @ 符号
[\w\.\-]+ # 域名,可以包含字母、数字、点和减号
\. # . 符号
[a-zA-Z]{2,4} # 域名后缀,可以是 2 到 4 个字母
$ # 匹配字符串结尾
''', re.VERBOSE)
# 测试正则表达式
print(pattern.match('john.doe+test@example.com'))
输出:
python"><re.Match object; span=(0, 27), match='john.doe+test@example.com'>
re.L
🧾 🧾 语法: re.LOCALE 或简写为 re.L
🧾 🧾 作用: 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配,这个标记只能对byte样式有效,该标记官方已经不推荐使用,因为语言区域机制很不可靠,它一次只能处理一个 "习惯”,而且只对8位字节有效。
re.LOCALE 或简写为 re.L 是 re.compile()函数中的一个可选参数,用于启用本地化匹配。它会根据当前系统的本地化设置,对正则表达式中的某些字符类别(如\w、\W、\b、\B)进行本地化处理,从而匹配更广泛的字符集
使用 re.LOCALE 可能会影响正则表达式的行为,因为它取决于系统的本地化设置。因此,如果需要编写可移植的正则表达式,最好不要使用 re.LOCALE。
以下是一个使用 re.LOCALE 的示例:
python">import re
# 匹配非字母数字字符
pattern = re.compile(r'\W+', re.LOCALE)
# 测试正则表达式
print(pattern.findall('Hello, 你好!'))
输出:
python">[',', '!']
re.U
🧾 🧾 语法: re.UNICODE 或简写为 re.U
🧾 🧾 作用: 与 ASCII常量类似,匹配unicode编码支持的字符,但是Python3默认字符串已经是Unicode,所以显得有点多余。
re.UNICODE 或简写为 re.U 是 re.compile() 函数中的一个可选参数,用于启用 Unicode
匹配模式。它会将正则表达式中的某些字符类别(如 \w、\W、\b、\B)扩展到 Unicode 字符集,从而匹配更广泛的字符集。
在 Python 3 中,默认情况下所有正则表达式都启用了 Unicode 匹配模式,所以在大多数情况下不需要使用 re.UNICODE。
以下是一个使用 re.UNICODE 的示例:
python">import re
# 匹配非字母数字字符
pattern = re.compile(r'\W+', re.UNICODE)
# 测试正则表达式
print(pattern.findall('Hello, 你好!'))
输出:
python">[',', '!']
🧾 🧾 理论讲解完毕,结合之前学到的知识和新学到的知识来实战吧!🧾 🧾 !
美某杰实战
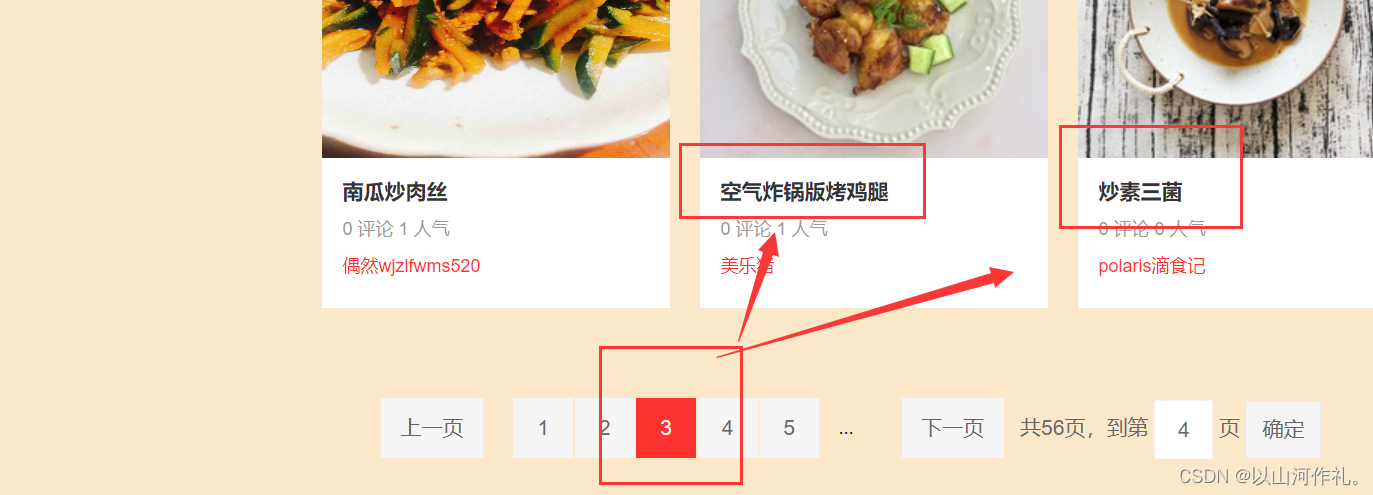
1️⃣本次实战目的是使用正则表达式获取红色方框里面的内容并写到csv文档里面。

2️⃣首先我们应该先检查数据是否在链接里面,然后如果在,我们通过链接获取前三页的数据。
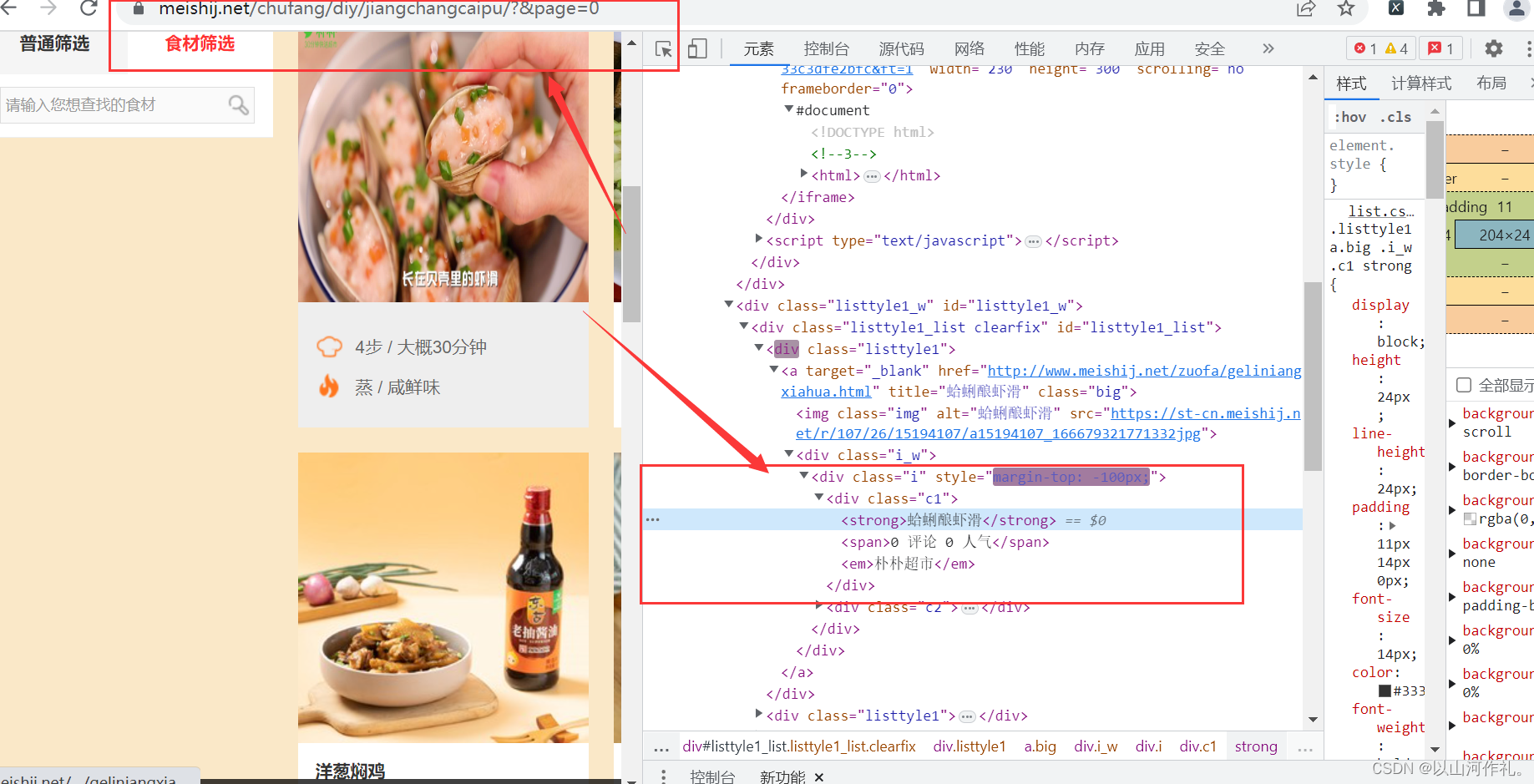
3️⃣确认数据在链接中,复制链接,开始敲代码!!!
python">import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
for i in range(1, 4):
url = f'https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}'
html = requests.get(url, headers=headers)
print(html.text)
运行结果:
4️⃣ok,我们可以看见,我们的数据在代码里面,接下来,我们来使用正则表达式来提取数据!!如果还有不会的朋友,可以阅读我之前写的文章。《3.网络爬虫——Requests模块get请求与实战》
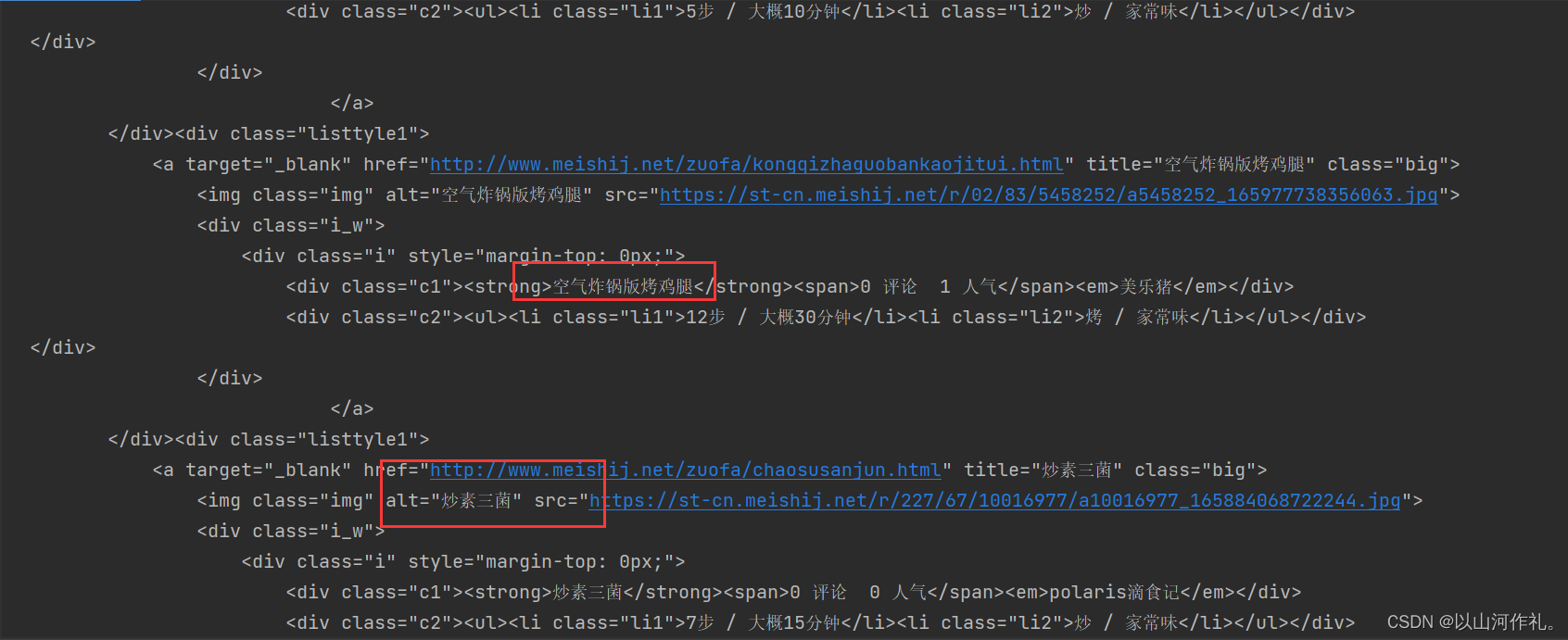
5️⃣通过观察元素,我们发现,我们需要的数据在这里面,我们开始找规律,好方便用正则表达式来把数据提取出来!

6️⃣我们来多看几组数据,好发现规律!

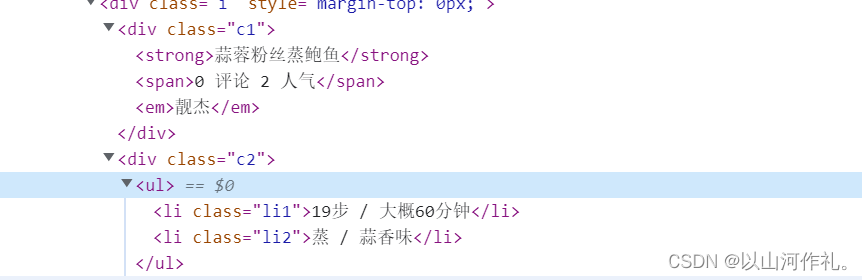
7️⃣ 通过观察我们发现,数据都在这里面,请看代码:
python">
<div class="c1"><strong>蛤蜊酿虾滑</strong><span>0 评论 0 人气</span><em>朴朴超市</em></div>
<div class="c2"><ul><li class="li1">4步 / 大概30分钟</li><li class="li2">蒸 / 咸鲜味</li></ul></div>
<div class="c1"><strong>洋葱焖鸡</strong><span>0 评论 2 人气</span><em>东古美食厨房</em></div>
<div class="c2"><ul><li class="li1">5步 / 大概15分钟</li><li class="li2">焖 / 家常味</li></ul></div>
<div class="c1"><strong>蒜蓉粉丝蒸鲍鱼</strong><span>0 评论 1 人气</span><em>靓杰</em></div>
<div class="c2"><ul><li class="li1">11步 / 大概60分钟</li><li class="li2">蒸 / 家常味</li></ul></div>
8️⃣这个时候,我们发现代码有空格和换行怎么办?
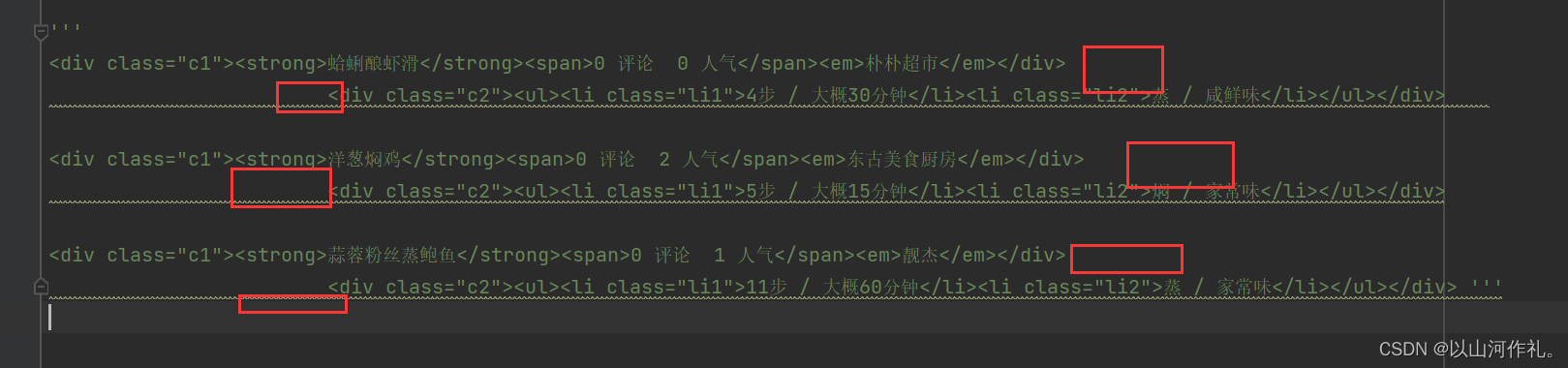
9️⃣我们会用到之前讲的
\s*来让数据在一行,而不影响正则表达式的使用。\s*的作用是匹配零个或多个空格字符(包括空格、制表符、换行符等)。它常用于正则表达式中,用于匹配任意数量的空格字符。
🔟使用正则表达式来获取数据
python">'<div class="c1"><strong>(\w+)</strong><span>(.*?)</span><em>(.*?)</em></div>\s*<div class="c2"><ul><li class="li1">(.*?)</li><li class="li2">(.*?)</li></ul></div>',
\w+ 的作用是匹配一个或多个字母、数字或下划线字符。其中,\w 表示匹配任意一个字母、数字或下划线字符,+
表示匹配前面的元素一次或多次。该正则表达式通常用于匹配单词、变量名等含有字母、数字、下划线的字符串。
“.*?” 表示非贪心算法,表示要精确的配对。
作用是匹配任意数量的任意字符,但是会尽可能少地匹配,直到下一个匹配字符出现
“.*”表示贪心算法,表示要尽可能多的匹配
“.”表示匹配任意数量的任意字符,包括空格、制表符、换行符等,且是贪心算法,即尽可能多地匹配字符。这意味着它会匹配尽可能多的字符,直到无法匹配为止。
例如,对于字符串 “abc123def456”,使用正则表达式
“.\d+”,会匹配整个字符串,因为它会尽可能多地匹配字符,直到遇到数字为止。
1️⃣1️⃣完整代码如下:
python">import re
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
def main(index):
url = f'https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={index}'
html = requests.get(url, headers=headers)
data = re.findall(
'<div class="c1"><strong>(\w+)</strong><span>(.*?)</span><em>(.*?)</em></div>\s*<div class="c2"><ul><li class="li1">(.*?)</li><li class="li2">(.*?)</li></ul></div>',
html.text)
for i in data:
print(i)
for i in range(1, 4):
main(i)
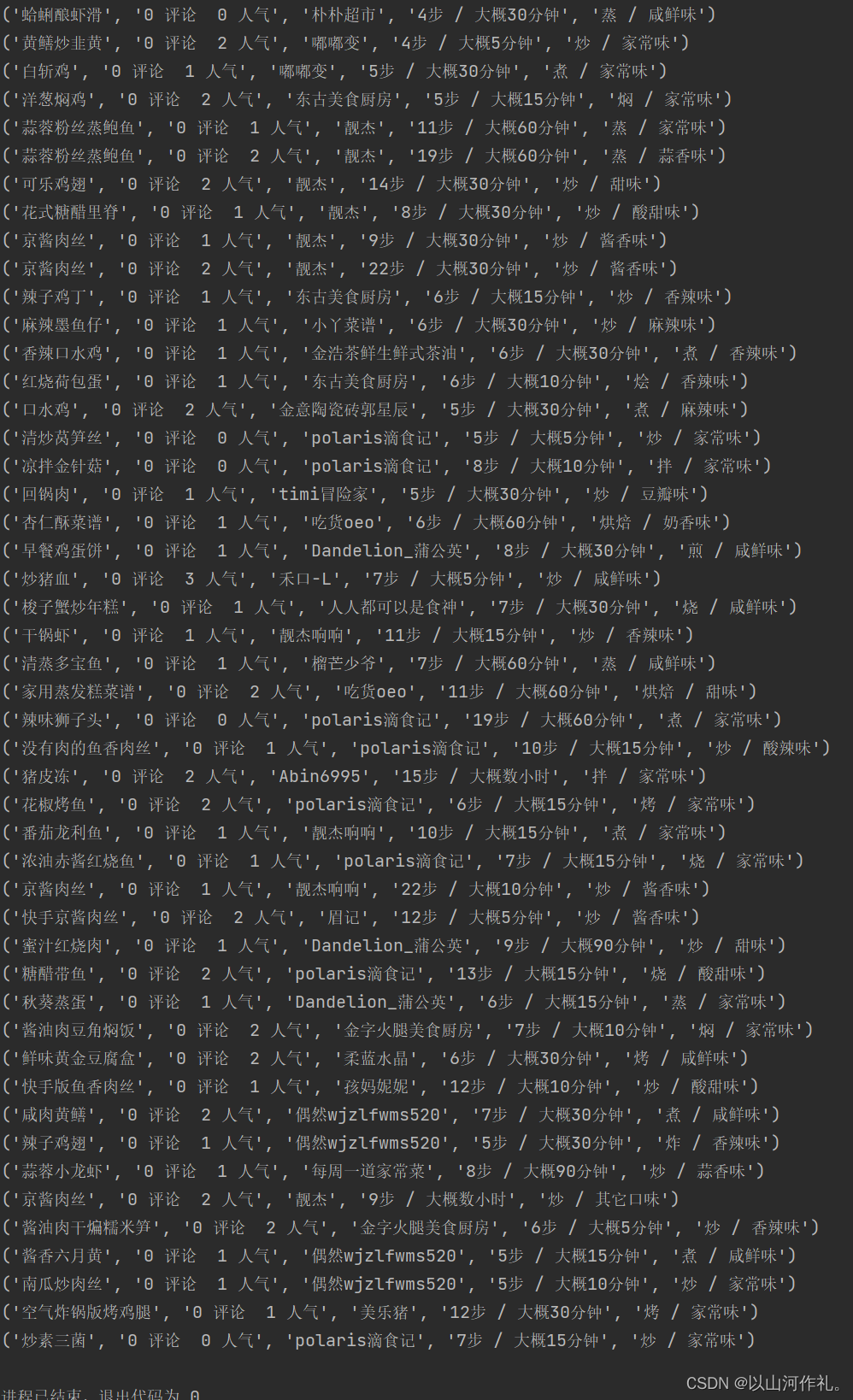
运行结果:
写入csv文件:
先导入:

python">f = open('data.csv', 'w+', encoding='gbk', newline='')
csv_f = csv.writer(f)
csv_f.writerow(['菜名', '信息', '作者', '大概步骤', '类型'])
作用是打开一个名为 data.csv 的文件(如果不存在则创建),并使用 gbk 编码方式进行读写操作,同时设置换行符为
‘\n’。然后创建一个 csv.writer 对象 csv_f,用于将数据写入到文件中。接下来,使用 csv_f.writerow()
方法将包含列名的一行写入到文件中,该行包含了菜名、信息、作者、大概步骤和类型这五个列的名称。这样,文件 data.csv
就具有了一个表格的结构,可以用于存储和处理数据。
然后把这个代码写进去,就得到一个完整的代码:
python">import csv
import re
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
f = open('data.csv', 'w+', encoding='gbk', newline='')
csv_f = csv.writer(f)
csv_f.writerow(['菜名', '信息', '作者', '大概步骤', '类型'])
def main(index):
url = f'https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={index}'
html = requests.get(url, headers=headers)
# print(html.text)
data = re.findall(
'<div class="c1"><strong>(\w+)</strong><span>(.*?)</span><em>(.*?)</em></div>\s*<div class="c2"><ul><li class="li1">(.*?)</li><li class="li2">(.*?)</li></ul></div>',
html.text)
# print(data)
for i in data:
csv_f.writerow(i)
print(i)
for i in range(1, 4):
main(i)
f.close()
我们来查看一下csv文件:
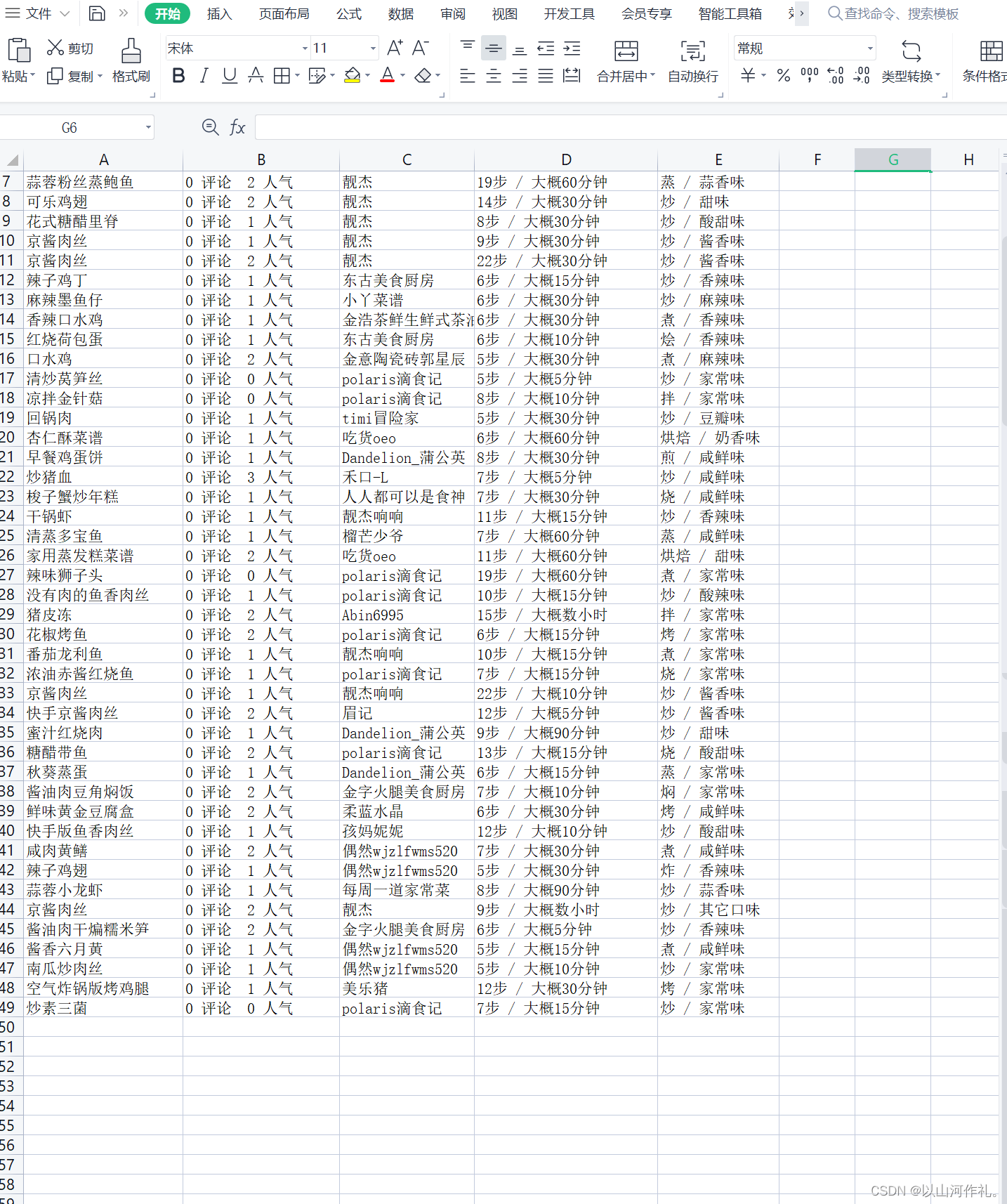
🍁 🍁今日学习笔记到此结束,是不是很简单。再次感谢你的阅读,如有疑问或者问题欢迎私信,我会帮忙解决,如果没有回,那我就是在教室上课,抱歉。
🍂🍂🍂🍂