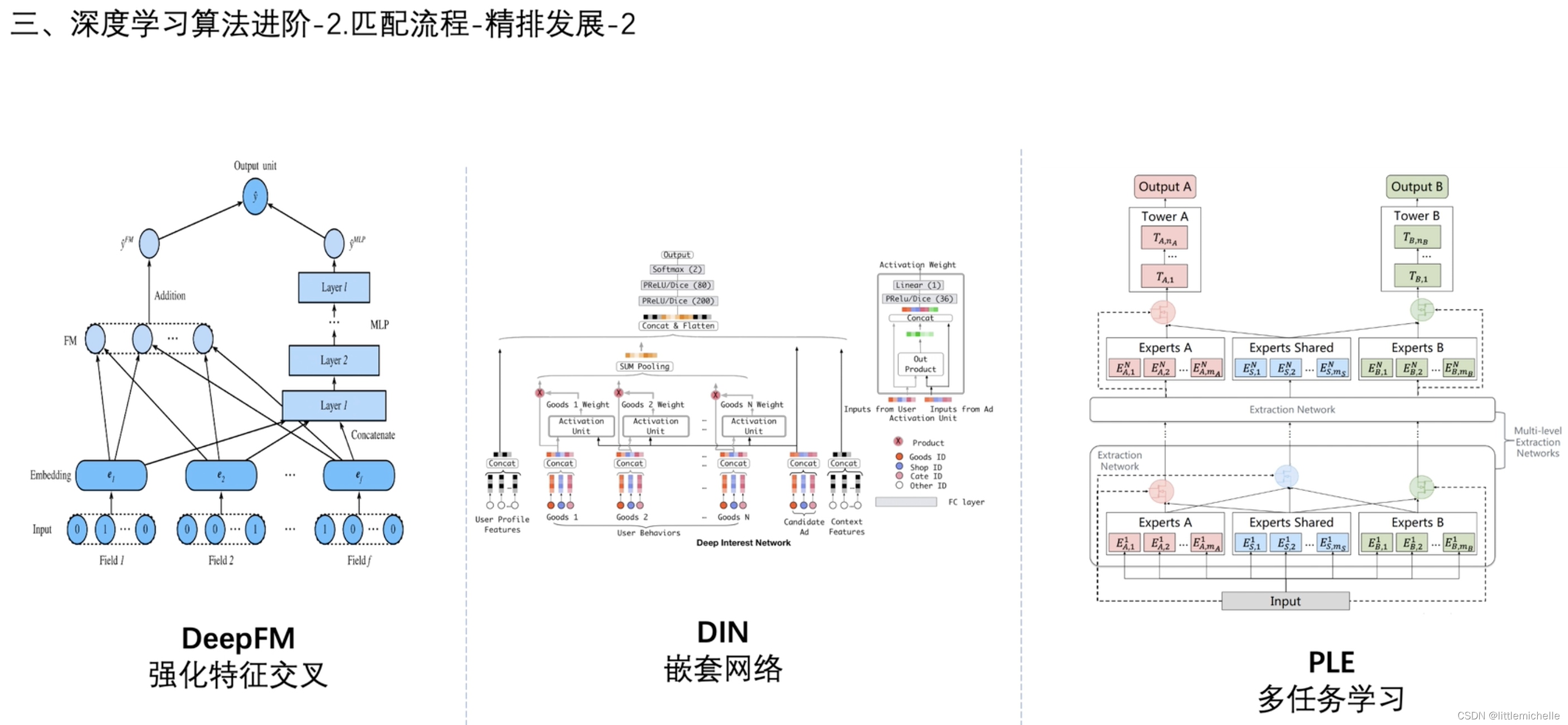
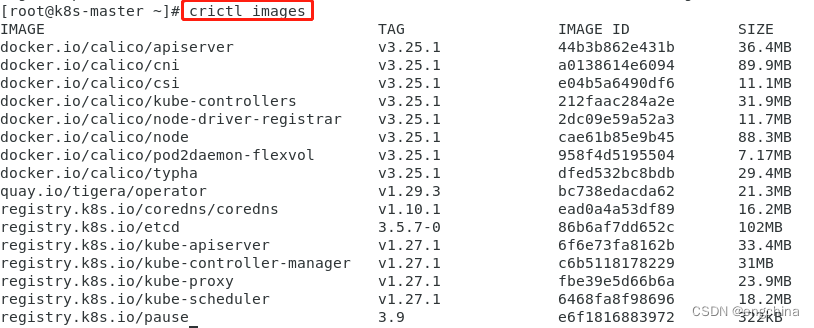
Scrapy 简介
Scrapy 是一个用于数据抓取的 Python 框架。它可以轻松地从互联网上的网站中提取所需的数据。Scrapy 框架具有高效且可扩展的架构,可以处理大量数据并提高数据爬取的效率。
Scrapy 由 Python 编写,是一个开源项目,它为数据抓取提供了一种灵活的方式,可以直接从互联网上爬取所需的数据,比如图片、文本、视频等等。它的灵活性和高效性可以帮助用户轻松地从多个网站中收集数据,并将其用于数据分析和数据挖掘。
Scrapy 是一个强大的框架,它包含了很多有用的功能,比如支持异步处理、支持 HTTP 加密、支持代理等等。此外,它还有一个强大的社区,用户可以在社区中分享自己的经验和技巧,并获得其他用户的帮助和支持。
Scrapy 概述
Scrapy 框架由四个核心组件组成:引擎、蜘蛛、下载器和数据管道。下面将对这些组件进行详细介绍。
引擎
引擎是 Scrapy 框架的核心组件之一。它负责协调所有组件之间的交互,并控制整个框架的工作流程。引擎的主要职责是将蜘蛛程序生成的请求分配给下载器,然后将下载器下载的响应交给蜘蛛程序处理。引擎还负责处理下载器的异常情况和错误,以及监控整个框架的运行状态。
蜘蛛
蜘蛛是 Scrapy 框架的另一个核心组件。它们负责从 Web 上收集所需的数据。蜘蛛通常包含一个起始 URL,该 URL 是指向要爬取的 Web 页面的链接。蜘蛛程序的主要任务是解析响应,提取所需的数据,并生成新的请求,以便继续爬取更多的数据。蜘蛛程序还可以通过设置过滤规则,过滤掉不需要的数据。
下载器
下载器是 Scrapy 框架的组件之一。它负责从 Web 页面上下载数据。下载器使用 Scrapy 的下载器中间件来处理 HTTP 请求和响应。它可以执行多个请求,并且可以通过设置下载延迟来控制请求速度。下载器还支持代理、HTTP 加密和 cookie 管理等功能,可以帮助用户轻松地处理各种网络请求。
数据管道
数据管道是 Scrapy 框架的另一个组件。它负责处理爬虫从 Web 页面上收集到的数据。数据管道可以执行多个操作,例如验证数据、清理 HTML 数据和持久化数据。Scrapy 提供了一些默认的数据管道,但用户也可以创建自己的数据管道。
数据管道的主要作用是将从 Web 页面上收集到的数据进行处理,并将其保存到数据库或文件中。用户可以根据自己的需求来定义数据管道,以便更好地处理数据。
安装和使用 Scrapy
使用 Python 的包管理工具 pip 可以轻松地安装 Scrapy。在命令行中运行以下命令即可:
pip install scrapy
安装完成后,可以使用 scrapy 命令来创建新的 Scrapy 项目。下面是创建新项目的步骤:
- 在命令行中进入要创建项目的目录。
- 运行以下命令创建新项目:
scrapy startproject <project name>
此命令将创建一个名为 <project name> 的新 Scrapy 项目。项目的目录结构如下:
<project name>
|____ <project name>
|________ spiders
|____________ __init__.py
|________ __init__.py
|________ items.py
|________ middlewares.py
|________ pipelines.py
|________ settings.py
|____ scrapy.cfg
在这个结构中,<project name> 是你的项目名称。
创建新项目后,可以使用 scrapy genspider 命令创建新的蜘蛛程序。下面是创建新蜘蛛程序的步骤:
- 在命令行中进入项目的目录。
- 运行以下命令创建新蜘蛛程序:
scrapy genspider <spider name> <start url>
此命令将创建一个名为 <spider name> 的新蜘蛛程序,并指定一个起始 URL <start url>。
一个简单的例子
接下来,我们将实现一个爬取豆瓣电影 Top250 电影标题、评分和金句的爬虫。
定义 Item
首先,需要在 items.py 文件中定义一个 Item 类,该类将用于保存我们需要的数据。
import scrapy
class DoubanItem(scrapy.Item):
title = scrapy.Field()
score = scrapy.Field()
quote = scrapy.Field()
在这个例子中,我们定义了一个 DoubanItem 类,它包含三个字段:title、score 和 quote。这些字段对应着我们要爬取的数据。
编写蜘蛛程序
接下来,我们需要编写一个蜘蛛程序,用于从豆瓣电影网站上爬取数据。在 spiders 目录下创建一个新的 Python 文件,命名为 douban_spider.py,然后在文件中编写以下代码:
import scrapy
from ..items import DoubanItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = [
"<https://movie.douban.com/top250>"
]
def parse(self, response):
for movie in response.css(".item"):
item = DoubanItem()
item["title"] = movie.css(".title::text").get()
item["score"] = movie.css(".rating_num::text").get()
item["quote"] = movie.css(".quote span::text").get()
yield item
next_page = response.css(".next a::attr(href)").get()
if next_page is not None:
yield response.follow(next_page, self.parse)
在这个例子中,我们定义了一个名为 DoubanSpider 的蜘蛛程序。在 start_urls 中定义了起始 URL,然后使用 parse 方法解析响应,提取所需的数据。最后,使用 yield 语句返回一个 DoubanItem 对象,将数据保存到文件中。
运行爬虫程序
在完成以上步骤后,就可以运行蜘蛛程序了。在命令行中进入项目的目录,然后运行以下命令:
scrapy crawl douban -o douban.csv
此命令将启动 douban 蜘蛛程序,并将爬取到的数据保存到 douban.csv 文件中。
结论
Scrapy 是一个非常强大的 Python 框架,可以帮助用户轻松地从互联网上收集所需的数据。它具有高效、可扩展和灵活的架构,可以处理大量数据并提高数据爬取的效率。Scrapy 还有一个强大的社区,用户可以在社区中分享自己的经验和技巧,并获得其他用户的帮助和支持。如果你需要从互联网上收集数据,那么 Scrapy 是一个非常好的选择。
![[架构之路-165]-《软考-系统分析师》-4-据通信与计算机网络-1- 物理层通信](https://img-blog.csdnimg.cn/2fc65bdc628b4b17b568eb7ca22aecf7.png)