本文模拟的是前后端分离项目,使用账号密码登录获取到token,拿着token加载用户信息,加载分页列表数据并存储文件。
本文用到的知识点:
1、urllib.parse URL解析;
2、session用法,保存所有请求在一个会话中;取决于后台是否使用session传话保持;
3、requests请求,添加headers,data参数;
4、requests请求重定向获取重定向地址;
5、文件的写入;
创建Myspider 类,包含一个变量__token__和5个函数:
python">import json
import urllib.parse
import requests
from urllib.parse import urlparse
class MySpider:
__token__ = ''
def __init__(self, session):
self.session = session
def parseurlquery(self, str):
def login(self):
def initUserinfo(self):
def findContractPlan(self):
def moreInfo(self):
0 自定义工具函数:解析url参数
原格式:token=abcqowe222&a=123。
返回dict:{‘token’:‘abcqowe222’,‘a’:‘123’}
python"> def parseurlquery(self, str):
data = {}
d = str.split('&')
for q in d:
key, val = q.split('=')
data[key] = val
return data
1 login(self)模拟账号密码登录,获取通行凭证token
代码所示登录接口,访问后并非直接返回成功与失败,而是重定向到dict[‘service’]指向的地址并携带token作为参数。
python"> def login(self):
url = "http://localhost:81/sso/v2/userLogin.html"
dict = {'userName': 'louqun', 'passWord': '1', 'service': 'http://localhost:8088/#/home',
'authAppUUIDQX': '20171205112924314GXKKP'}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'localhost:81',
'Origin': 'http://localhost:81',
'Referer': 'http://localhost:81/sso/v2/loginUI.html?authAppUUIDQX=20171205112924314GXKKP&service=http%3A%2F%2Flocalhost%3A8088%2F%23%2Fhome',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'
}
#allow_redirects=False,禁用重定向,可以对比=True的时候返回的status_code、text、url。看差异
res = self.session.post(url=url, data=dict, allow_redirects=False)
# 获取重定向后的地址,并将url进行解析
urlData = urllib.parse.urlparse(res.headers['Location'], allow_fragments=False)
#自定义函数,将参数进行一步解析返回dict,从中获取token的值。并赋值给__token__变量
self.__token__ = self.parseurlquery(urlData.query).get('token')
urllib.parse.urlparse示例:
python">from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html;user?id=5#comment')
print(type(result))
print(result)
返回结果是一个 ParseResult 类型的对象,它包含 6 个部分,分别是 scheme、netloc、path、params、query 和 fragment。输出:
python"><class 'urllib.parse.ParseResult'>
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
2 加载用户信息,返回json对象
headers里面添加token,给请求添加header数据。
python"> def initUserinfo(self):
innerUserInfo = 'http://localhost:8088/momtcg-admin/v1/login/innerUserInfo?timestamp=1681135994738'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Host': 'localhost:8088',
'token': self.__token__,
'Origin': 'http://localhost:8088',
'Referer': 'http://localhost:8088/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'
}
res = self.session.get(innerUserInfo, headers=headers)
print(res.text)
#直接转为dict。
resultData = res.json()
3 加载列表数据未分页,将有用字段保存到文件
给post请求添加headers,data。我的接口需要将data用json.dump()转换为json字符串后,后台接口才能接收,否则会报错。应该和接口写法有关,没有深究。
python"> def findContractPlan(self):
findContractPlanList = 'http://localhost:8088/momtcg-admin/v1/contractSpecialPurchasePlan/findContractPlanList'
data = {
"regionalCompanyId": "",
"projectId": "",
"planStatus": "",
"projectByStage": "",
"contractName": "",
"pageFlag": 1,
"pageNumber": 1,
"pageSize": 10
}
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Host': 'localhost:8088',
'token': self.__token__,
'Origin': 'http://localhost:8088',
'Referer': 'http://localhost:8088/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'
}
res = self.session.post(findContractPlanList, headers=headers, data=json.dumps(data))
contractPlanResult = res.json()
print(contractPlanResult.get('data').get('list'))
with open('contractList.txt', 'w') as f:
for item in contractPlanResult.get('data').get('list'):
print(item.get('id'), item.get('regionalCompanyName'), item.get('projectName'),
item.get('contractCode'),
item.get('contractName'))
print(item)
f.write(str(item) + '\r')
return res.json()
4 加载分页列表
获取列表总数,计算总页数后,循环加载数据并按需写入文件;
python"> def moreInfo(self):
moreInfo = 'http://localhost:8088/momtcg-admin/v1/login/moreInfo'
data = {
"pageFlag": 1,
"pageNumber": 1,
"pageSize": 10,
"resultType": 3,
"msgTitle": ""
}
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Host': 'localhost:8088',
'token': self.__token__,
'Origin': 'http://localhost:8088',
'Referer': 'http://localhost:8088/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'
}
res = self.session.post(moreInfo, headers=headers, data=json.dumps(data))
moreInfoResult = res.json()
# 获取到数据总数
total = moreInfoResult.get('data').get('total')
pageSize = 10
pageNumber = 1
with open('moreInfo.txt', 'w') as f:
while True:
if pageSize * pageNumber > total:
break;
data.update({'pageNumber': pageNumber})
res = self.session.post(moreInfo, headers=headers, data=json.dumps(data))
print(res.text)
moreInfoResult = res.json()
if len(moreInfoResult.get('data').get('records')) == 0:
break;
else:
for item in moreInfoResult.get('data').get('records'):
print(item)
f.write(str(item) + '\r')
pageNumber += 1
5 方法调用
python">if __name__ == '__main__':
s = requests.Session()
spider = MySpider(s)
spider.login()
spider.initUserinfo()
spider.findContractPlan()
spider.moreInfo()
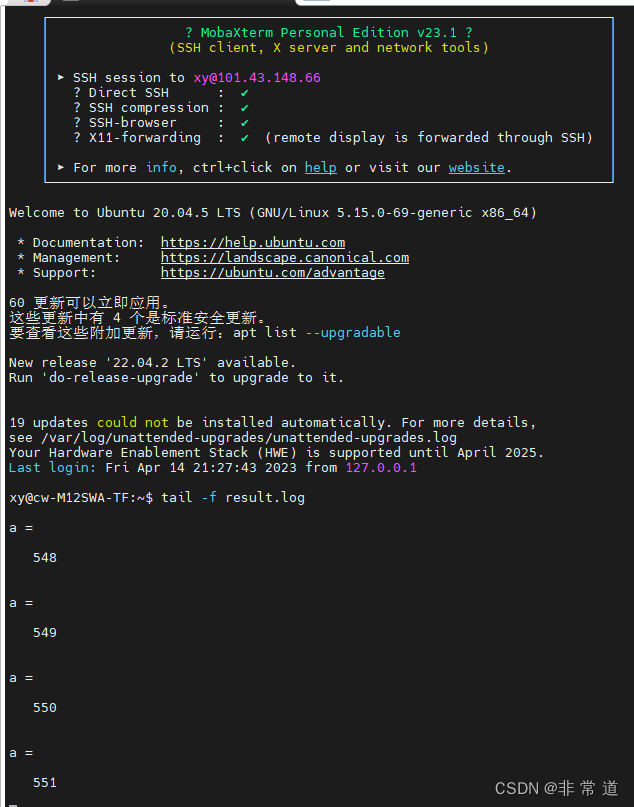
文本保存本地后效果: