目录
爬虫总览
准备工作
一、爬虫基础
1、爬虫前导
1.1、爬虫介绍
1.2、HTTP与HTTPS
1.3、URL
1.4、开发工具
1.5、爬虫流程
2、requests模块
2.1、简介
2.2、安装
2.3、发送请求
二、爬虫
爬虫总览
准备工作
一、爬虫基础
1、爬虫前导
1.1、爬虫介绍
-
概念:⽹络爬⾍是伪装成 客户端 与服务器进⾏数据交互的程序
⼝语化定义:⼀类⾃动采集互联⽹资源的程序
-
作⽤:
-
数据采集
-
搜索引擎
-
模拟操作爬⾍被⼴泛的应⽤于模拟⽤户操作,测试机器⼈,灌⽔机器⼈等
-
-
爬⾍开发难点:
-
数据获取 服务端会设置图灵测试,阻⽌爬⾍恶意爬取,开发爬⾍过程中,很⼤⼀部分⼯作处理反爬策略。
-
采集速度 多任务爬⾍和分布式爬⾍
-
1.2、HTTP与HTTPS
⽹络架构
-
c/s : client/server 客户端/服务端
-
b/s : brower/server 浏览器 服务端
-
m/s: mobile server 移动端 服务端

HTTP协议
-
原因:保证计算之间信息的有效交流,需要协议
-
概念:HTTP(Hyper Text Transfer Protocol) 超⽂本传输协议
HTTPS协议
https(Hyper Text Transfer Protocol over SecureSocketLayer)超文本安全协议,是HTTP+SSL,是以安全为⽬标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。
1.3、URL
通过URL对网络资源进行定位
URL(Uniform Resource Locator),中文叫统一资源定位符。是用来标识某一处资源的地址。也就是我们常说的网址。
协议+域名(端口默认80)+路径+参数
域名(Domain Name),⼜称⽹域,是由⼀串⽤点分隔的名字组成的Internet上某⼀台计算机或计算机组的名称,⽤于在数据传输时对计算机的定位标识 。由于IP地址具有不⽅便记忆并且不能显示地址组织的名称和性质等缺点,⼈们设计出了域名。
端⼝(Port),可以认为是设备与外界通讯交流的出⼝。端⼝可分为虚拟端⼝和物理端⼝,其中虚拟端⼝指计算机内部或交换机路由器内的端⼝,不可⻅;物理端⼝⼜称为接⼝,是可⻅端⼝。
路径(path),表示主机上的⼀个⽬录或者⽂件地址。

1.4、开发工具
通过快捷键fn+f12/f12启动/右击——检查启动

-
elements:⽹⻚源代码(最终⻚⾯渲染的结果)提取数据与分析数据
-
Console:打印内容
-
Sources:整个⽹站资料的来源
Network:⽹络⼯作(数据抓包),客户端与服务器之间交互的数据
1.5、爬虫流程
我们需要有一个第三方库来帮我们实现发送请求获取响应:
导⼊模块requests
python">pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple 1.目标url
-
静态加载
-
动态加载
2.模拟浏览器发送请求,接受响应
请求方式:
get: get⼀般⽤来获取服务器的信息的,查询参数⼀般会在URL上显示出来
post:post⼀般是⽤来更新信息。参数不会在URL显示出来
python">import requests
url = 'https://www.baidu.com/'
response = requests.get()
print(response) # 200状态码
-
200:请求成功
-
403:可能被识别是反爬的程序了
-
404:服务器找不到请求的⽹⻚
内容获取
-
response.text :返回字符串类型的数据
-
response.content:返回字节流数据(⼆进制)
-
response.content.decode('utf-8'):⼿动解码,获取字符串类型的数据
User-Agent:简称ua,是⼀种向访问⽹站提供你所使⽤的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识
Cookie:是某些⽹站为了辨别⽤户身份
Referer:防盗链,显示从那个url跳转过来的,确定请求来路。
2、requests模块
2.1、简介

Requests是⼀个优雅⽽简单的Python HTTP库,专为⼈类⽽构建。
Requests是有史以来下载次数最多的Python软件包之⼀,每天下载量超过400,000次。
之前的urllib做为Python的标准库,因为历史原因,使⽤的⽅式可以说是⾮常的麻烦⽽复杂的,⽽且官⽅⽂档也⼗分的简陋,常常需要去查看源码。与之相反的是,Requests的使⽤⽅式⾮常的简单、直观、⼈性化,让程序员的精⼒完全从库的使⽤中解放出来。
2.2、安装
在命令行窗口输⼊命令:
python">pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple2.3、发送请求
使⽤ Requests 发送⽹络请求⾮常简单。导包之后添加⽅法进⾏。
Requests的请求不再像urllib⼀样需要去构造各种Request、opener和handler,使⽤Requests构造的⽅法,并在其中传⼊需要的参数即可。
每⼀个请求⽅法都有⼀个对应的API,⽐如GET请求就可以使⽤get()⽅法,⽽POST请求就可以使⽤post()⽅法,并且将需要提交的数据传递给data参数即可,⽽其他的请求类型,都有各⾃对应的⽅法
发起请求的⽅法变得简单,我们只需要着重关注⼀下发起请求的参数 :
request源码
python">def request(url,params=None, headers=None, cookies=None,timeout=None,allow_redirects=True,proxies=None,verify=None, data=None,json=None): pass
httpbin.org
这个网站是用来做测试的,用来验证请求
python">{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39",
"X-Amzn-Trace-Id": "Root=1-643813dc-7be19f3e27c8a4696424b8cc"
},
"origin": "58.212.74.124",
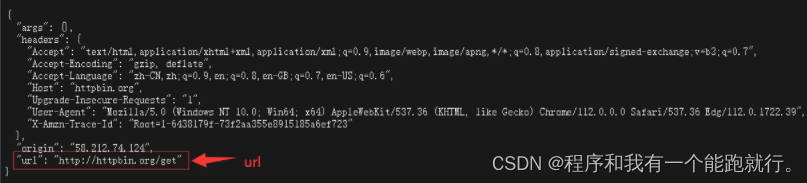
"url": "http://httpbin.org/get"
}(1)url
python">import requests
url='https://www.baidu.com/'
response = requests.get(url=url)
print(response)运行结果:
httpbin.org
(2)params
添加请求参数
传递URL参数也不⽤再像urllib中那样需要去拼接URL,⽽是简单的,构造⼀个字典,并在请求时将其传递给params参数,此时,查看请求的URL,则可以看到URL已经构造正确.
eg:
1.在url中直接添加参数
python">import requests
url = 'http://httpbin.org/get?key1=value1&key2=value2'
response = requests.get(url=url)
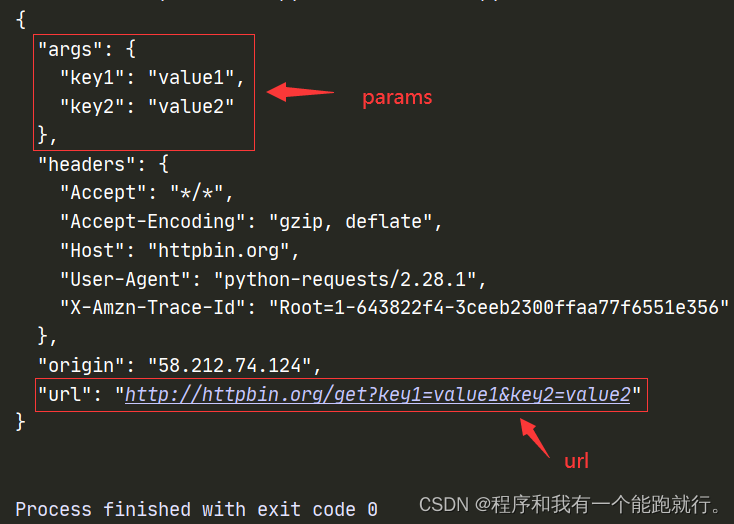
print(response.text)2.构造字典
python">import requests
url = 'http://httpbin.org/get'
params = {
'key1':'value1','key2':'value2'
}
response = requests.get(url=url,params=params)
print(response.text)运行结果:
(3)headers
添加请求头
如果想⾃定义请求的Headers,同样的将字典数据传递给headers参数。
通过添加请求头来伪造自己的身份

eg:
python">import requests
url = 'https://httpbin.org/get'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
print(response.text)运行结果:
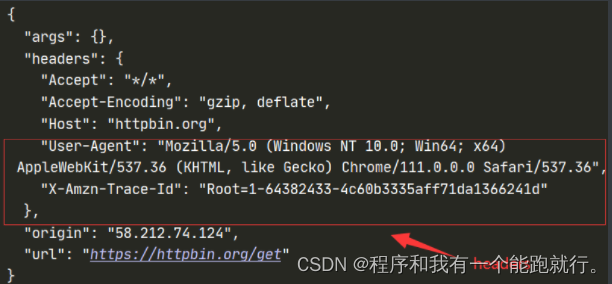
python">"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
# 携带的内容:操作系统、浏览器等(4)cookies
添加cookies
状态保持
储存用户身份
Requests中⾃定义Cookies也不⽤再去构造CookieJar对象,直接将字典递给cookies参数。
服务器是不记录用户信息的,为了让服务器能够识别用户,用户每次访问的时候就给它一个cookies,这个cookies保存在浏览器(本地电脑)。
eg:
1.在请求头中构造
python">import requests
url = 'https://httpbin.org/get'
headers={
"User-Agent": "",
'cookie': 'crawler',
'referer': 'crawler' # 防盗链
}
response = requests.get(url=url,headers=headers)
print(response.text)2.单独构造
python">import requests
url = 'https://httpbin.org/get'
headers={
"User-Agent": "crawler1"
}
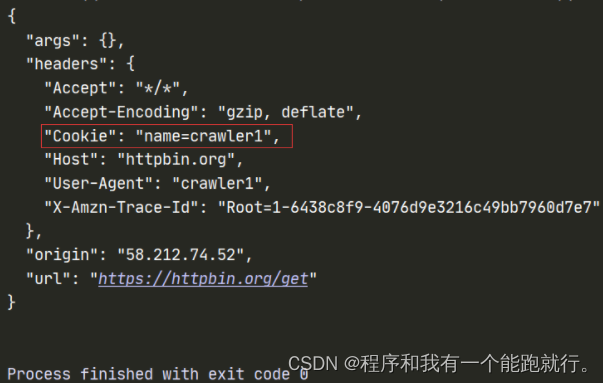
cookies = {'name':'crawler1' }
response = requests.get(url=url,headers=headers,cookies=cookies)
print(response.text)运行结果:
(5)timeout
设置超时时间
当访问超时,设置timeout参数即可。
python">import requests
url = 'http://www.baidu.com'
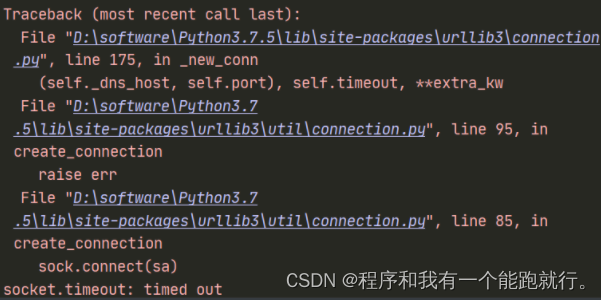
resp = requests.get(url, timeout=3)
print(resp.text)由于是国外的网站,访问会超时,会一直等待响应,这时我们设置超时时间,超时时间已过之后就会超时报错
运行结果:
(6)proxies
设置代理
当我们需要使⽤代理时,同样构造代理字典,传递给proxies参数。
请求端ip地址
eg:
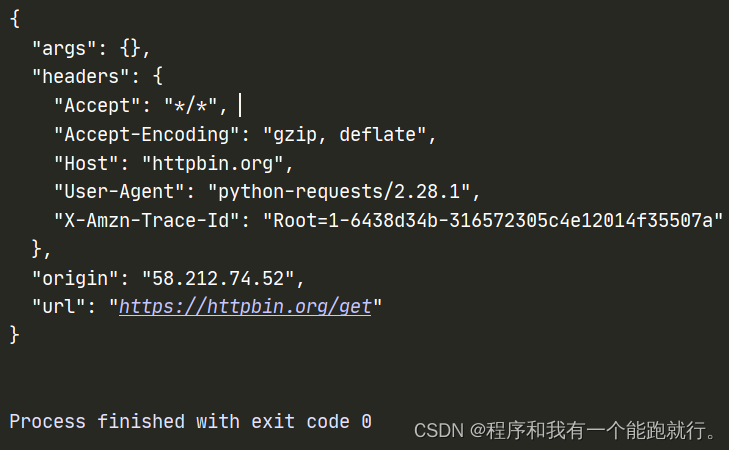
python">import requests
url = 'https://httpbin.org/get'
proxies = {
'http':'183.209.124.38:8088' # 代理ip
}
response = requests.get(url=url,proxies=proxies)
print(response.text)运行结果:
快代理 - 企业级HTTP代理IP云服务我这里使用的代理ip不可用,可以购买使用:快代理 - 企业级HTTP代理IP云服务
(7)verify
证书忽略验证
有时候我们使⽤了抓包⼯具,这个时候由于抓包⼯具提供的证书并不是由受信任的数字证书颁发机构颁发的,证书默认是开启的,所以证书的验证会失败,所以我们就需要关闭证书验证。在请求的时候把verify参数设置为False就可以关闭证书验证了。
eg:
python">import requests
url = 'https://httpbin.org/get'
response = requests.get(url=url,verify=False) # 出现警告
print(response.content.decode())运行结果:
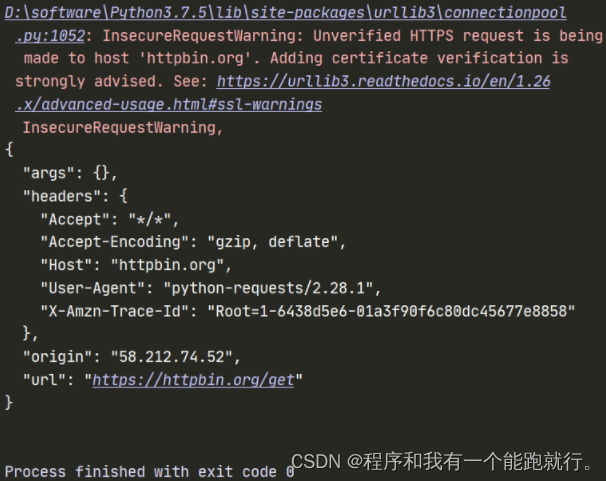
PS:关闭验证后,会有⼀个⽐较烦⼈的warning,当不影响运行的结果,关闭即可。
python">import warnings
warnings.filterwarnings("ignore")(8)data
携带数据
POST请求发送Form表单数据
eg:
python">import requests
url = 'http://httpbin.org/post'
data = {"name":"spider"}
resp = requests.post(url, data=data)
print(resp.text)运行结果:
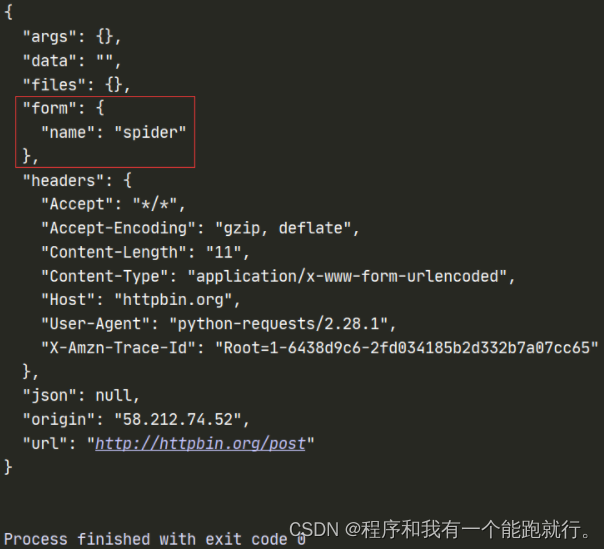
(9)
携带数据
eg:
python">url = 'https://httpbin.org/post'
data = {
'name':'crawler'
}
response = requests.post(url=url,json=data)
print(response.text)运行结果:
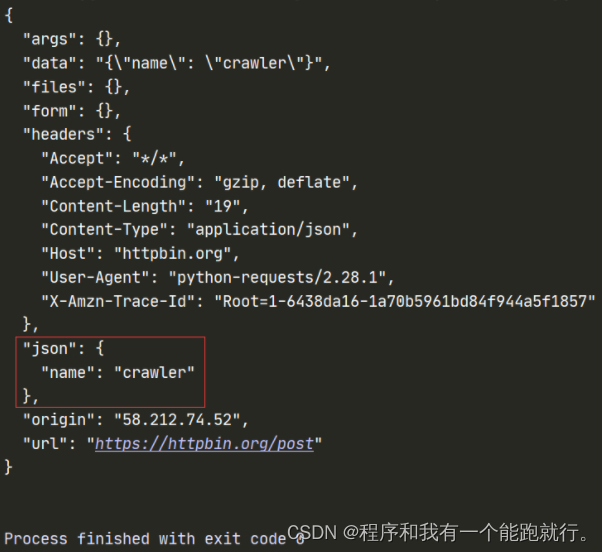
注意:
PS:json和data 不可以同时添加