前言
作为微调语言模型的一环,我们需要去网上搜集大量的文字资料,某网充满大量公开的高质量的问题和回答,适合用来训练。那么我们今天将下载它两年的热榜问题和回答。
思路
首先我们随便点进一个问题的回答,点击分享,复制链接。
发现链接构造如下:
https://www.zhihu.com/question/431730729/answer/1591942026
由一个question ID和answer ID构造而成的链接,那么引出以下问题:
1.question ID即问题的id,如何获得近两年热榜的所有问题id呢?
2.answer ID即回答的id,这个看起来像是所有的问题下的回答共享一个,没办法通过循环获取当前问题下的回答id。
3.有了这些id之后如何获取链接里面的文字?
准备
1.可以在github上找到定时爬取的热搜榜:
https://github.com/justjavac/zhihu-trending-hot-questions
从 2020-11-24 日开始,下载后解压,在archive文件夹下可以找到所有热搜的md文档。
2.安装需要的库
python">pip install beautifulsoup4
pip install lxml
3.规划代码
根据问题可以分为三部分:
第一部分从md文档里提取所有的热榜url链接。
第二部分根据热榜的url链接获取下面的回答链接。
第三部分根据问题和回答构造的唯一链接来获取页面内容。
代码
注意该代码默认存放位置在archive目录下以读取所有md文档的文件名。
python">from bs4 import BeautifulSoup
import json
import numpy as np
import requests
import os
import re
import time
#第一部分
headers = {
'content-type': 'text/html; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/111.0.0.0 Safari/537.36'}
arr = os.listdir()
print(arr)
list_total_question = []
for x in arr:
if x.endswith('.md'):
with open(x,'r',encoding='utf8') as hot_diary:
pattern = r'https://www.zhihu.com/question/(\d+)'
list_total_question+=re.findall(pattern, hot_diary.read())
print(len(list_total_question))
#第二部分
list_all_url = []
for x in list_total_question:
a1 = time.time()
url = 'https://www.zhihu.com/api/v4/questions/'+str(x)+'/feeds?'
datas = requests.get(url,headers=headers).json()
for info in datas['data']:
answerid = info['target']['id']
final_url = 'https://www.zhihu.com/question/'+x+'/answer/'+str(answerid)
list_all_url.append(final_url)
#break #每条问题默认提取五条问答,此处Break则只选默认排序第一条
a2 = time.time()
print(a2-a1) #0.5s
break #选一条问题进行测试
print(list_all_url)
#第三部分
list_json = []
for x in list_all_url:
html = requests.get(url=x, headers=headers)
site = BeautifulSoup(html.text, 'lxml')
title = site.find_all('meta', attrs={'itemprop': "name"}, recursive=True, limit=1)[0].__getattribute__('attrs')[
'content']
text = site.find('div', attrs={'class': "RichContent-inner"})
print(title)
total_string = ""
for i in text:
if i.text.find('.css') == -1:
total_string += i.text
dict_json = {"instruction":title,"input":"","output":total_string}
list_json.append(dict_json)
print(list_json)
爬取所有168500条热榜需要大概91000秒,提取信息还没测试,如果只是想简单看下效果可以添加break测试单条。代码中默认是提取了第一条问题的五条回答。 存文件的代码这里就不写了,很简单。
效果
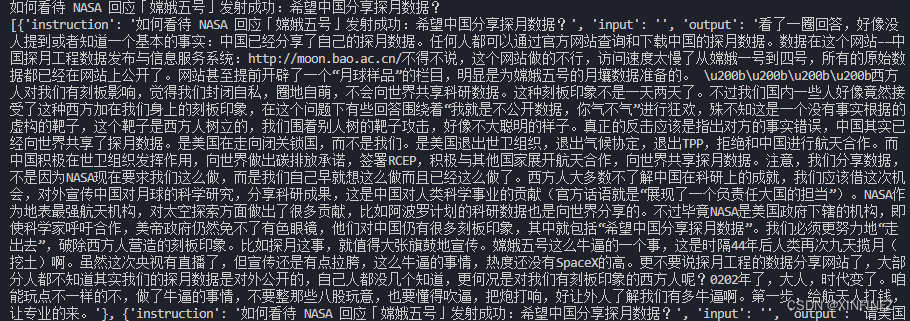
这里以json形式构造是为了接下来使用库来微调大语言模型,不需要的话自行去掉。