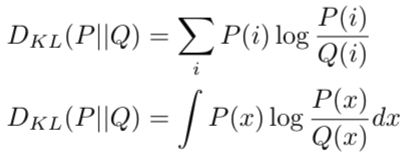Scrapy使用Request和Response对象来爬行网站。通常,Request对象是在爬虫中生成的,并在整个系统中传递,直到它们到达下载器,后者执行请求并返回一个Response对象,该对象返回发出Request的爬虫。
Request和Response类都有子类,这些子类添加了基类中不需要的功能。这些将在下面的Request子类和Response子类中进行描述
Request
scrapy.http.Request(*args, **kwargs)类,表示HTTP请求,该请求通常在爬虫中生成并由下载器执行,从而生成Response。scrapy.http.Request(*args, **kwargs)类接收以下参数:
url: 此请求的URL,str类型。如果该URL无效,则会引发ValueError异常|callback: 将使用此请求的响应作为其第一个参数来调用的函数,collections.abc.Callable类型method: 此请求的HTTP方法,str类型。默认为GETmeta:Request.meta熟悉的初始值,dict类型。如果给定,则将浅拷贝传入此dictbody: 请求主体。bytes或str类型headers: 此请求的标头, dict类型。注意:如果需要为请求设置cookie,请使用cookies参数cookies: 请求cookies, dict或list。
python">from scrapy.http import Request
# 使用DICT
request_with_cookies = Request(url='http://www.example.com',
cookies={'currency': 'USD', 'country': 'UY'})
# 使用LIST
request_with_cookies = Request(url='http://www.example.com',
cookies=[{
'name': 'currency',
'value': 'USD',
'domain': 'example.com',
'path': '/currency'
}])
List类型cookies允许自定义cookies的domain和path属性。这只在为以后得请求保存cookies时有用。
encondig: 此请求的编码,str类型。默认为utf-8priority: 此请求的优先级,int类型,默认为0dont_filter: 指示调度器不应筛选此请求,bool类型,默认为False。当您希望多次执行相同的请求时,可以使用此选项忽略重复的筛选器errback: 如果在处理请求时引发任何异常,则将调用该函数,这包括出现404错误等错误的页面,collections.abc.Callable类型。flags: 发送到请求的标志,可用于日志记录或类似用途,list类型cb_kwargs: 具有任意数据的dict,将作为关键字参数传递到请求的回调,dict类型。
Request除了接收上面这些参数之外,它还具有以下属性和方法:
url: 此请求的URL的字符串。此属性是只读的,如果想要更改请求的URL,请使用Request.replace()方法method: 表示请求中HTTP方法的字符串,而且是大写的,例如GET,POST等。headers: 包含请求头的类似字典的对象body: 以bytes表示的请求正文。此属性是只读的,要更改请求正文,请使用Request.replace()方法meta: 包含此请求的任意元数据的dict。cb_kwargs: 包含此请求的任意元数据的字典,它的内容将作为关键字参数传递给请求的回调copy(): 返回一个新的请求,它是此请求的副本。replace([url, method, headers, body, cookies, meta, flags, encoding, priority, dont_filter, callback, errback, cb_kwargs]): 返回一个具有相同成员的Request对象,但由指定的关键字参数赋予新值的成员除外。这个cb_kwargs和meta默认情况下,属性被浅复制classmethod from_curl(curl_command, ignore_unknown_options=True, **kwargs): 从包含cURL命令的字符串创建Request对象。它填充HTTP方法、URL、报头、Cookie和正文。它接受与Request类相同的参数,采用优先级并覆盖cURL命令中包含的相同参数的值to_dict(*, spider): 返回包含请求数据的字典
向回调函数传递附加数据
请求的回调是一个函数,在下载请求的响应时将调用该函数。将使用下载的Response对象作为其第一个参数。如下:
python">def parse_page_1(self, response):
return scrapy.Request('http://www.example.com/some_page.html',
callback=self.parse_page_2)
def parse_page_2(self, response):
self.logger.info(f'Visited {response.url}')
在某些情况下,你可能对向这些回调函数传递参数感兴趣,以便稍后在第二个回调中接收这些参数。下面的示例演示如何通过使用Request.cb_kwargs属性:
python">def parse_page_1(self, response):
request = scrapy.Request('http://www.example.com/some_page.html',
callback=self.parse_page_2,
cb_kwargs=dict(main_url=response.url))
request.cb_kwargs['foo'] = 'bar'
yield request
def parse_page_2(self, response, main_url, foo):
yield dict(main_url=main_url,
other_url=response.url,
foo=foo)
errback回调函数
errback是一个函数,在处理异常时将调用该函数。它收到一个Failure作为第一个参数,可用于跟踪连接建立超时、DNS错误等。如下:
python">import scrapy
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
def parse(self, response):
request = scrapy.Request('http://www.example.com/some_page.html',
callback=self.parse_page_1,
errback=self.parse_page_2,
cb_kwargs=dict(main_url=response.url))
yield request
def parse_page_1(self, response, main_url):
pass
def parse_page_2(self, failure):
if failure.check(HttpError):
response = failure.value.response
self.logger.error(f"HttpError on {response.url}")
elif failure.check(DNSLookupError):
request = failure.request
self.logger.error(f"DNSLookupError on {request.url}")
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error(f'TimeoutError on {request.url}')
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error('TimeoutError on %s', request.url)
Request子类
这些是内置的Request子类,您还可以将其子类化,以实现你自己的自定义功能
FormRequest
scrapy.http.FormRequest(url[, formdata, ...])类扩展了Request, 具有处理HTML表单的功能。它使用lxml.html.forms用来自Response对象的表单数据预填充表单字段。
这个FormRequest类将新的关键字参数添加到__init__方法。其余的参数与Request类相同,这里不作记录:
formdata: 包含HTML表单数据的字段(或可为(键、值)元组),这些数据将被URL编码并分配给请求主体。
FormRequest对象还支持以下类方法:
classmethod from_response(response, formname=None, formid=None, formnumber=0, formdata=None, clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs)
返回新的FormRequest对象,其表单字段值预填充在HTML中<form>包含在给定响应中的元素。默认情况下,策略是在任何看起来可点击的窗体控件上自动模拟单击,如<input type="submit">. 尽管这非常方便,而且通常是理想的行为,但有时它会导致难以调试的问题。例如,当处理使用javascript填写或/提交的表单时,默认的from_response()行为可能不是最合适的。要禁用这种行为,可以将dont_click参数设置为True。另外,如果你想改变控件点击(而不是禁用它),你也可以使用clickdata参数。
from_response()接收的参数详解如下:
response: 包含用于预填充表单字段的HTML表单响应,为一个Response对象formname: 如果给出,表单的name属性将设置为该值。str类型formid: 如果给出,表单的id属性将设置为该值。str类型formxpath: 如果给出,将使用与xpath匹配的第一个表单。str类型formcss: 如果给出,将使用与css匹配的第一个表单。str类型formnumber: 当response包含多个表单时要使用的第几个表单,第一个是0。int类型formdata: 要在表单数据中重写的字段,如果响应中已经存在字段<form>元素,其值将被此参数中传递的值重写。dict类型clickdata: 用于查找单击的控件的属性。如果没有给出,将提交表单数据,模拟单击第一个可单击元素。dict类型dont_click: 如果为True,则表单的数据将在不单击任何元素的情况下提交。bool类型
FormRequest使用如下:
python">import scrapy
def authentication_failed(response):
pass
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': 'john', 'password': 'secret'},
callback=self.after_login
)
def ater_login(self, response):
if authentication_failed(response):
self.logger.error('login failed')
return
JsonRequest
scrapy.http.JsonRequest(url[, ...,data, dumps_kwargs])类扩展了Request类,具有处理JSON请求的功能。这个FormRequest类将新的关键字参数添加到__init__方法。其余的参数与Request类相同,这里不作记录:
data: 是需要对JSON编码并分配给主体的任何JSON可序列化对象。如果Request.body提供了此参数,此参数将被忽略。如果Request.body未提供参数,并且提供了data参数,Request.method将被自动设置为POSTdumps_kwargs: 将传递给json.dumps()方法的参数,用于将数据序列化为JSON对象。dict类型
JsonRequest使用如下:
python">data = {
'name1': 'value1',
'name2': 'value2'
}
yield JsonRequest(url='http://www.example.com/post/action', data=data)
Response
scrapy.http.Response(*args, **kwargs)表示HTTP响应的对象,通常下载并提供给Spider进行处理。Response接收以下参数:
url: 此响应的URL,str类型status: 响应的HTTP状态,int类型, 默认为200headers: 此响应的头,dict类型body: 响应体,bytes类型flags: 是一个Response.flags属性初始值的列表,如果给定,将浅复制列表request:Response.request属性的初始值。这代表Request产生了这个响应certificate: 表示服务器的SSL证书的对象ip_address: 从哪个服务器发出的响应的IP地址protocol: 用于下载响应的协议,str类型。例如:“HTTP/1.0”、“HTTP/1.1”、“h2”
Response除了接收上面这些参数之外,它还具有以下属性和方法:
url: 包含响应的URL的字符串。此属性是只读的,要修改响应的URL,请使用replace()方法status: 表示响应的HTTP状态的整数。例子:200,404headers: 包含响应头的类似字典的对象。可以使用get()来访问具有指定名称的第一个头值,或者使用getlist()返回具有指定名称的所有头值。
python">response.headers.getlist('Set-Cookie')
body: 作为正文响应字节。此属性是只读的,要修改响应的body,请使用replace()方法request: 生成此响应的Request对象。在响应和请求通过所有Downloader中间件之后,在Scrapy引擎中分配此属性meta: 生成此响应的Request对象中的meta属性cb_kwargs: 生成此响应的Request对象中的cb_kwargs属性flags: 包含此响应标志的列表。flags是用于标记响应的标签,例如:‘cached’, 'redirect’等等certificate: 为一个twisted.internet.ssl.Certificate对象,用于表示服务器SSL证书的。仅为https响应填充,否则为Noneip_address: 表示从哪个服务器发出响应的IP地址protocol: 用于下载响应的协议。例如:“HTTP/1.0”、“HTTP/1.1”copy(): 返回此响应的副本的新响应replace([url, status, headers, body, request, flags, cls]): 返回具有相同成员的响应对象,除了那些通过指定的关键字参数赋予新值的成员。属性meta默认情况下是复制的urljoin(url): 通过将响应的url与可能的相对url组合起来构造一个绝对urlfollow(url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, cb_kwargs=None, flags=None): 返回一个Request实例来跟随一个链接url。它接受与Request相同的参数,但url可以是一个相对url或scrapy.link.Link对象,而不仅仅是一个绝对url.follow_all(urls, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, cb_kwargs=None, flags=None): 返回一个可迭代的Request实例,以跟踪url中的所有链接。它接受与Request相同的参数,但url可以是一个相对url或scrapy.link.Link对象,而不仅仅是一个绝对url.
Response子类
这些是内置的Response子类,您还可以将其子类化,以实现你自己的自定义功能
TextResponse
scrapy.http.TextResponse对象向基本Response类添加了编码功能,它仅用于二进制数据,如图像、声音或任何媒体文件。这个TextResponse类将新的关键字参数添加到__init__方法。其余的参数与Response类相同,这里不作记录:
encoding: 包含用于此响应的编码字符串。如果您创建了一个以字符串为body的TextResponse对象,它将被转换为使用这种编码方式编码的字节。如果encoding为None,则将在响应头和正文中查找编码。
TextResponse对象除了包含Response中的属性和方法之外,对象还支持以下属性和方法:
text: 字符串格式的响应体enconding: 响应编码的字符串selector: 使用响应作为目标的Selector实例xpath(query): xpath提取操作css(query): css提取操作json(): 将JSON文档反序列化为Python对象
HtmlResponse
scrapy.http.HtmlResponse为TextResponse的子类,它通过查找HTML元http-equiv属性添加了编码自动发现支持
XmlResponse
scrapy.http.XmlResponse为TextResponse的子类,它通过查找XML声明行添加了编码自动发现支持