Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
在之前的博文Scrapy常用工具命令中讲到,可以使用scrapy genspider -l来查看Scrapy当前可用的爬虫模板,并且已知现在可用的爬虫模板有basic、xmlfeed、csvfeed和crawl。在之前的博文中,所有有关爬虫的例子都使用basic模板,这里将不再作介绍,下面将着重介绍其他三种爬虫模板的使用。
使用XMLFeedSpider来分析XML源
如果想用Scrapy爬虫来处理XML文件,我们可以用XMLFeedSpider来实现。现在有这样一个XML的数据源:http://www.people.com.cn/rss/politics.xml,假如,我们想提取XML文件中的各文章的标题,作者以及发布日期等信息,首先我们在原来的项目上创建一个xmlfeed为模板的爬虫:
scrapy genspider peoplespider -t xmlfeed www.people.com.cn
执行完上面的命令,会发现在原来的spiders目录下多了一个peoplespider.py的爬虫文件。用编辑器打开该爬虫文件,有如下内容:
python"># -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
class PeoplespiderSpider(XMLFeedSpider):
name = 'peoplespider'
allowed_domains = ['www.people.com.cn']
start_urls = ['http://www.people.com.cn/feed.xml']
iterator = 'iternodes' # you can change this; see the docs
itertag = 'item' # change it accordingly
def parse_node(self, response, selector):
i = {}
#i['url'] = selector.select('url').extract()
#i['name'] = selector.select('name').extract()
#i['description'] = selector.select('description').extract()
return i
首先我们需要理解一下上述代码,关于name、allowed_domains和start_urls属性在之前的博文中已有讲到,具体作用情况请查看上一篇博文。下面主要讲讲iterator、itertag和parse_node()属性或方法的使用:
iterator: 该属性设置的是使用哪个迭代器,默认值为iternodes,这是一个基于正则表达式的高性能迭代器,除了这个默认值以外,还可以设置为html或xmlitertag: 该属性主要用来设置开始迭代的节点parse_node(): 该方法在节点与所提供的标签名相符合的时候会被调用,在该方法中,可以进行一些信息的提取和处理的操作
除此之外,XMLFeedSpider还有一些常见的属性和方法,如下所示:
| 名称 | 属性或方法 | 含义 |
|---|---|---|
| namespaces | 属性 | 以列表的形式存在,主要定义在文档中会被爬虫处理的可用命名空间 |
| adpt_response(response) | 方法 | 该方法主要在spider分析响应前被调用 |
| process_results(response, results) | 方法 | 该方法主要在spider返回结果时被调用,主要对结果在返回前进行最后处理 |
随后,我们再创建一个属于peoplespider爬虫的items文件people_items.py,定义要存储的结构化数据,具体代码如下:
python">import scrapy
class PeopleItems(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
要提取文章的标题,作者和发布日期,我们需要对该XML文件进行分析。下面,我们将peoplespider.py的爬虫文件进行修改,具体代码如下:
python"># -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
from myfirstspider.people_itms import PeopleItems
class PeoplespiderSpider(XMLFeedSpider):
name = 'peoplespider'
allowed_domains = ['www.people.com.cn']
start_urls = ['http://www.people.com.cn/rss/politics.xml']
iterator = 'iternodes' # you can change this; see the docs
# 设置开始迭代的节点,一般设置为文档的第一个节点
itertag = 'rss' # change it accordingly
def parse_node(self, response, selector):
item = PeopleItems()
item["title"] = selector.xpath("/rss/channel/item/title/text()").extract()
item["author"] = selector.xpath("/rss/channel/item/author/text()").extract()
item["date"] = selector.xpath("/rss/channel/item/pubDate/text()").extract()
for i in range(len(item["title"])):
print("文章的标题为:{},作者为:{},发布日期为:{}".format(item["title"][i], item["author"][i], item["date"][i]))
return item
然后,执行该爬虫scrapy crawl peoplespider --nolog,运行的结果如下所示:
文章的标题为:汪洋会见海协会第四届理事会第一次会议全体代表,作者为:人民网,发布日期为:2018-04-27
...
可以看到,此时成功爬取了该网页对应的信息。
使用CSVFeedSpider来分析CSV源
使用爬虫不仅能够处理XML文件的数据,还能够处理CSV文件的数据。CSV文件是一种被用户广泛应用的相对简单、通用的文件格式,器存储的数据可以轻松的与表格数据互相转化。例如有这样一个CSV文件,如图所示:

为了方便测试,我先将此CSV文件传入Web项目服务器中,传入后的地址为:http://192.168.10.10/get_file/test.csv。然后,我们在原来的项目上,创建一个以CSVFeedSpider为模板的爬虫:
scrapy genspider csvspider -t csvfeed 192.168.10.10
执行完上面的命令,会发现在原来的spiders目录下多了一个csvspider.py的爬虫文件,用编辑器打开该文件,将会有如下内容:
python"># -*- coding: utf-8 -*-
from scrapy.spiders import CSVFeedSpider
class CsvspiderSpider(CSVFeedSpider):
name = 'csvspider'
allowed_domains = ['192.168.10.10']
start_urls = ['http://192.168.10.10/feed.csv']
# headers = ['id', 'name', 'description', 'image_link']
# delimiter = '\t'
# Do any adaptations you need here
#def adapt_response(self, response):
# return response
def parse_row(self, response, row):
i = {}
#i['url'] = row['url']
#i['name'] = row['name']
#i['description'] = row['description']
return i
首先我们需要理解一下上述代码,关于name、allowed_domains和start_urls属性在之前的博文中已有讲到,具体作用情况请查看上一篇博文。代码中headers属性主要存放在CSV文件中包含的用于提取字段的行信息的列表。delimiter属性主要存放字段之间的间隔符,parse_row()方法主要用来接收一个response对象,并进行相应的处理。
观察上面CSV文件,可以得知,该文件具有三个重要属性,name、age和addr,现在我们需要一个容器将这些数据装起来。下面我们创建一个该CSV爬虫的容器文件csv_items.py,具体代码如下:
python">import scrapy
class CSVItems(scrapy.Item):
name = scrapy.Field()
age = scrapy.Field()
addr = scrapy.Field()
容器中定义了name、age、addr信息,分别对应我们需要爬取的name、age和addr,下面我们将csvspider.py文件进行修改一下:
python">from scrapy.spiders import CSVFeedSpider
from myfirstspider.csv_items import CSVItems
class CsvspiderSpider(CSVFeedSpider):
name = 'csvspider'
allowed_domains = ['192.168.10.10']
start_urls = ['http://192.168.10.10:5000/get_file/test.csv']
headers = ['name', 'age', 'addr']
delimiter = ','
def adapt_response(self, response):
response = response.replace(encoding="gbk")
return response
def parse_row(self, response, row):
item = CSVItems()
item["name"] = row["name"]
item["age"] = row["age"]
item["addr"] = row["addr"]
print(item["name"], item["age"], item["addr"])
return item
运行该爬虫,得到的结果如下所示:
name age addr
张三 18 江西赣州
李四 19 江西南昌
王五 21 广东广州
刘六 20 广东深圳
赵七 18 广东佛山
值得注意的是,我在adapt_response()做了一步进行转码的操作,是因为我的CSV文件中包含了中文,没有这步转码操作,我输出的中文信息变成了乱码。如果有遇到CSV爬虫在爬取过程中,遇到中文乱码问题,可以像我一样尝试进行一下响应流转码。
CrawlSpider的使用
CrawlSpider与之前使用的几种爬虫模板都不太一样,我们要学会使用CrawlSpider,就必须先了解CrawlSpider的工作流程,CrawlSpider的主要工作流程如下所示:
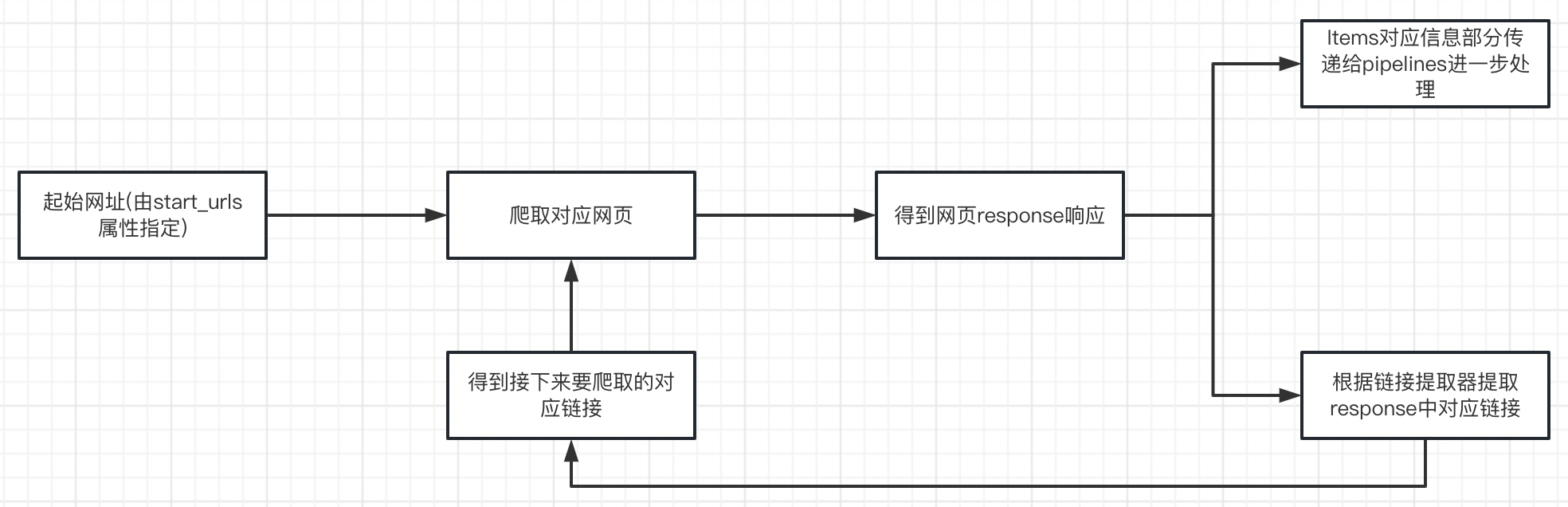
可以看到,CrawlSpider爬虫会根据链接提取器中设置的规则自动的提取符合条件的网页链接,提取之后再自动对这些链接进行爬行,行程一个循环,如果链接设置为跟进,则会一直循环下去,如果链接设置为不跟进,则第一次循环后就会断开,链接是否跟进可以通过rules中的follow参数的值为True表示跟进,否则表示不跟进,基于爬虫模板创建CrawlSpider后,默认情况为跟进链接。
我们仍然以我的博客为例,创建一个爬虫项目来爬取博客信息。
scrapy startproject blog --nolog
创建好项目之后,我们需要编写爬虫项目中的items.py文件,加入我们想提取博客的标题、阅读数量和发布时间,可以将items.py文件修改为如下所示:
python">import scrapy
class BlogItem(scrapy.Item):
title = scrapy.Field()
page_views = scrapy.Field()
published_date = scrapy.Field()
然后我们再创建一个名为blog的CrawlSpider,如下:
scrapy genspider -t crawl blog csdn.net --nolog
创建完爬虫文件之后,就开始在爬虫文件中编写相关的代码了,blog.py修改后如下:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sport.items import BlogItem
class NewsSpider(CrawlSpider):
name = "news"
allowed_domains = ["csdn.net"]
start_urls = ["https://blog.csdn.net/y472360651"]
rules = (
# 此url为翻页链接的正则匹配
Rule(LinkExtractor(allow=r'/article/list/\d+'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = BlogItem()
res = response.xpath(
'//*[@id="articleMeList-blog"]/div[2]/div/h4/a/text()').extract()
item['title'] = []
for i in res:
i = i.replace('\n', '').replace(' ', '')
if i:
item['title'].append(i)
item['page_views'] = response.xpath(
'//*[@id="articleMeList-blog"]/div[2]/div/div[1]/p/span[2]/text()').extract()
item['published_date'] = response.xpath(
'//*[@id="articleMeList-blog"]/div[2]/div/div[1]/p/span[1]/text()').extract()
print(item)
return item
由代码可以看出,CrawlSpider主要是通过LinkExtractor链接提取器来实现链接的过滤和提取,以实现翻页自动爬取的效果。其中LinkExtractor中对应的参数及含义如下:
| 参数名 | 参数含义 |
|---|---|
| allow | 提取符合正则表达式的链接 |
| deny | 不提取符合正则表达式的链接 |
| restrict_xpaths | 使用XPath表达式与allow共同作用提取同时符合对应XPath表达式和对应正则表达式的链接 |
| allow_domains | 允许提取的域名,比如我们想只提取某个域名下的链接时会用到 |
| deny_domains | 进制提取的域名 |