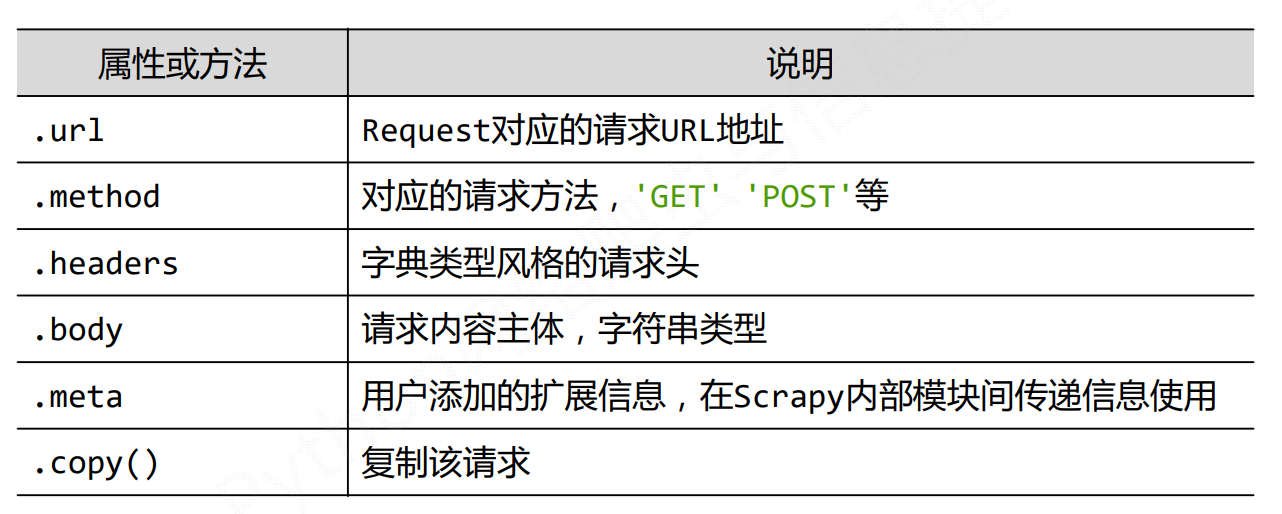
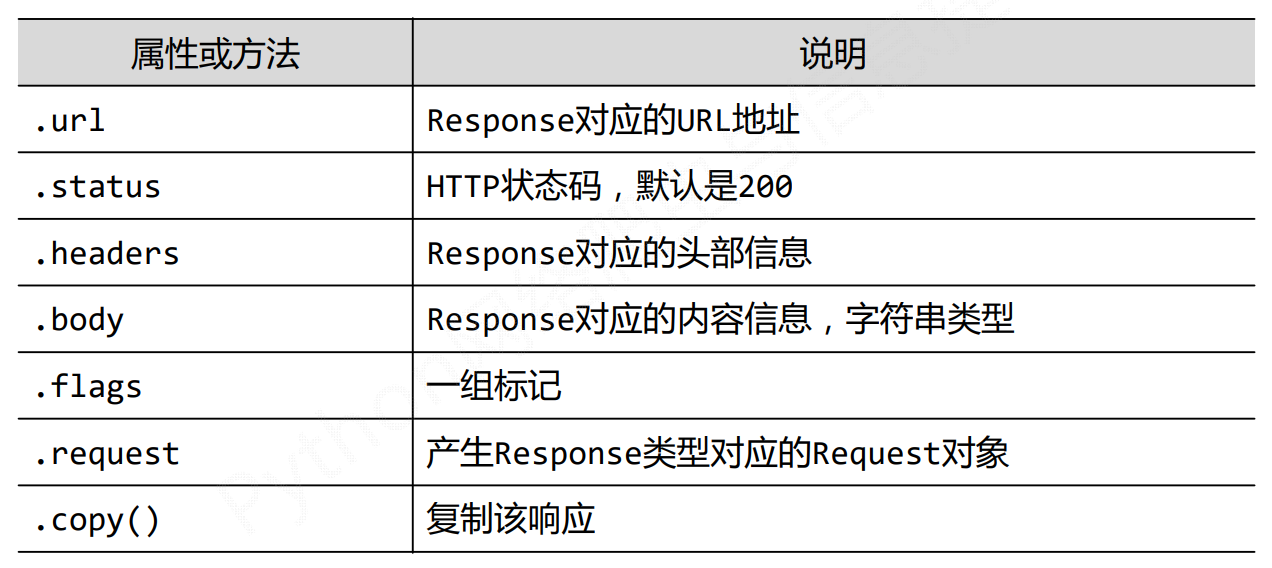
Scrapy爬虫的常用命令
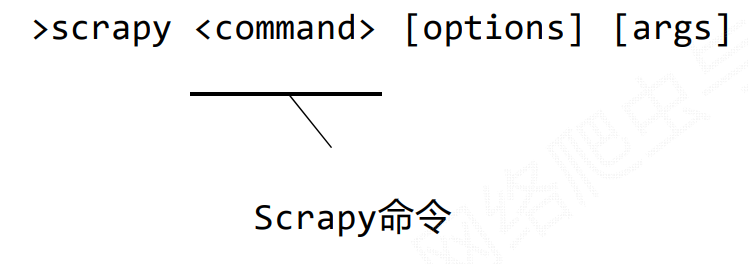
scrapy命令行格式
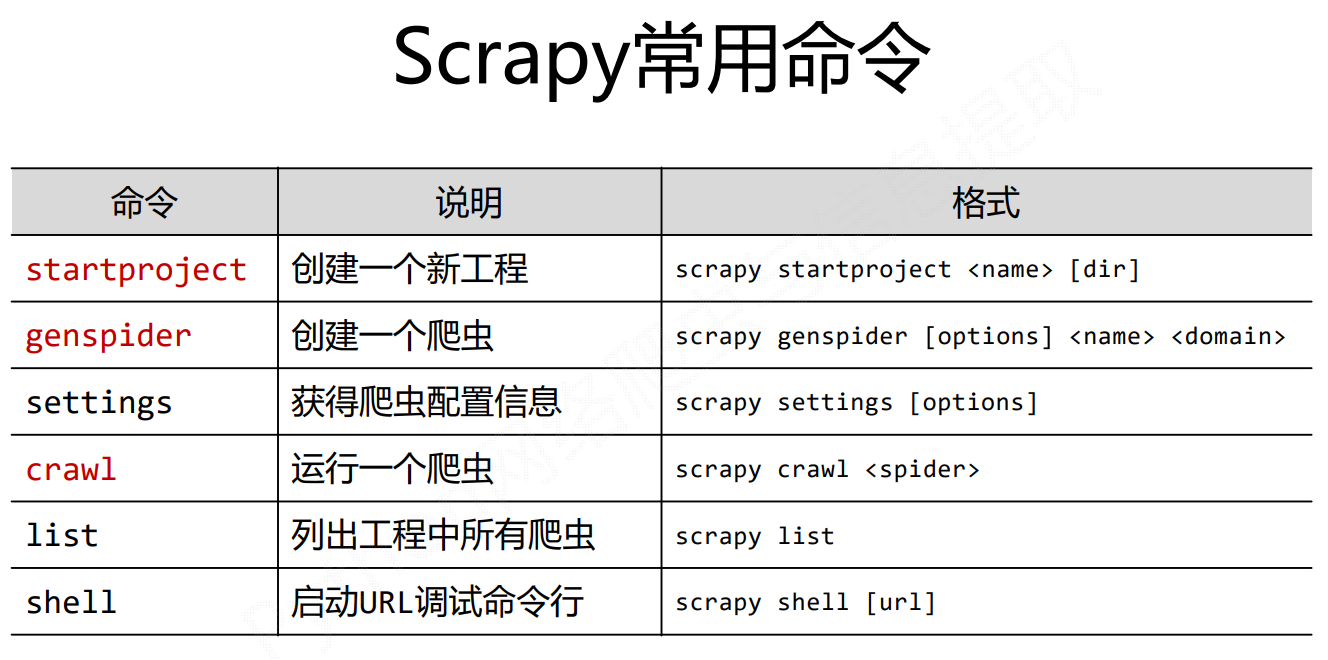
红色是常用的三种命令
为什么Scrapy采用命令行创建和运行爬虫?
命令行(不是图形界面)更容易自动化,适合脚本控制 本质上,Scrapy是给程序员用的,功能(而不是界面)更重要
Scrapy爬虫的基本使用
应用Scrapy爬虫框架主要是编写配置型代码
步骤1:建立一个Scrapy爬虫工程
选取一个目录,然后执行如下命令
scrapy startproject python123demo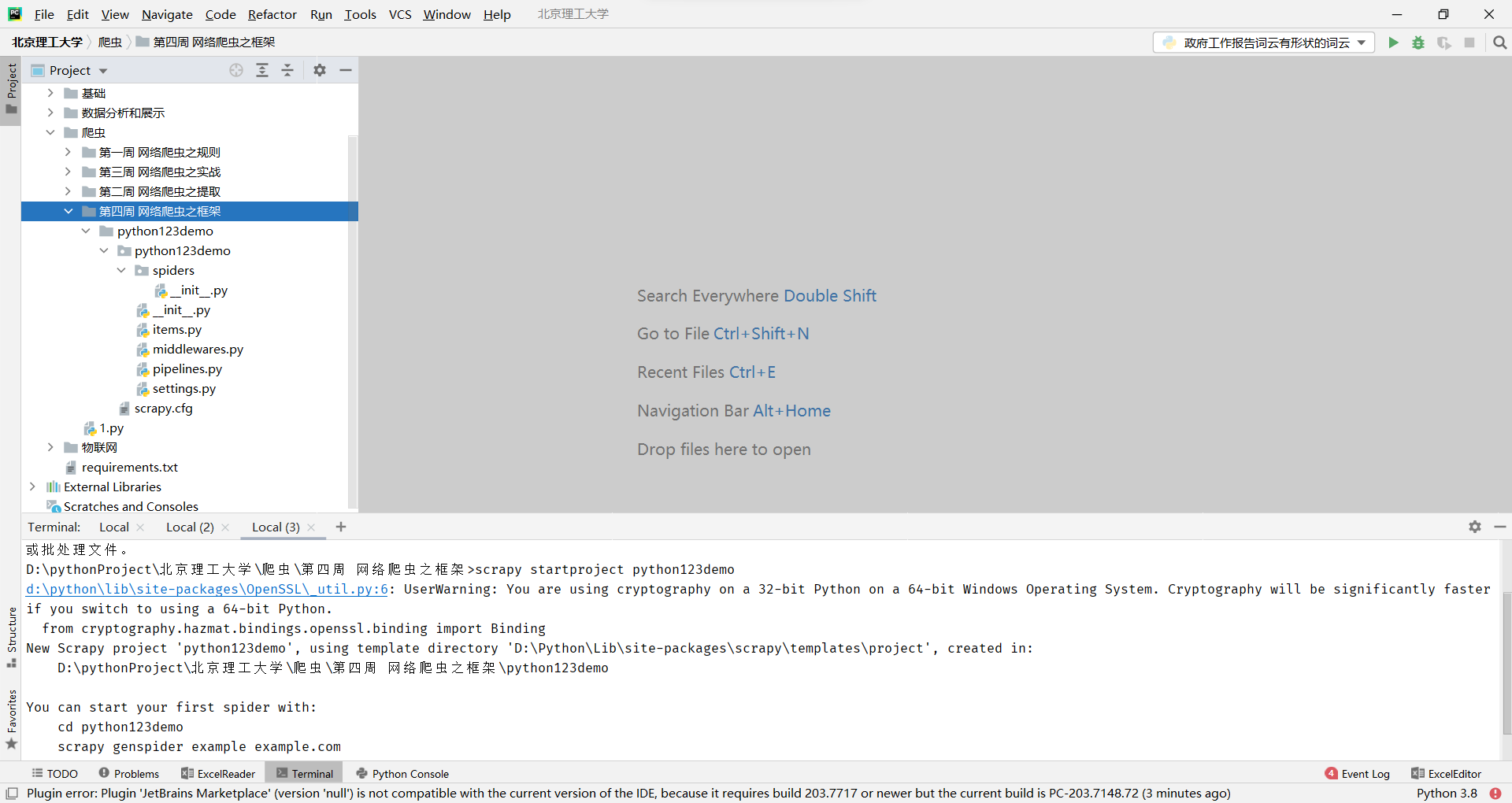

 步骤2:在工程中产生一个Scrapy爬虫
步骤2:在工程中产生一个Scrapy爬虫
在工程中产生一个Scrapy爬虫,只需要执行一条命令就可以了,但这个命令是需要约定用户给定的爬虫的名字以及爬取的网站
进入工程目录,然后执行如下命令:
scrapy genspider demo python123.io这条命令指的是生成一个名称为demo的spider
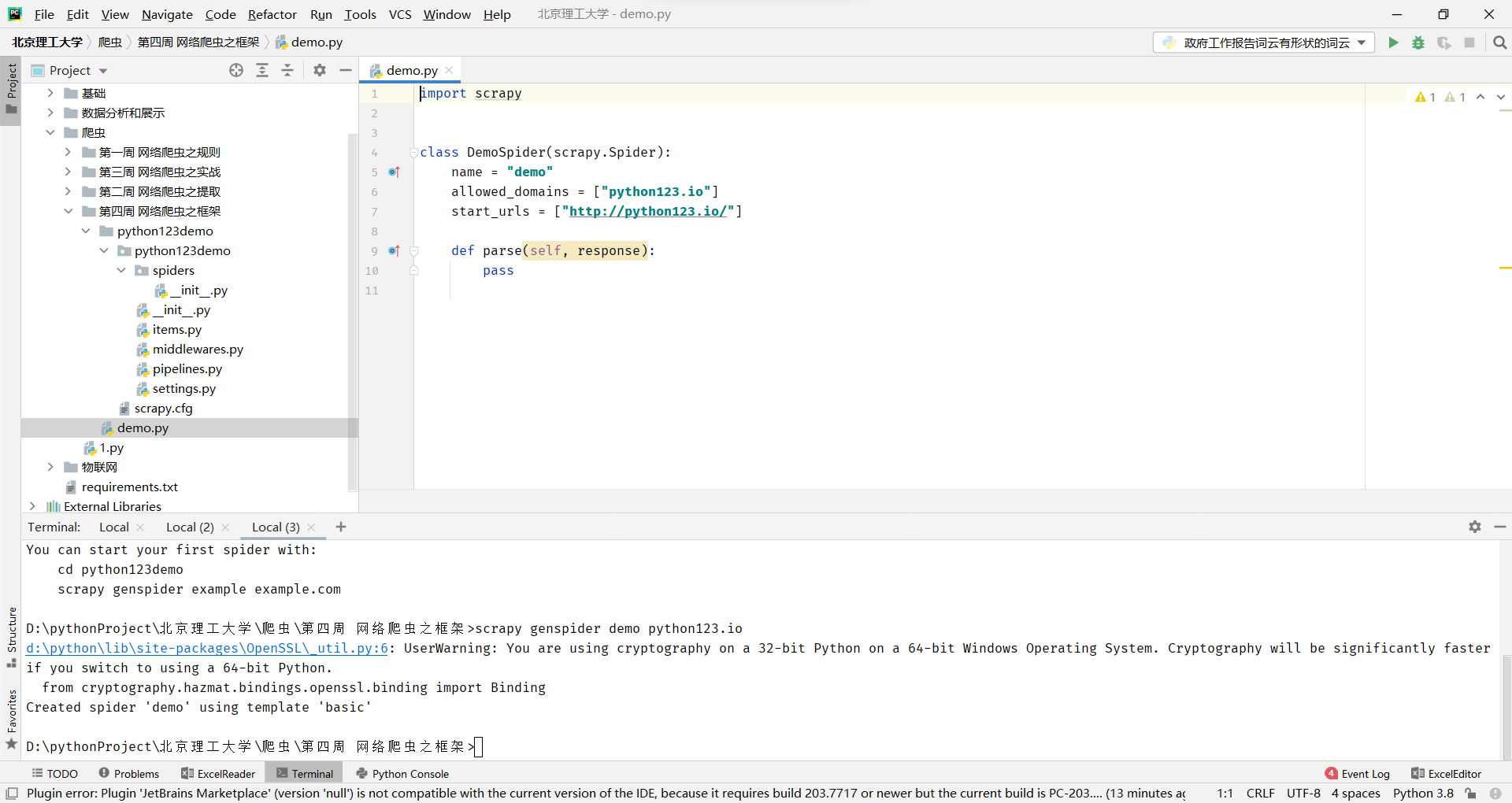
当然,我们也可以手动的生产
name = "demo" 爬虫的名称
allowed_domains = ["python123.io"] 最开始用户提交给命令行的域名,指的是爬虫在爬取网站的时候,它只能爬取这个域名以下的相关链接
start_urls = ["http://python123.io/"] 以列表形式包含的一个或多个域名就是scrapy框架所要爬取页面的初始页面
def parse(self, response):parse()用于处理响应,解析内容形成字典, 发现新的URL爬取请求
 步骤3:配置产生的spider爬虫
步骤3:配置产生的spider爬虫
配置:(1)初始URL地址 (2)获取页面后的解析方式
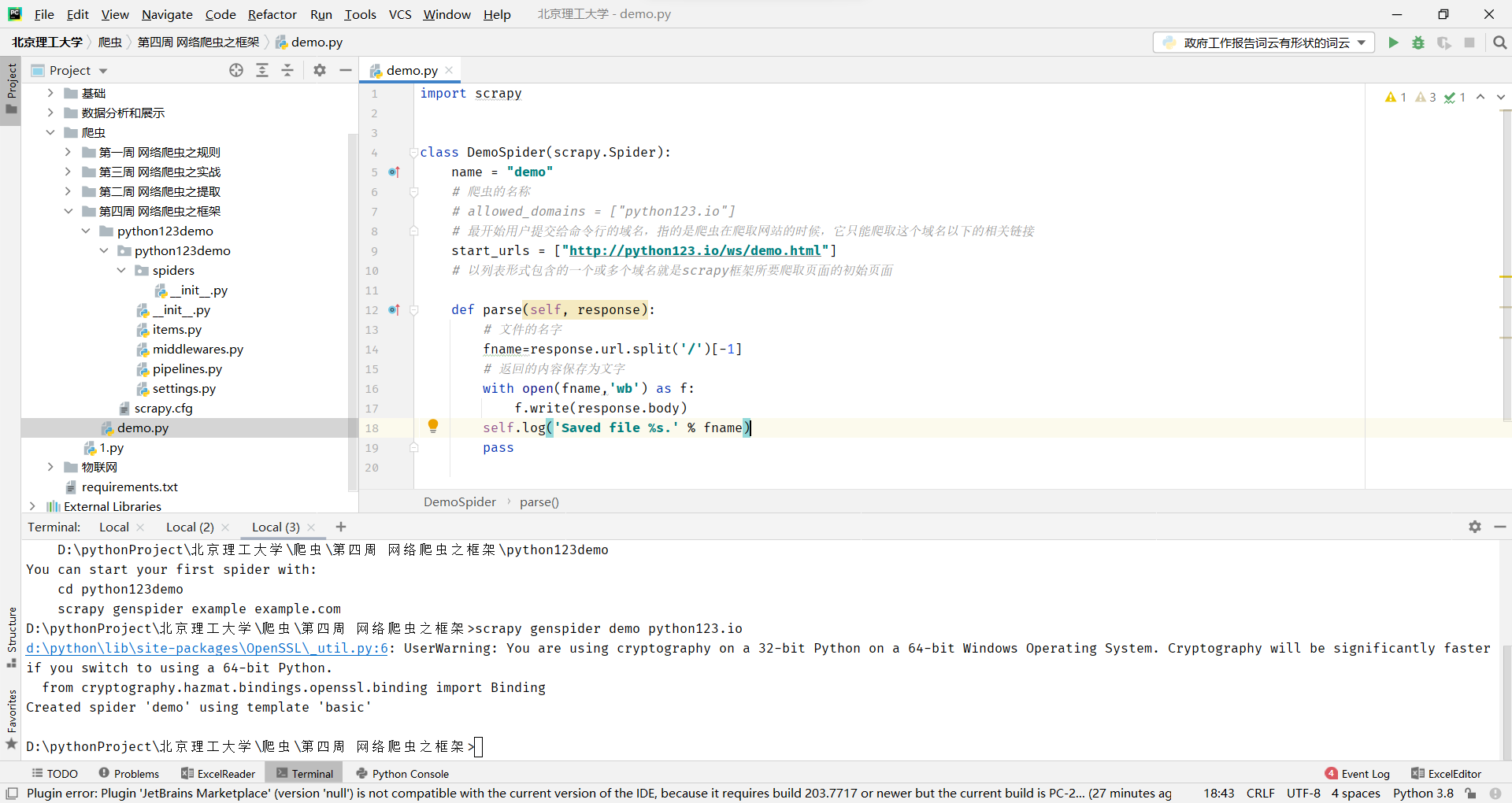
步骤4:运行爬虫,获取网页 在命令行下,执行如下命令:
scrapy crawl demo这里一定要注意:把目录切换到当前目录下,因为它要执行demo.py命令
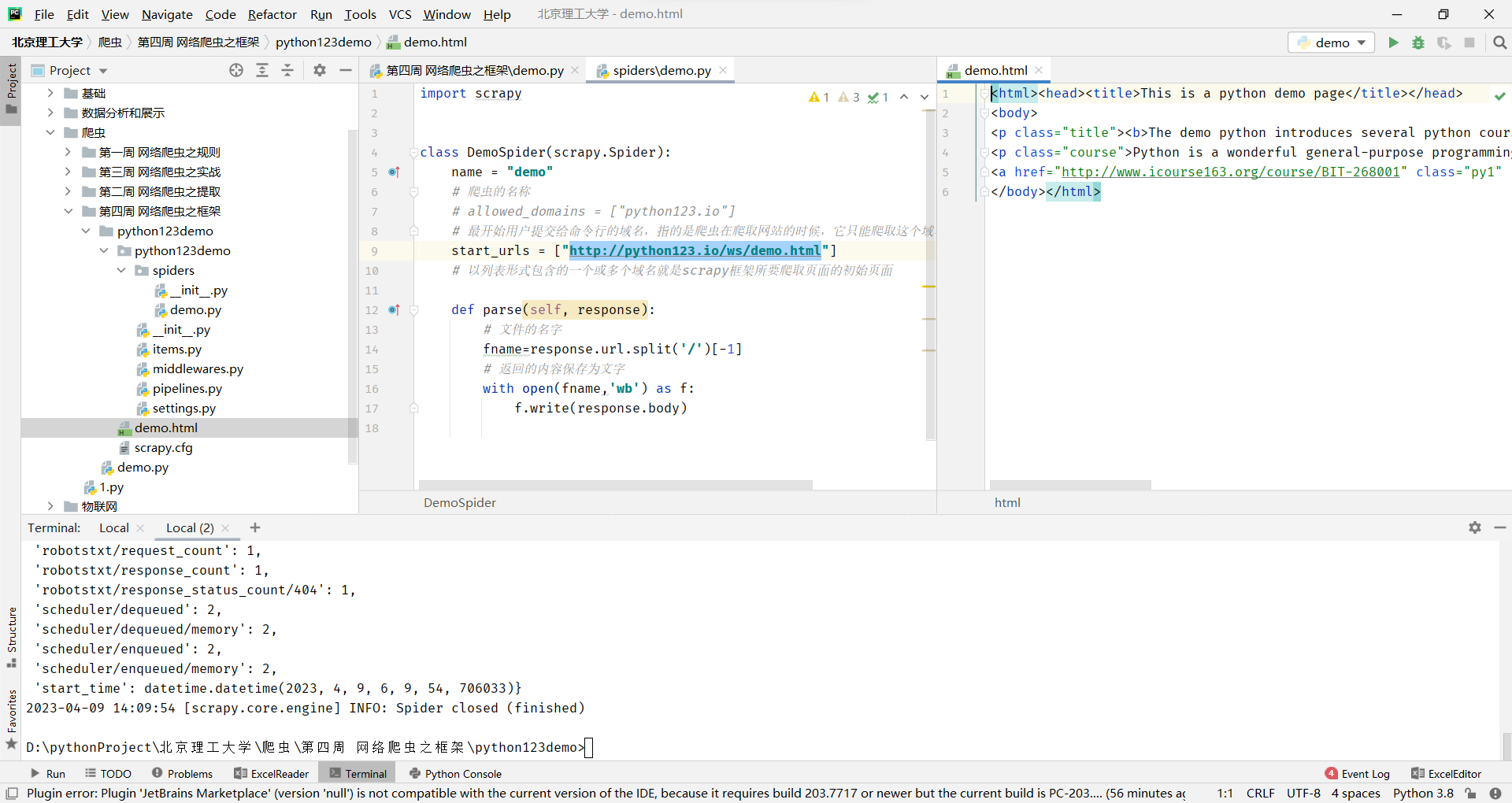
这里,还要注意的一点:就是一定要在spiders目录下的demo.py文件下写
运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。 之后当前文件夹中就出现了一个 demo.html 文件,里面就是我们刚刚要爬取的网页的全部源代码信息。


yield关键字的使用

 按照生成器的说法,它首先执行for循环,然后执行到yield这行语句的时候,这个函数就会被冻结,而当前yield对应的那一行产生值会被返回出来,所以这个函数在调用的时候,它会首先产生一个值,这个值就是当i等于0的时候的值的平方值,之后会逐渐遍历这个循环
按照生成器的说法,它首先执行for循环,然后执行到yield这行语句的时候,这个函数就会被冻结,而当前yield对应的那一行产生值会被返回出来,所以这个函数在调用的时候,它会首先产生一个值,这个值就是当i等于0的时候的值的平方值,之后会逐渐遍历这个循环 
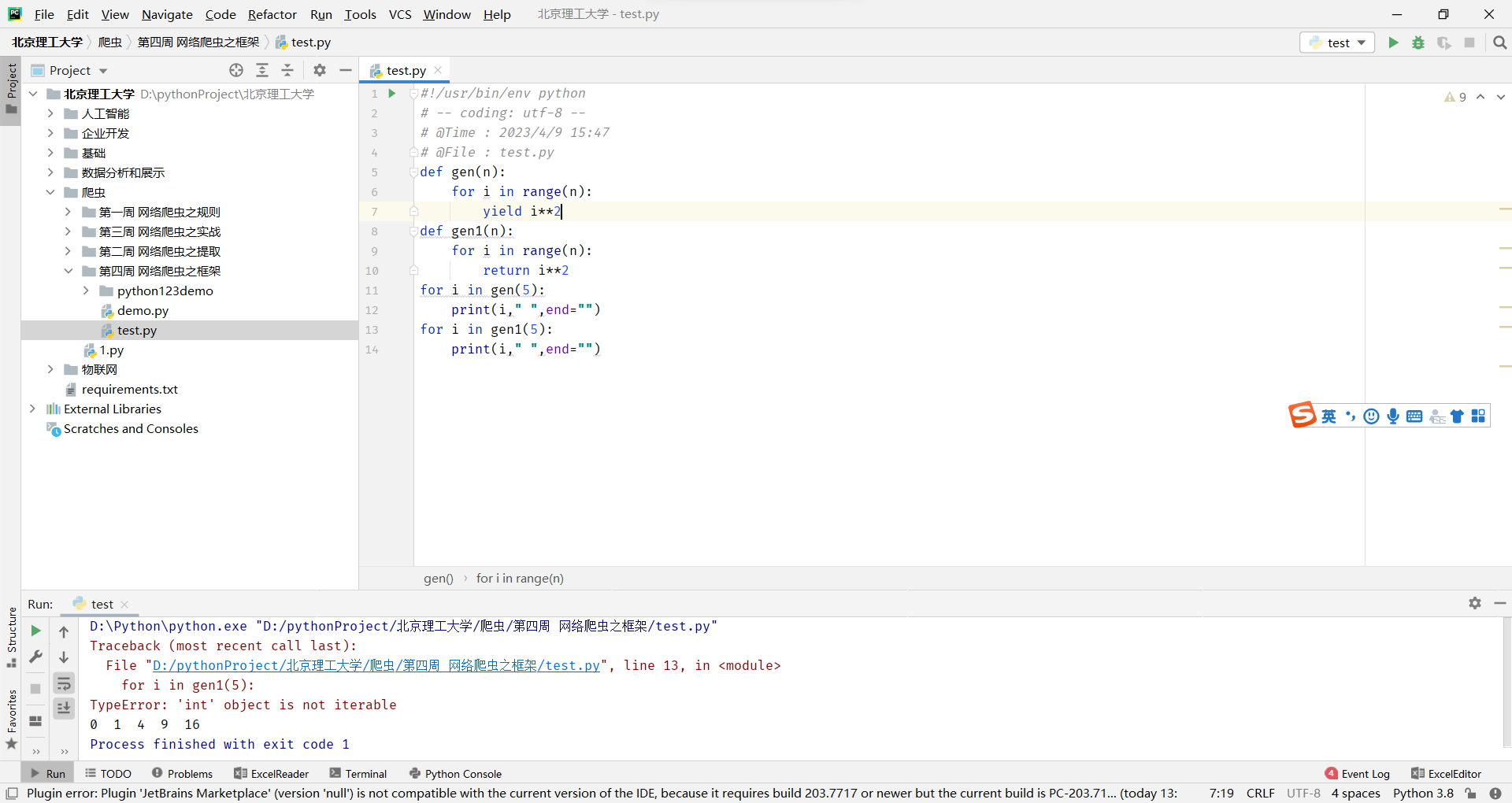
使用yield关键字 就不会报错,而使用return只能执行一次,报错。yield可以一次性的唤醒所有的数值

好处就是如果我们使用原生的办法,我们需要将这些数据全都统计出来,很占空间,而yield只占用一个元素的空间
Scrapy爬虫的基本使用

Scrapy爬虫数据类型





股票数据Scrapy爬虫
功能描述
目标:获取上交所和深交所所有股票的名称和交易信息 输出:保存到文件中
数据网站的确定
获取股票列表:
行情中心:国内快捷全面的股票、基金、期货、美股、港股、外汇、黄金、债券行情系统_东方财富网
行情中心_股市行情_最新股市行情_股市走势-雪球 (xueqiu.com)
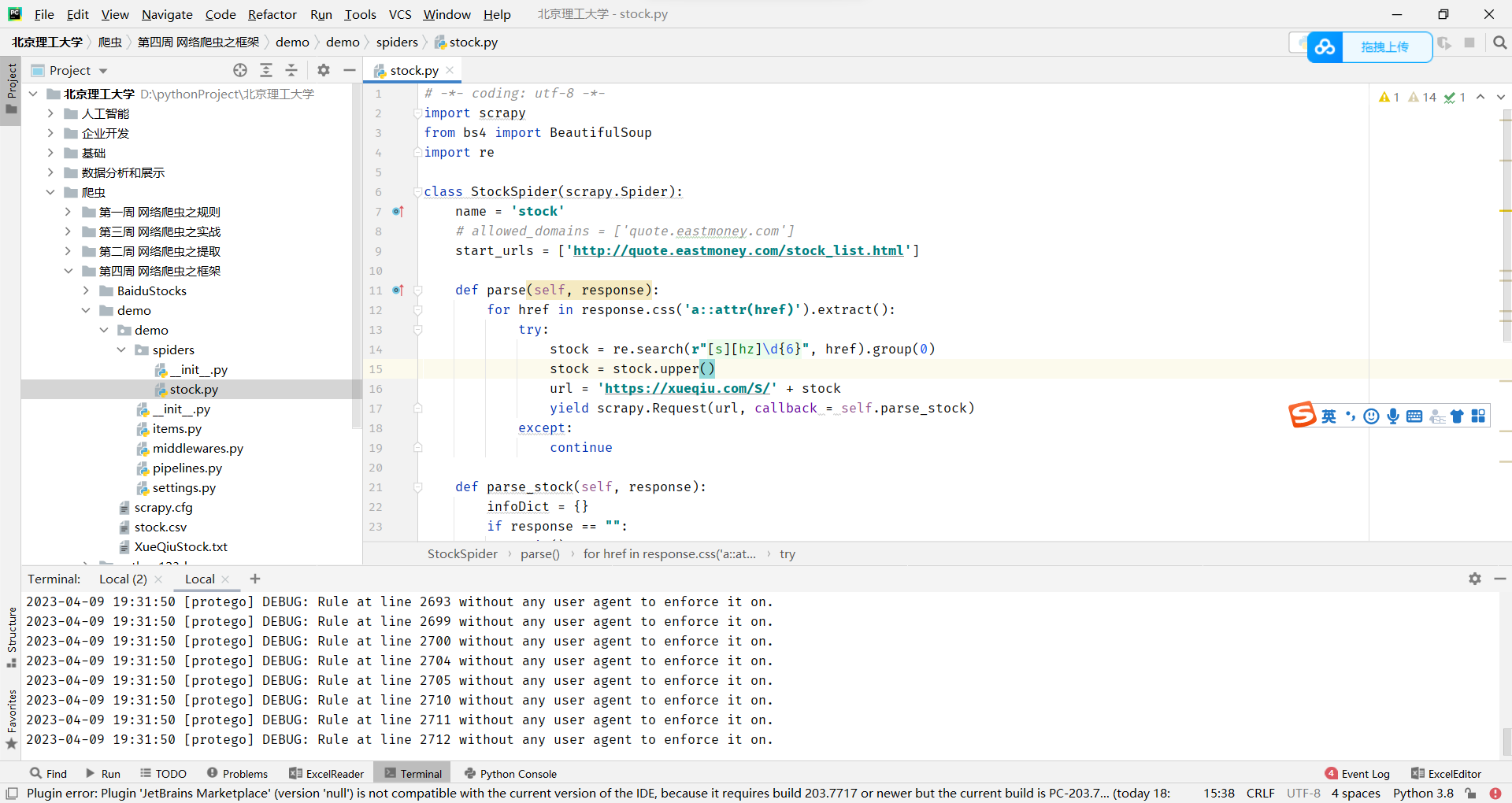
这是一个使用Scrapy框架编写的Python脚本,旨在从一个网站上爬取有关股票的信息。
- 脚本导入了Scrapy和BeautifulSoup模块,以及re模块。
- StockSpider类是一个Spider类的子类,用于定义爬虫的行为。在该类中,name属性定义了爬虫的名称,start_urls属性定义了爬虫起始爬取的网址。
- parse方法是默认的回调函数,用于处理响应。在该方法中,使用response.css方法获取响应中所有a标签的href属性值,然后使用正则表达式提取股票代码。如果提取到股票代码,则构造股票详情页的URL,并发送一个请求,使用parse_stock方法作为回调函数。
- parse_stock方法用于处理股票详情页的响应。在该方法中,使用正则表达式和BeautifulSoup库解析响应中的HTML,提取股票名称和详细信息。最后,将信息以字典的形式返回。
总之,这个脚本使用Scrapy和BeautifulSoup模块来爬取股票信息,包括股票名称和详细信息。
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
import re
class StockSpider(scrapy.Spider):
name = 'stock'
# allowed_domains = ['quote.eastmoney.com']
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.search(r"[s][hz]\d{6}", href).group(0)
stock = stock.upper()
url = 'https://xueqiu.com/S/' + stock
yield scrapy.Request(url, callback = self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
if response == "":
exit()
try:
name = re.search(r'<div class="stock-name">(.*?)</div>', response.text).group(1)
infoDict.update({'股票名称': name.__str__()})
tableHtml = re.search(r'"tableHtml":"(.*?)",', response.text).group(1)
soup = BeautifulSoup(tableHtml, "html.parser")
table = soup.table
for i in table.find_all("td"):
line = i.text
l = line.split(":")#这里的冒号为中文的冒号(:)!!!而不是英文的(:)
infoDict.update({l[0].__str__(): l[1].__str__()})
yield infoDict
except:
print("error")
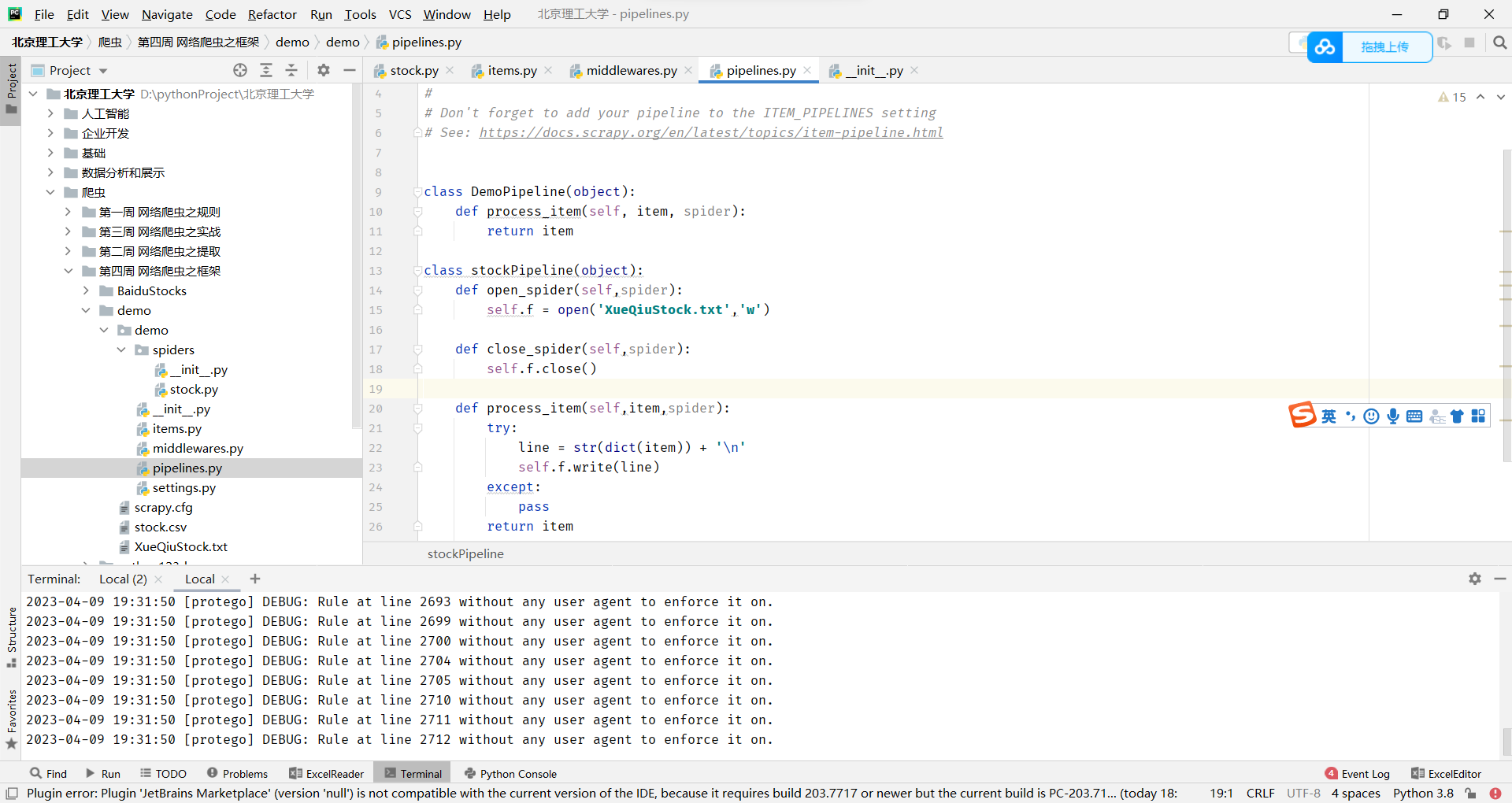
下面代码定义了两个数据处理管道类,用于在爬虫抓取到数据后对数据进行处理,具体说明如下:
- DemoPipeline类:这是一个空的管道类,它只是简单地将从爬虫获得的数据返回,没有对数据进行任何处理。
- stockPipeline类:这是一个自定义管道类,它用于将爬虫获取到的数据存储到文件中。在该类中,open_spider()方法在爬虫启动时被调用,打开一个文本文件('XueQiuStock.txt')以供写入。close_spider()方法在爬虫结束时被调用,关闭文件。process_item()方法在爬虫获得一个item时被调用,将item转换成字典形式并写入到文件中,然后将item返回。
总之,这段代码定义了两个数据处理管道类,它们分别提供了不同的处理方法来处理爬虫抓取到的数据。 DemoPipeline类只是将数据返回,而stockPipeline类将数据写入到文件中。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class DemoPipeline(object):
def process_item(self, item, spider):
return item
class stockPipeline(object):
def open_spider(self,spider):
self.f = open('XueQiuStock.txt','w')
def close_spider(self,spider):
self.f.close()
def process_item(self,item,spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
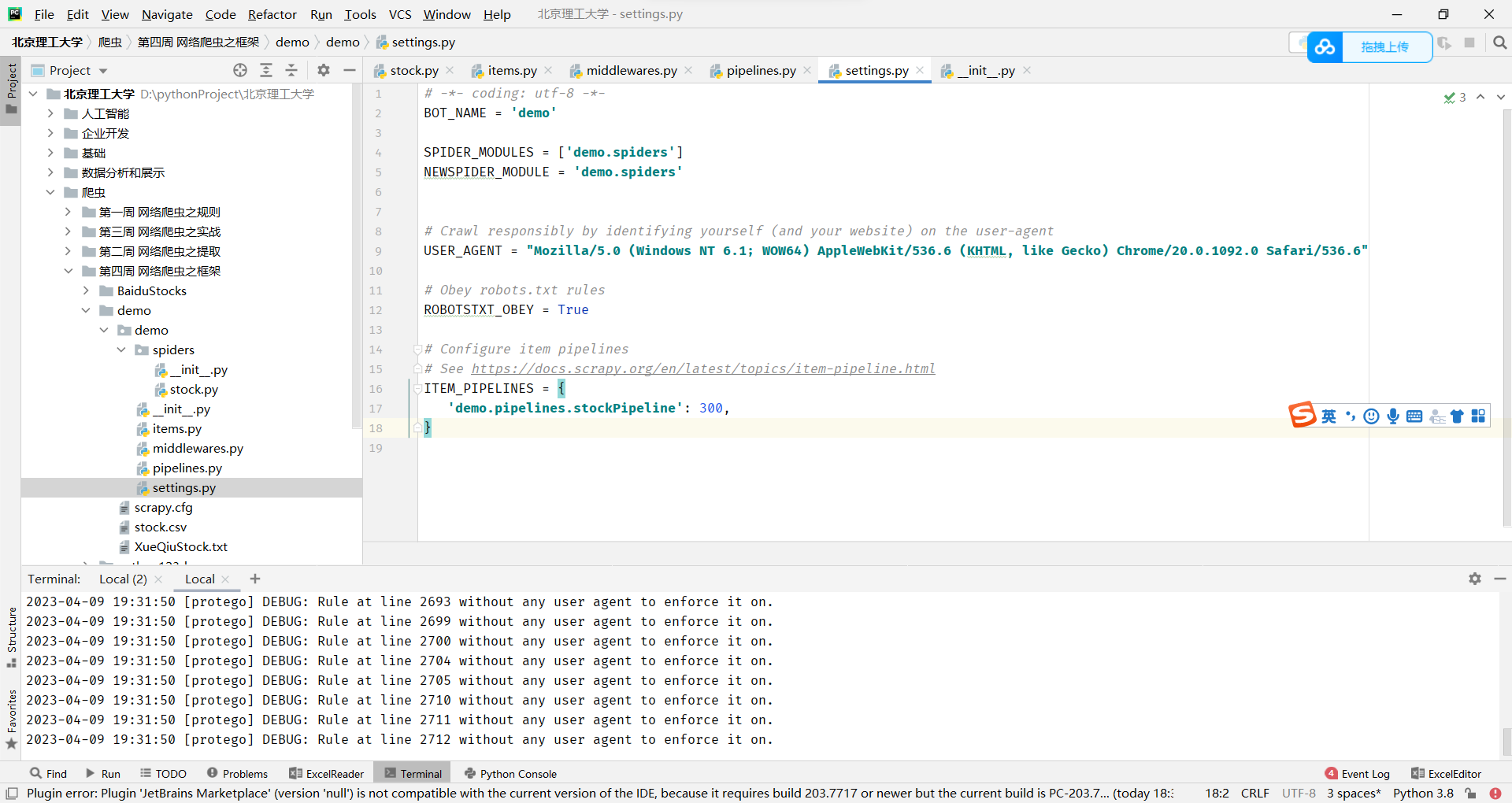
下面代码是Scrapy爬虫项目的配置文件settings.py,它定义了一些爬虫的设置,包括:
- BOT_NAME:爬虫项目的名称,可以是任何字符串。
- SPIDER_MODULES和NEWSPIDER_MODULE:定义了爬虫代码所在的模块,即'spiders'目录。其中,SPIDER_MODULES是一个列表,包含了所有包含爬虫代码的模块,而NEWSPIDER_MODULE是默认的爬虫模块名称,即'spiders'。
- USER_AGENT:用于标识爬虫的用户代理,可以是任何字符串,这里使用了一个模拟Chrome浏览器的字符串。
- ROBOTSTXT_OBEY:一个布尔值,指示是否遵守robots.txt协议。如果设置为True,则爬虫将不会访问被网站禁止爬取的部分。
- ITEM_PIPELINES:定义了一组数据处理管道类,用于在爬虫抓取到数据后对数据进行处理。在这里,它只有一个管道类stockPipeline,并且设置了它的优先级为300,这意味着它将在其他管道类之后被执行。
# -*- coding: utf-8 -*-
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders']
NEWSPIDER_MODULE = 'demo.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'demo.pipelines.stockPipeline': 300,
}
效果