系列文章目录
python爬虫实践–晋江小说书籍分析
python爬虫实践-腾讯视频弹幕分析
python爬虫实践-B站弹幕分析
文章目录
- 系列文章目录
- 前言
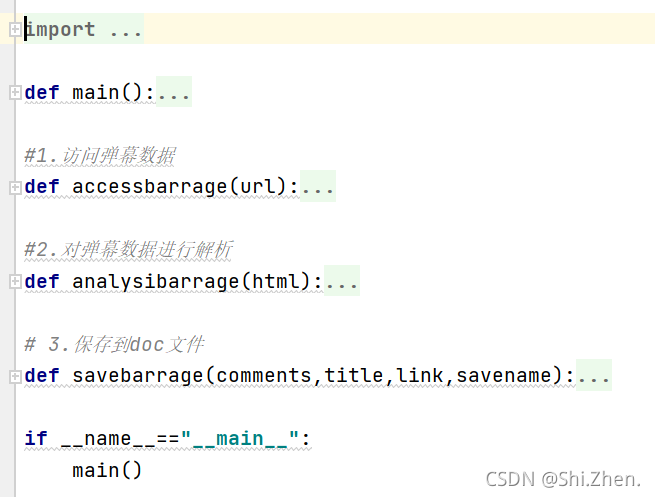
- 目录
- 主程序模块
- main()函数
- 1.爬取网页
- 2.开始解析数据
- 3.存放数据
- 结语
前言
编写这个程序的出发点是……研究弹幕文化??额,不是,就是好奇,大家都发些什么,为什么有些弹幕反响很高,我每次发都无人问津(生气)
那还是和上次爬取晋江小说的程序流程差不多,就是进入网页,提取数据,存储数据。不同的只是网页编排方式不一样,只要找到合适的正则表达式,就可以把数据提出来。
哦,还有一个大问题,找到存储弹幕数据的文档规律最重要,这个解决了,基本这个程序就完成了。
当然,为了方便我们的数据更有质量,可以用程序筛选一下,比如重复的弹幕就只记录一条,100个点赞以下的弹幕不记录,还有按照点赞数从高到低排序。
下面开始上代码啦啦啦啦
目录

主程序模块
这个模块,把弹幕文档的基本格式先固定下来,就是baseurl,因为一集弹幕它可能有很多个文档,这些文档都由timestamp的值来区分,规律就是第一个文档的timestamp值是15,下一个文档的timestamp值加30,…………
python">if __name__=='__main__':
#爬取整集弹幕
baseurl = 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery191006002695521294066_1613526990594&target_id=6402048035%26vid%3Do003502jkv8×tamp='
for i in range(15, 2595, 30):
url = baseurl + str(i)
main(url)
print('{}爬取完毕'.format(url))
print('全部爬取完毕!')
这个程序运行到main()的时候会走进子函数,我们爬取网页、提取数据、存储数据的过程都是在子函数中完成的,现在我们一个一个来看这些子函数
main()函数
main()函数主要也就是定参数,规范流程,把爬取网页模块儿的输出数据传入解析数据模块儿,然后把解析数据模块儿的输出数据传入存放数据模块儿……
python">#定义全局变量
flag = 0
def main(url):
#基础网址
savename = '暗恋橘生淮南.docx'
title = '第二集'
link = 'https://v.qq.com/x/cover/mzc002002vcxot9.html'
# 1.爬取网页
bs = crawlweb(url)
# 2.开始解析数据
comments = analysedata(bs)
#print(comments)
# 3.存放数据
savebarrage(comments, title, link, savename)
接下来进行第一步
1.爬取网页
python">def crawlweb(url):
#伪装headers
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75"
}
html = requests.get(url,headers=head)
bs = json.loads(html.text[html.text.find('{'):-1], strict = False)
# print(bs)
# strict = False
return bs
这部分要构造一个协议头,用来把程序伪装成浏览器。
其次主要就是用了loads函数来提取网页的html代码。
2.开始解析数据
python">def analysedata(bs):
#存储数据
df = pd.DataFrame()
contents=[]
upcounts=[]
#遍历获取目标字段
for i in bs['comments']:
content = i['content'] #弹幕内容
upcount = i['upcount'] #点赞数列表
# cache = pd.DataFrame({'内容':[content],'评论点赞':[upcount]})
# df = pd.concat([df,cache])
#print(df)
contents.append(content)
upcounts.append(upcount)
dic = dict(zip(contents,upcounts))
#删除点赞数在100以下的元素
for key, value in list(dic.items()):
if value<100:
del(dic[key])
#排序
comments = sorted(dic.items(), key=lambda dic:dic[1],reverse=True)
return comments
这段代码还有可以改进的地方:朝字典中添加元素时,如果存在相同的键,就会替换掉;如果某条内容很多人发,第一条点赞数多,最后一条点赞数少,那么这条内容就会被删除,造成统计的数据不准确,很有可能这条内容就是十分重要。
3.存放数据
python">def savebarrage(comments,title,link,savename):
global flag
if flag == 0:
document = Document() #savename不存在
document.add_heading(title, 0)
document.add_heading(link, 1)
flag = 1
else:
document = Document(savename) #savaname存在
#添加段落,文本可以包含制表符(\t)、换行符(\n)或回车符(\r)等
#添加标题,并设置级别,范围:0 至 9,默认为1
'''for i in range(len(comments[0]))
item = comments[0][i]+'comments[1][i]
document.add_paragraph()
document.add_paragraph(comments[1][i])'''
#在doc中添加表格存储
table = document.add_table(rows=1, cols=2) # 添加表
hdr_cells = table.rows[0].cells # 设置表首行标题
hdr_cells[0].text = '内容' # 表首行标题赋值
hdr_cells[1].text = '点赞数'
#for循环将records内容赋值到单元格内
for item in comments:
row_cells = table.add_row().cells
row_cells[0].text = item[0]
row_cells[1].text =str(item[1])
#print(comments[0])
#保存.docx文档
document.save(savename)
这段有个需要处理的地方在于:当我们用来存储数据的文件不存在时,我们可以直接用代码写入,这时候程序会自动创建该文件。
但是如果该文件原本存在,而我们用代码往里面写东西的时候,如果直接写,那么程序不会打开原文件,而是会重新创建一个新文件,最后保存的时候覆盖原文件。
所以,当原文件存在时,我们要写入,需要打开原文件。
这里的flag就是用来判断原文件存不存在的。
结语
这个小程序,有很多不完整的地方,因为我时间和能力都有限,并不能把它做到很美观,很友好,想到以下几个可改进的地方给大家参考:
1.可改进:如果要获取整个电视剧每一集的弹幕数量,可以通过观察每一集链接中的规律,根据规律修改参数,然后就可以提取了
2.可以把所有函数的参数都单独提出来,不要放到函数中去,不然修改变量的时候可能不明白是啥意思或者修改不完全(目前该函数修改变量的地方是主函数和main函数)