系列文章目录
python爬虫实践–晋江小说书籍分析
python爬虫实践-腾讯视频弹幕分析
python爬虫实践-B站弹幕分析
文章目录
- 系列文章目录
- 前言
- 目录
- 主程序模块
- main()函数
- 1.访问弹幕数据
- 2.对弹幕数据进行解析
- 3.保存到doc文件
- 总结
前言
在前两次的晋江小说和腾讯弹幕爬取基础上,我逐渐觉得自己掌握了这门技术的奥义?于是迫不及待地又对准了我的下一个目标——B站。
为什么是B站?作为弹幕文化的大本营,必须是B站,B站的大部分有趣都来自于弹幕。
目录
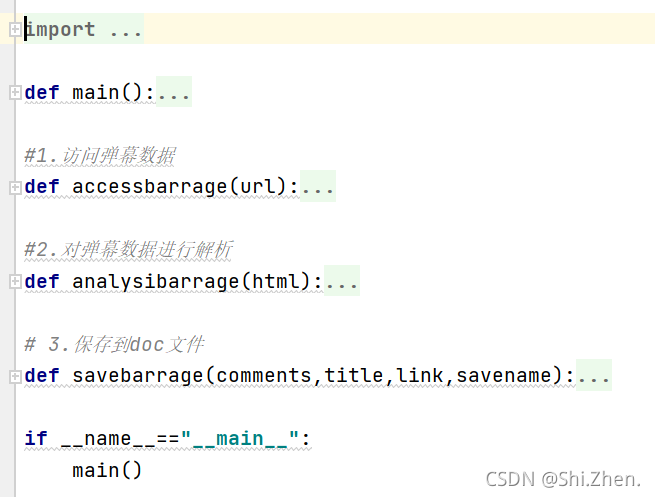
与前两个爬虫实践如出一辙,都是一个主函数作为程序入口,并调用子函数。其它几个def定义的子函数分别来处理不同阶段的数据。
该程序用到的头文件
python">import requests
from bs4 import BeautifulSoup
from docx import Document
主程序模块
python">if __name__=="__main__":
main()
单纯地给程序一个入口,就像起跑线。
main()函数
python">def main():
url = 'https://comment.bilibili.com/251139222.xml'
savename = 'B站弹幕1.docx'
title = '风犬少年的天空第二集'
link = 'https://www.bilibili.com/bangumi/play/ep340251?from=search&seid=11822154625123447233'
# 1.访问弹幕数据
html = accessbarrage(url)
# 2.对弹幕数据进行解析
comments = analysibarrage(html)
# 3.保存到doc文件
savebarrage(comments, title, link, savename)
main()函数用来总揽全局,它相当于这群子函数的老大,决定谁先干什么,谁后干什么,并且实现数据的传递,即把前一个函数处理完的数据递交给下一个函数做参数。
1.访问弹幕数据
python">def accessbarrage(url):
html = requests.get(url).content
return html
2.对弹幕数据进行解析
python">def analysibarrage(html):
html_data = str(html, 'utf-8')
bs4 = BeautifulSoup(html_data, 'lxml')
results = bs4.find_all('d')
comments = {comment.text for comment in results}
comments = list(comments)
comments = sorted(comments)
return comments
# comments_dict = {'comments': comments}
熟练运用bs里的各种子函数,可以快速准确地找到需要的数据。
3.保存到doc文件
python">def savebarrage(comments,title,link,savename):
document = Document(savename)
#添加段落,文本可以包含制表符(\t)、换行符(\n)或回车符(\r)等
#添加标题,并设置级别,范围:0 至 9,默认为1
document.add_heading(title, 0)
document.add_heading(link, 1)
for item in comments:
document.add_paragraph(item)
#保存.docx文档
document.save(savename)
总结
实际上,做多了就发现,这种爬虫程序主要就三步。
1.先把整个网页提取出来
2. 再在提取出来的网页里筛选需要的数据(bs中的一些函数可以提供方便)
3. 存到自己的文档中,方便查看分析。