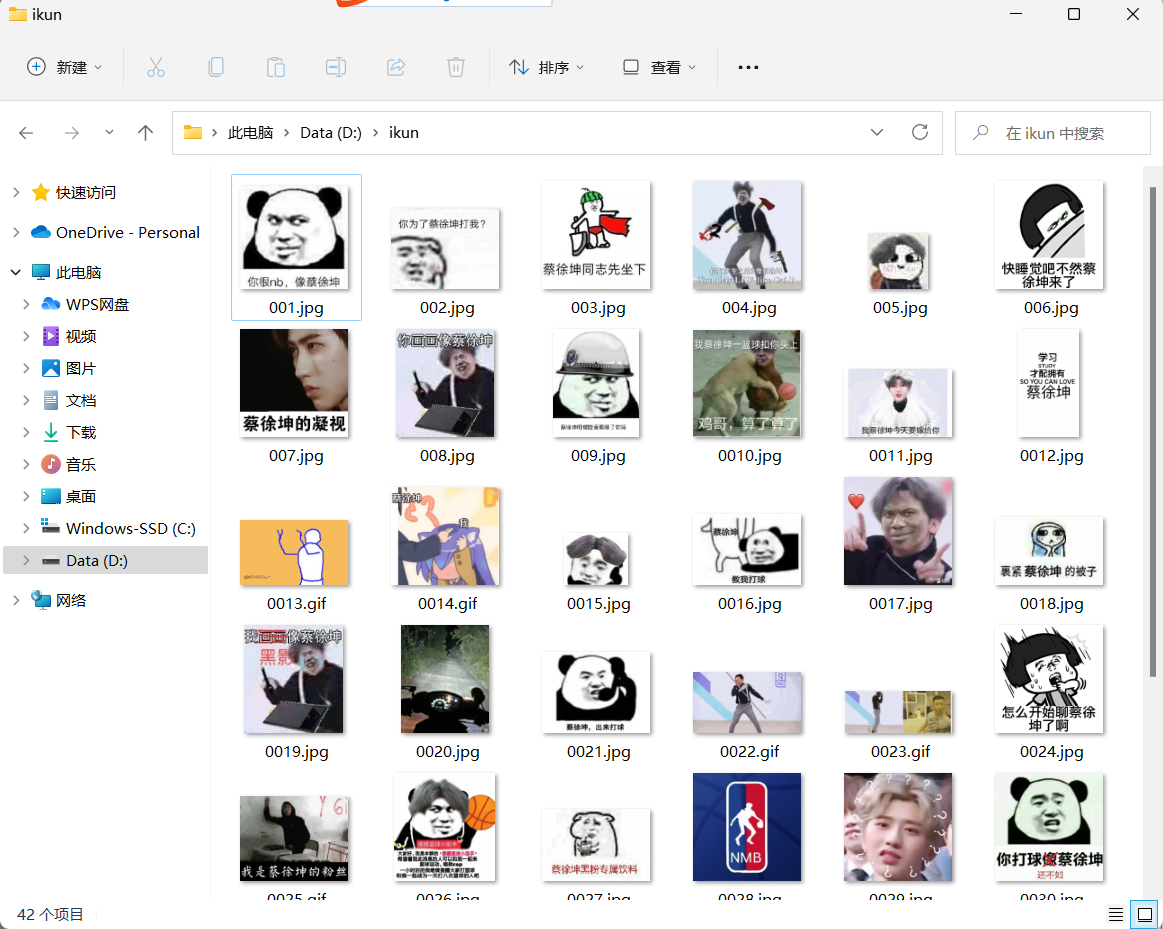
🐔🐔🐔作为一名真爱粉怎么能没有ikun的表情包?🐔🐔🐔
🍓使用到的技术
HttpClient4.x 也就是 org.apache.http.xxx 这个版本
Jsoup 1.15.3
坤图来源:斗图王
🍒主要思路
借助HttpClient通过GET方法请求资源
将返回的实体对象转为源码(html)
使用Jsoup解析出源码中图片地址
下载图片到本地
🍎坑
Target host is not specified [需要把文件地址写完整,URL地址必须加协议名称(http或https)]
🍇爬取流程
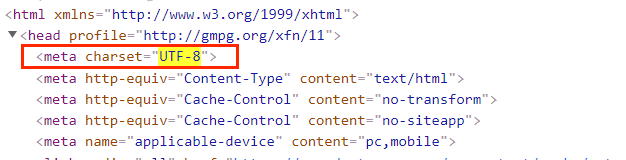
查看网页结构及编码
查看编码
查看网页结构
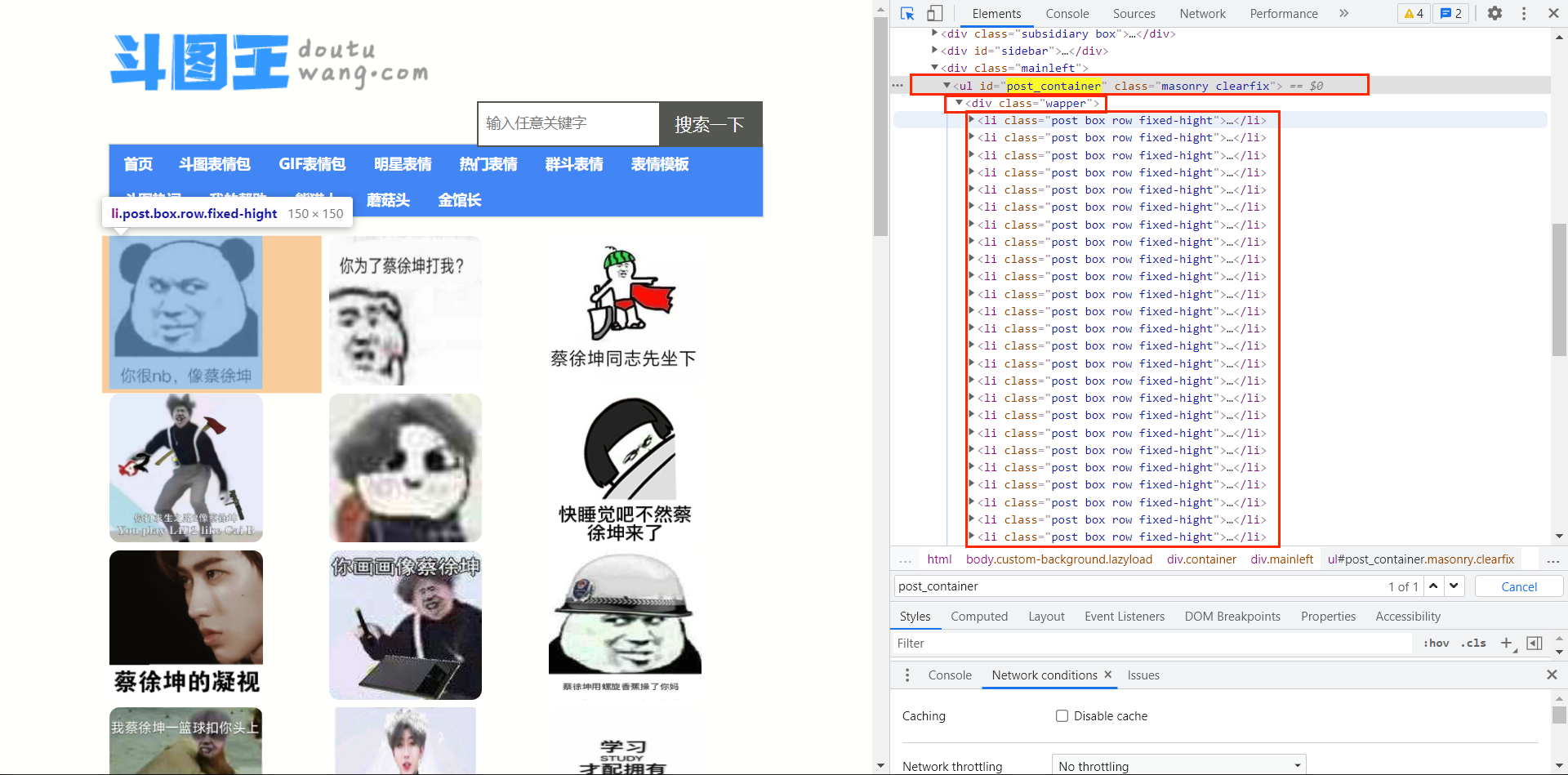
查看结构发现,我们可以用css选择器轻松解析出来
即 #post_container > div > li > div > a > img
# 代表id选择器
> 代表层级结构
编写请求和返回实体的代码
尽可能打包成方法,方便代码复用
java">java">public static HttpEntity getEntityByHttpGetMethod(String url) throws IOException {
//生成GET请求对象
HttpGet httpGet = new HttpGet(url);
//执行请求并获得响应对象
HttpResponse httpResponse = httpClient.execute(httpGet);
//获得响应实体
HttpEntity entity = httpResponse.getEntity();
return entity;
}
编写保存图片的代码
使用BufferedInputStream下载图片更好一些
java">java">public static void saveImg(String url,String savePath) throws IOException {
//获取图片信息,做输出流
InputStream in = getEntityByHttpGetMethod(url).getContent();
//定义每次读取的最大值为 1KB
byte[] buffer = new byte[1024];
BufferedInputStream inputStream = new BufferedInputStream(in);
int len = 0;
//创建缓冲流
FileOutputStream out = new FileOutputStream(new File(savePath));
BufferedOutputStream outputStream = new BufferedOutputStream(out);
//图片写入
while ((len = inputStream.read(buffer,0,1024)) != -1){
outputStream.write(buffer,0,len);
}
//关闭缓冲流资源
inputStream.close();
outputStream.close();
}
🍈完整代码
java">java">package com.ikun;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.URLDecoder;
import java.net.URLEncoder;
/**
* 使用工具 - HttpClient 4.X
* 下载图片
*/
public class CrawlerImg {
private static HttpClient httpClient = HttpClients.custom().build();
private static String savePath = "D:\\ikun\\";
public static void main(String[] args) throws IOException {
String url = "https://www.doutuwang.com/?s=%E8%94%A1%E5%BE%90%E5%9D%A4";
//String url = "https://www.doutub.com/search/%E8%94%A1%E5%BE%90%E5%9D%A4/1";
//获得响应对象
HttpEntity httpEntity = getEntityByHttpGetMethod(url);
String html = EntityUtils.toString(httpEntity,"utf-8");
//生成 Document对象
Document doc = Jsoup.parse(html);
Elements elements = doc.select("#post_container > div > li > div > a > img");
System.out.println("共发现资源数目 "+elements.size());
//下载100张
int count = 0;
for (Element element : elements){
//System.out.println(element.text());
count++;
String picUrl = element.attr("src");
System.out.println(picUrl);
if (picUrl.contains("gif")){
saveImg(picUrl,savePath+"00"+count+".gif");
}else {
saveImg(picUrl,savePath+"00"+count+".jpg");
}
if (count==100){
break;
}
System.out.println("已下载到"+savePath);
}
System.out.println("共下载"+count+"张");
}
public static HttpEntity getEntityByHttpGetMethod(String url) throws IOException {
//生成GET请求对象
HttpGet httpGet = new HttpGet(url);
//执行请求并获得响应对象
HttpResponse httpResponse = httpClient.execute(httpGet);
//获得响应实体
HttpEntity entity = httpResponse.getEntity();
return entity;
}
public static void saveImg(String url,String savePath) throws IOException {
//获取图片信息,做输出流
InputStream in = getEntityByHttpGetMethod(url).getContent();
//定义每次读取的最大值为 1KB
byte[] buffer = new byte[1024];
BufferedInputStream inputStream = new BufferedInputStream(in);
int len = 0;
//创建缓冲流
FileOutputStream out = new FileOutputStream(new File(savePath));
BufferedOutputStream outputStream = new BufferedOutputStream(out);
//图片写入
while ((len = inputStream.read(buffer,0,1024)) != -1){
outputStream.write(buffer,0,len);
}
//关闭缓冲流资源
inputStream.close();
outputStream.close();
}
}