selenium">安装Selenium
pip install seleniumChromedriver
https://sites.google.com/a/chromium.org/chromedriver/downloads
进入页面,找到最后发布版本

转到:
https://chromedriver.storage.googleapis.com/index.html?path=2.33/
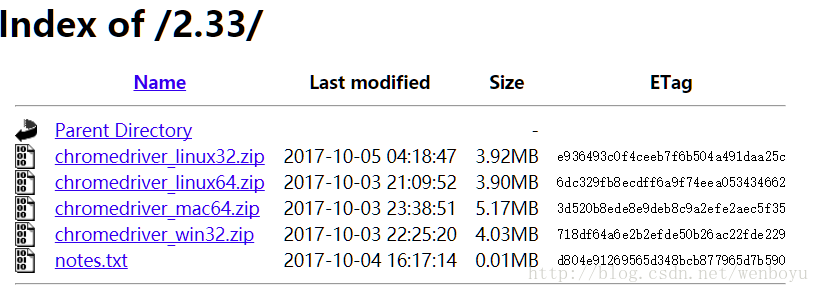
找到适合自己的系统版本
下载解压到 python 环境的Scripts文件夹里面
在命令行中输入 chromedriver 打印出提示信息表示安装完成
Starting ChromeDriver 2.33.506120 (e3e53437346286c0bc2d2dc9aa4915ba81d9023f) on port 9515
Only local connections are allowed.如果出现以下情况:
要么更新chrome,要么重新降低chromedriver的版本
>>> from selenium import webdriver
>>> driver = webdriver.Chrome()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "D:\Anaconda3\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 69, in __init__
desired_capabilities=desired_capabilities)
File "D:\Anaconda3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 151, in __init__
self.start_session(desired_capabilities, browser_profile)
File "D:\Anaconda3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 240, in start_session
response = self.execute(Command.NEW_SESSION, parameters)
File "D:\Anaconda3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 308, in execute
self.error_handler.check_response(response)
File "D:\Anaconda3\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 194, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.WebDriverException: Message: session not created exception: Chrome version must be >= 60.0.3112.0 # 版本必须大于60.x
(Driver info: chromedriver=2.33.506120 (e3e53437346286c0bc2d2dc9aa4915ba81d9023f),platform=Windows NT 10.0.14393 x86_64)




