前言
为了方便对爬虫项目的流程化管理,需要一款合适的工具。主要实现的功能有:
能对爬虫项目的管理做到“统一”、“稳定”、“方便”;
能够查看爬虫项目的运行情况,包括查看日志,控制台信息,告错预警信息等。
以切身实际需求来说,普通的Scrapy项目已能够满足信息采集的需求,不过充其量也就是一个脚本,怎么样能更进一步,形成一个完整的采集项目呢?对程序代码的检测,采集内容的检测,服务运行的情况统计等内容是必不可少的。
基于以上目标,学习搭建Scrapy爬虫项目的管理部署就显得十分重要了。
第一章 Scrapy的服务程序Scrapyd
1.了解Scrapyd
Scrapyd是一个运行Scrapy爬虫的服务程序,提供一系列HTTP接口来帮助部署、启动、停止和删除爬虫程序。Scrapyd支持版本管理,同时还可以管理多个爬虫任务,利用它可以方便的完成Scrapy爬虫项目的部署任务调度。
2.安装启动Scrapyd
在控制台中,安装命令如下:
pip3 install scrapyd
更详细的安装流程可以参考:https://setup.scrape.center/scrapyd
安装完成后,启动Scrapyd的命令如下:
scrapyd
3.访问Scrapyd
Scrapy 默认会在6800端口上运行。访问服务器的6800端口,就可以看到一个WebUI页面。
如下图所示:
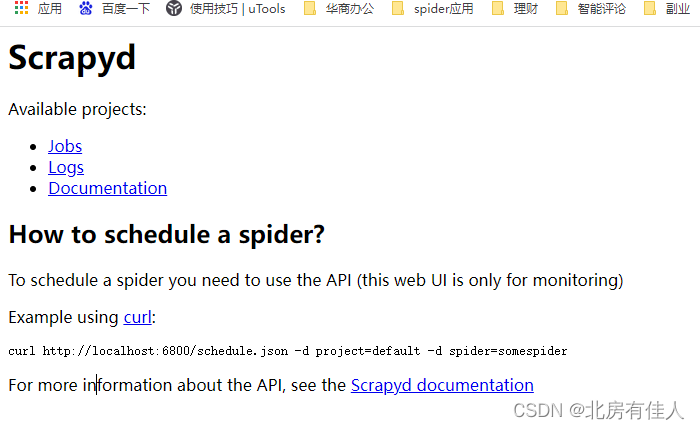
4.Scrapyd的功能(重中之重)
Scrapyd提供了一系列HTTP接口来实现各种操作。(通过访问固定API接口,实现查询管理功能)
常用的API接口有一下几个:
项目部署API
1.daemonstatus.json
负责查看Scrapyd当前的服务和任务状态。访问http://xxx.xxx.x.x:6800/daemonstatus.json
返回结果是JSON字符串。有各个项目的运行状态和名称等信息。
2.addversion.json
用来部署Scrapy项目。部署之前,需要将项目先打包成egg文件,然后传入项目名称和部署版本。
命令:
http://xxx.xxx.x.x:6800/adversion.json -F project=<project_name> -F version=v1 -F egg = <project_name>.egg
这里-F 代表添加一个参数,同时还需要将项目打包成egg文件放到本地。project_name是真实的项目名称。
3.schedule.json
负责调度已经部署好的Scrapy项目。
命令:
http://xxx.xxx.x.x:6800/schedule.json -d project=<project_name> -d spider=<spider_name>
project即项目名称,spider即爬虫名称。
返回一个status项目启动情况,还有一个是当前正在运行的爬取任务代号。
4.cancel.json
用来取消指定的爬取任务。如果这个任务是pending状态,将会被移除;如果任务是runing状态,将会被终止。
命令:
http://xxx.xxx.x.x:6800/cancel.json -d project=<project_name> -d job=xxxxx
传入项目名称和爬取任务的代号。
查询API
1.listprojects.json
列出部署到Scrapyd服务上的所有项目的描述信息。
2.listversions.json
获取指定项目的所有版本号。
3.listspiders.json
获取某个项目最新的一个版本的所有Spider民称。
4.listjobs.json
获取某个项目当前运行的所有任务详情。
操作API
1.delversion.json
删除项目的指定版本
2.delproject.json
删除指定项目
Gerapy_74">第二章 Gerapy爬虫管理框架的使用
Gerapy_75">1.了解Gerapy
Gerapy是一个基于Scrapyd、ScrapydAPI、Django、Vue.js搭建的分布式爬虫管理框架。
可以实现更方便的控制爬虫运行、更直观的查看爬虫状态、更实时的查看爬取结果、更简单的实现项目部署、更统一的实现主机管理。
Gerapy_79">2.安装使用Gerapy
2.1 准备工作
pip3 install gerapy
安装Gerapy服务。
2.2 初始化
首先利用gerapy命令 新建一个工作目录,如下:
gerapy init
对数据库进行初始化,会生成一个SQLite数据库,保存各个主机配置信息、部署版本等。
cd gerapy
gerapy migrate
生成一个管理账号(登录账户,用户名和密码默认都是admin):
gerapy initadmin
如果不想用默认的admin账号,也可以创建单独的账号:
gerapy createsuperuser
Gerapy_103">2.3 启动Gerapy服务
gerapy runserver
默认在8000端口上开启Gerapy服务。访问http://localhost:8000进去Gerapy服务页面。
按照提示输入用户名和密码。进入管理页面。
左侧有主机管理、项目管理、任务管理三大模块。
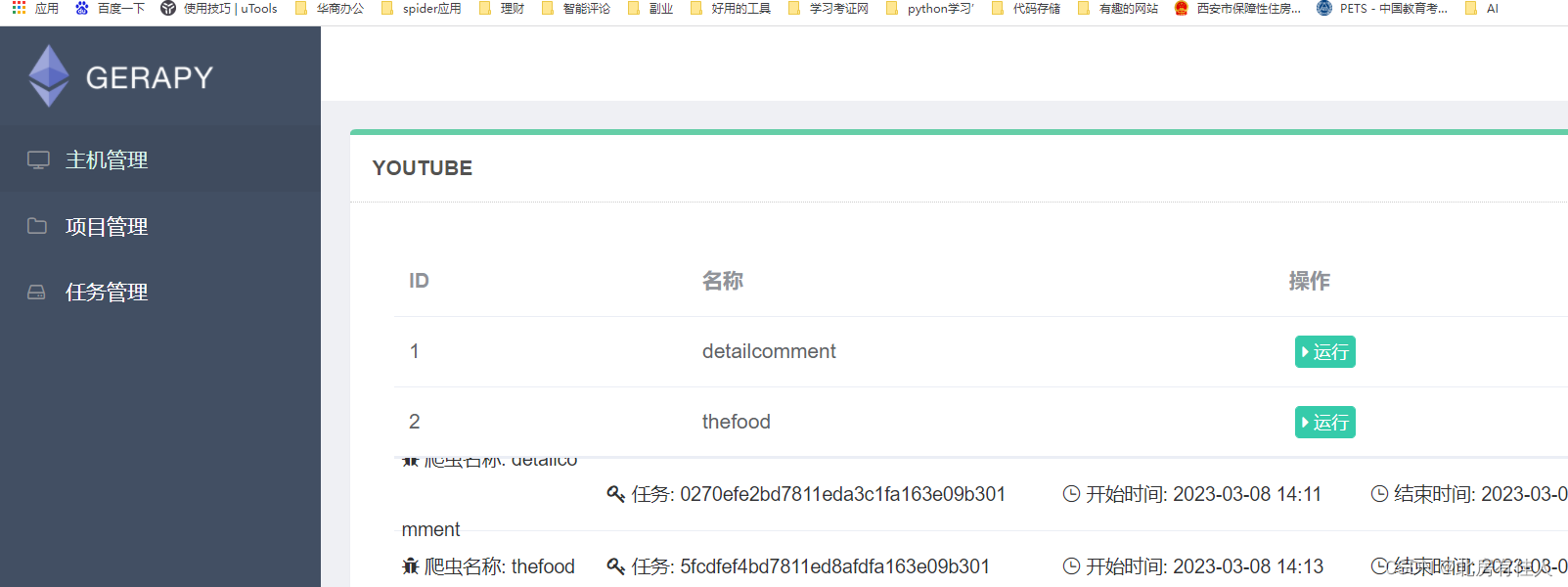
2.4 部署Scrapy项目
第一步,对接scrapyd服务。
在主机管理中,可以添加各台主机的Scrapyd运行地址和端口,并加上名称标记。
如下图:
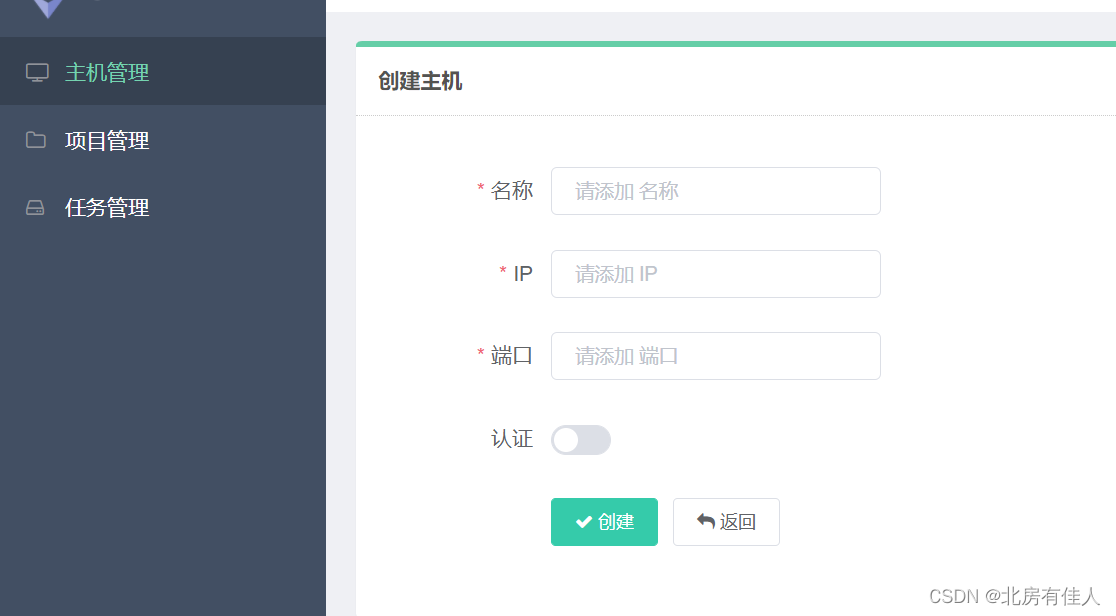
添加之后,该主机会出现在主机列表中,Gerapy会监控各台主机的运行状况并以不同的状态标识。
如下图:
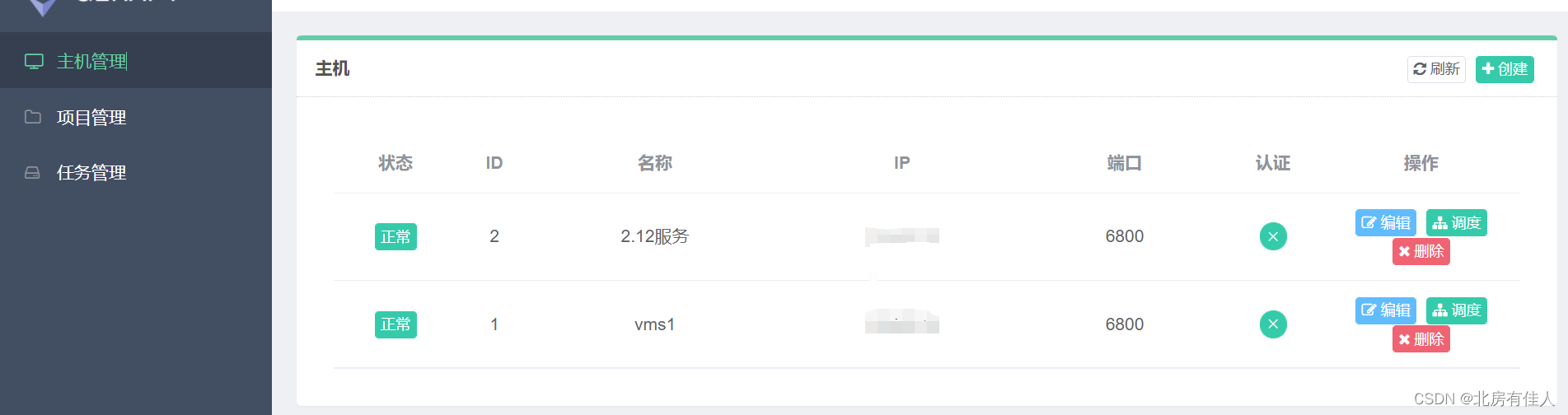
第二步,将Scrapy项目部署到Gerapy上
在运行Gerapy服务的机器上,gerapy目录下有一个空的projects文件夹,这就是存放Scrapy目录的文件夹。想要部署某个Scrapy项目,只需要将整个项目文件放到projects文件夹下即可。
重新回到Gerapy管理界面,点击**“项目管理**”,即可看到当前项目列表。如下图:
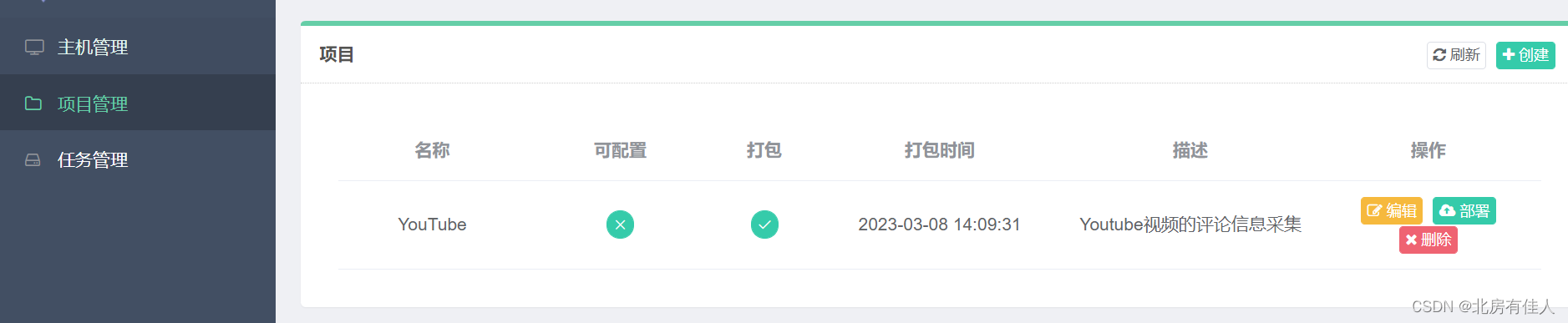
如果项目没有问题,可以点击**“部署”按钮进行打包和部署。部署之前需要打包项目**,打包时,可以指定版本描述。
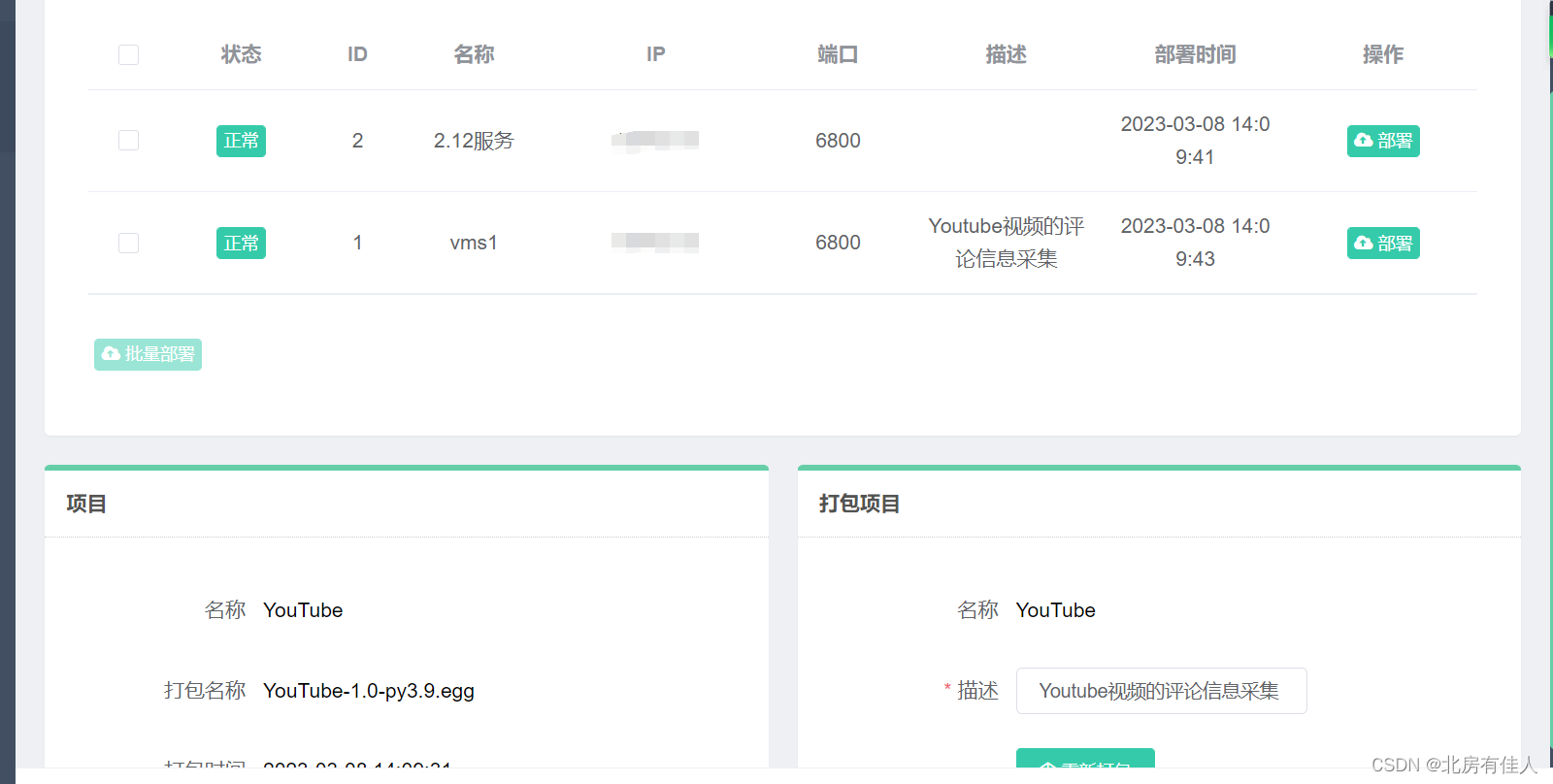
这里我已经部署好了,就不再重复部署了。
打包完成之后,直接点击“部署”按钮即可将打包好的Scrapy项目部署到对应的云主机上(也就是scrapyd服务的主机上)
部署完毕后,回到**“主机管理”页面进行任务调度。点击“调度”即可进入“任务管理”页面,查看当前主机所有任务的运行状态。通过点击“新任务”、“停止”等按钮来实现任务的启动和停止等操作,也可以通过展开任务条目查看日志详情**。
后记
到这里,简单的Scrapy项目管理部署已经基本完成了。Gerapy实现了简单的项目管理,对多个Scrapy项目完成统一化的流程执行,功能是实现了。效果嘛还是差了点。
最好的方案是k8s+Prometheus+Grafana可视化图表管理。问了一下运维小伙伴,K8S的部署对硬件配置有要求,无奈作罢。目前项目管理只限于自己的摸索学习阶段,实在是无法开口提要求资源了。ε=(´ο`*)))唉