Python爬虫获取简书的用户、文章、评论、图片等数据,并存入数据库
- 爬虫定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(来源:百度百科——爬虫)
- 爬取原理:万维网由许多的url构成,犹如一张巨大的网。通过url并发送请求获取数据(html),最后解析提取所需数据即可。
- 实战演示:获取简书的用户、文章、评论、图片等数据,并存入数据库。
(1)网站分析
1)获取文章url列表


2)获取文章信息



3)获取评论信息

4)获取用户信息




(2)编码实现
1)bean
python"># 用户:用户ID、用户名、密码、性别、年龄、地址、电话、头像、邮箱、关注总数、粉丝总数、文章总数、总字数、喜欢总数、余额、简介、注册时间。
class User(object):
def __init__(self, name, password, sex, age, address, tel, head_image, email, followers_count, fans_count,
articles_count, words_count, likes_count, balance, profile):
self.user_id = None
self.name = name
self.password = password
self.sex = sex
self.age = age
self.address = address
self.tel = tel
self.head_image = head_image
self.email = email
self.followers_count = followers_count
self.fans_count = fans_count
self.articles_count = articles_count
self.words_count = words_count
self.likes_count = likes_count
self.balance = balance
self.profile = profile
self.create_time = None
def __str__(self):
print("id:" + str(self.user_id))
print("sex:" + str(self.sex))
print("age:" + str(self.age))
print("address:" + str(self.address))
print("tel:" + str(self.tel))
print("head_image:" + str(self.head_image))
print("email:" + str(self.email))
print("followers_count:" + str(self.followers_count))
print("fans_count:" + str(self.fans_count))
print("articles_count:" + str(self.articles_count))
print("words_count:" + str(self.words_count))
print("likes_count:" + str(self.likes_count))
print("balance:" + str(self.balance))
print("profile:" + str(self.profile))
# 图书分类:图书分类ID、分类名、描述、文章总数、粉丝总数。
class Classify(object):
def __init__(self, classify_id, name, description, articles_count, fans_count, article_url):
self.classify_id = classify_id
self.name = name
self.description = description
self.articles_count = articles_count
self.fans_count = fans_count
self.article_url = article_url
# 图书:图书ID、分类ID、作者ID、图书标题、图书简要、图书内容、总字数、浏览数、点赞数、评论数、赞赏数、发布时间。
class Book(object):
def __init__(self, book_id, classify_id, author_name, title, content, words_count, views_count, likes_count, comments_count, rewards_count):
self.book_id = book_id
self.classify_id = classify_id
self.author_id = None
self.author_name = author_name
self.title = title
self.description = None
self.content = content
self.words_count = words_count
self.views_count = views_count
self.likes_count = likes_count
self.comments_count = comments_count
self.rewards_count = rewards_count
self.create_time = None
def __str__(self):
print("作者:" + self.author_name)
print("标题:" + self.title)
print("内容:" + self.content)
print("字数:" + str(self.words_count))
print("浏览:" + str(self.views_count))
print("喜欢:" + str(self.likes_count))
print("评论:" + str(self.comments_count))
print("打赏:" + str(self.rewards_count))
# 评论:评论ID、用户ID、图书ID、评论内容、点赞数、回复数、评论状态、评论日期。
class Comment(object):
def __init__(self, comment_id, user_id, book_id, content, likes_count, reply_count, status):
self.comment_id = comment_id
self.user_id = user_id
self.book_id = book_id
self.content = content
self.likes_count = likes_count
self.reply_count = reply_count
self.status = status
self.create_time = None
def __str__(self):
print("id:" + str(self.comment_id))
print("book_id:" + str(self.book_id))
print("content:" + str(self.content))
print("likes_count:" + str(self.likes_count))
print("reply_count:" + str(self.reply_count))
print("status:" + str(self.status))
# 回复:回复ID、被回复评论ID、回复评论ID、回复时间。
class Reply(object):
def __init__(self, reply_id, be_reply_comment_id, reply_comment_id, create_time):
self.reply_id = reply_id
self.be_reply_comment_id = be_reply_comment_id
self.reply_comment_id = reply_comment_id
self.create_time = create_time
2)spider
python">import json
import os
import random
import re
import time
from xpinyin import Pinyin
import requests
from bean import bean
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/92.0.4515.131 Safari/537.36 '
}
root = "E:/study/JAVA/SmallWhiteBook/Python/SQL/"
images_root = 'E:/study/JAVA/SmallWhiteBook/Python/upload/images/'
home_url = 'https://www.jianshu.com'
classify = {
'程序员': 'NEt52a',
'摄影': '7b2be866f564',
'故事': 'fcd7a62be697',
'IT': 'V2CqjW',
'读书': 'yD9GAd',
'诗': 'vHz3Uc',
'手绘': '8c92f845cd4d',
'自然科普': 'cc7808b775b4',
'旅行': '5AUzod',
'电影': '1hjajt'
}
users = []
books = []
comments = []
images = []
classify_list = []
articles_id_list = []
user_urls = []
book_urls = []
comment_urls = []
articles_list = []
user_name_and_id = []
suffix = '.sql'
address_list = [
'广西南宁',
'广西河池',
'广西桂林',
'四川成都',
'贵州六盘水',
'广东深圳',
'北京天安门',
'巴黎埃菲尔铁塔',
"旧金山",
"洛杉矶",
"硅谷",
"黑龙江",
"内蒙古",
"兰州"
]
# get数据并编码
def get_content(url):
return requests.get(url, headers=headers).content.decode()
# 为防止sql异常用中文的单引号替换英文的单引号
def clear_single_quotation_mark(string):
string = re.sub("'", "’", str(string))
return str(string)
# 删除文件
def delete_file(path):
if os.path.exists(path):
os.remove(path)
# 下载图片
def download_images(url, name):
path = images_root + name
with open(path, "wb") as f_obj:
f_obj.write(get_content_no_decode(url))
# 下载用户头像
def download_head_images():
for user in users:
url = user.head_image
name = str(url).split('?')[0].split('/')[-1]
download_images(url, name)
# 将中文转化为拼音
def format_pinyin(name):
p = Pinyin()
res = p.get_pinyin(name)
ans = ""
split = res.split('-')
for s in split:
ans += s.capitalize()
return ans
# 写入文件
def write(path, content):
path = root + path + suffix
delete_file(path)
with open(path, "a", encoding='utf-8') as f_obj:
f_obj.write(content)
# 写入用户信息
def write_user():
table_name = "user"
users_set = []
# 清除重复
for u in users:
flag = False
for us in users_set:
if u.name == us.name:
flag = True
break
if not flag:
users_set.append(u)
user_id = 1
res = ""
for u in users_set:
# 用户ID、用户名、密码、性别、年龄、地址、电话、头像、邮箱、关注总数、粉丝总数、文章总数、总字数、喜欢总数、余额、简介、注册时间。
sql = "insert " + table_name + "(userId, name, password, sex, age, address, tel, headImage, email, balance, followers, fans, articles, words, likes, profile) values "
sql += "('" + str(user_id) + "', '" + str(u.name) + "', '" + str(u.password) + "', '" + u.sex + "', '" + str(
u.age) + "', '" + str(u.address) + "', '" + str(
u.tel) + "', '" + u.head_image + "', '" + u.email + "', '" + str(u.balance) + "', '" + str(
u.followers_count) + "', '" + str(u.fans_count) + "', '" + str(u.articles_count) + "', '" + str(
u.words_count) + "', '" + str(u.likes_count) + "', '" + str(u.profile) + "') "
sql += ";\n"
res += sql
user_id += 1
user_name_and_id.append([u.name, user_id])
write(table_name, res)
# 写入分类信息
def write_classify():
table_name = "classify"
res = ""
for c in classify_list:
sql = "insert " + table_name + "(classifyId, name, description, articles, fans, image) values "
sql += "('" + str(c.classify_id) + "', '" + str(c.name) + "', '" + clear_single_quotation_mark(
c.description) + "', '" + str(c.articles_count) + "', '" + str(c.fans_count) + "', '" + str(c.article_url) + "') "
sql += ";\n"
res += sql
write(table_name, res)
# 写入图书信息
def write_book():
table_name = "book"
books_set = []
for b in books:
flag = False
for bs in books_set:
if b.book_id == bs.book_id:
flag = True
break
if not flag:
books_set.append(b)
res = ""
for b in books_set:
author_id = random.randint(1, len(user_name_and_id))
sql = "insert " + table_name + "(bookId, userId, classifyId, title, content, words, views, comments, rewards) values "
sql += "('" + str(b.book_id) + "', '" + str(author_id) + "', '" + str(b.classify_id) + "', '" + clear_single_quotation_mark(
b.title) + "', '" + clear_single_quotation_mark(b.content) + "', '" + str(b.words_count) + "', '" + str(
b.views_count) + "', '" + str(
b.comments_count) + "', '" + str(b.rewards_count) + "') "
sql += ";\n"
res += sql
write(table_name, res)
# 写入评论信息
def write_comment():
table_name = "comment"
comments_set = []
res = ""
for c in comments:
flag = False
for cs in comments_set:
if cs.comment_id == c.comment_id:
flag = True
break
if not flag:
comments_set.append(c)
for c in comments_set:
# 评论ID、用户ID、图书ID、评论内容、点赞数、回复数、评论状态、评论日期。
user_id = random.randint(1, len(user_name_and_id))
sql = "insert " + table_name + "(userId, bookId, content, status, likes, replys) values "
sql += "('" + str(user_id) + "', '" + str(c.book_id) + "', '" + str(c.content) + "', '" + str(
c.status) + "', '" + str(c.likes_count) + "', '" + str(c.reply_count) + "') "
sql += ";\n"
res += sql
write(table_name, res)
# 简书的爬虫类
class Spider(object):
# 主页、分类、每种分类爬取的数量
def __init__(self, home_url=home_url, classify=classify, per=52, comment_count=20):
self.home_url = home_url
self.classify = classify
self.per = per
self.comment_count = comment_count
# 获取分类详细信息
def get_classify_list(self):
id = 1
for k in classify:
# 获取分类url
url = self.get_classify_url(classify[k])
content = get_content(url)
pattern = re.compile(r'<div class="main-top">(.*?)<ul class="trigger-menu"', re.S)
main_top = pattern.findall(content)
pattern = re.compile(r'<img src="(.*?)".*?<div class="info">.*?(\d+).*?(\d+).*?</div>', re.S)
info = pattern.findall(main_top[0])[0]
# 获取文章图片地址
article_url = info[0]
# 下载图片
split = str(article_url).split('?')[0].split('/')
path_name = split[-2] + split[-1]
download_images(article_url, path_name)
# 获取文章总数和粉丝总数
articles_count = info[1]
fans_count = info[2]
pattern = re.compile(r'<div class="description.*?">(.*?)<a', re.S)
# 获取描述信息
description = pattern.findall(content)[0]
# 添加到分类列表中
classify_list.append(bean.Classify(id, k, description, articles_count, fans_count, path_name))
# 获取分类中的图书url列表
self.get_book_urls(content, id)
id += 1
# 获取图书url列表
def get_book_urls(self, content, classify_id):
# 获取分类中的图书url列表
pattern = re.compile(r'<ul class="note-list".*?>(.*?)</ul>', re.S)
note_list = pattern.findall(content)[0]
pattern = re.compile(r'<li.*?data-note-id="(.*?)".*?>.*?<a class="wrap-img" href="(.*?)" target="_blank"',
re.S)
note = pattern.findall(note_list)
for n in note:
# 获取文章id和地址
article_id = n[0]
article_url = self.home_url + n[1]
articles_list.append([article_id, classify_id, article_url])
# 获取图书信息
def get_book(self, article_id, classify_id, url):
# 解析图书信息
content = get_content(url)
pattern = re.compile(r'<h1 class=".*?>(.*?)</h1>.*?href="(/u/.*?)".*?<span.*?>(.*?)</span></a>', re.S)
ans = pattern.findall(content)
if len(ans) == 0:
return
else:
ans = ans[0]
# 获取图书标题
title = ans[0]
# 获取用户url
user_url = self.home_url + ans[1]
user_urls.append([classify_id, user_url])
# 获取用户名
name = ans[2]
pattern = re.compile(r'<article.*?>(.*?)</article>', re.S)
article_content = pattern.findall(content)[0]
# 获取评论信息
comment_url = self.get_comment_url(article_id)
comment_urls.append([article_id, classify_id, comment_url])
pattern = re.compile(
r'<i aria-label="ic-reply".*?<span.*?(\d+)</span>.*?<i aria-label="ic-like".*?<span.*?>(.*?)</span>', re.S)
comment = pattern.findall(content)[0]
views_count = random.randint(1000, 90000)
comment_count = comment[0]
pattern = re.compile(r'.*?(\d+).*?', re.S)
# 防止获取到非数字
likes_count = pattern.findall(comment[1])
if len(likes_count) == 0:
likes_count = 0
else:
likes_count = likes_count[0]
rewards_count = random.randint(10, 900)
# 下载文章中的图片
# <img data-original-src="//upload-images.jianshu.io/upload_images/25117622-c86992720337c5d4.image" data-original-width="768" data-original-height="427" data-original-format="image/png" data-original-filesize="122873">
image_pattern = re.compile(r'<img data-original-src="//upload-images.jianshu.io/upload_images/(.*?)".*?>', re.S)
image_list = image_pattern.findall(article_content)
for image in image_list:
url = "https://upload-images.jianshu.io/upload_images/" + image
file_name = str(image).split('/')[-1]
download_images(url, file_name)
# 替换掉image的地址
article_content = re.sub(image_pattern, r'<img src="\1">', article_content)
book = bean.Book(article_id, classify_id, name, title, article_content, len(article_content), views_count,
likes_count, comment_count, rewards_count)
books.append(book)
# 获取用户信息,并获取用户发布的图书信息
def get_user(self, classify_id, user_url):
content = get_content(user_url)
pattern = re.compile(r'<div class="main-top">(.*?)<ul class="trigger-menu"', re.S)
main_top = pattern.findall(content)[0]
pattern = re.compile(
r'<a class="avatar".*?<img src="(.*?)".*?<a class="name" href="/u/.*?">(.*?)</a>.*?<div class="info">.*?<ul>(.*?)</ul>',
re.S)
info = pattern.findall(main_top)[0]
head_image = info[0]
name = info[1]
password = 123
pattern = re.compile(r'.*?<i class="iconfont ic-(.*?)man"')
sex_icon = pattern.findall(main_top)
sex = "男"
# 未设置性别,默认女
if len(sex_icon) == 0:
sex = "女"
else:
sex_icon = sex_icon[0]
if sex_icon == 'wo':
sex = "女"
age = random.randint(18, 54)
address = address_list[random.randint(0, len(address_list) - 1)]
tel = 13299884565
email = format_pinyin(name) + "@QQ.COM"
pattern = re.compile(r'<li>.*?<p>(.*?)</p>.*?</li', re.S)
# 关注、粉丝、文章、字数、喜欢、资产
info = pattern.findall(info[2])
pattern = re.compile(r'<div class="description">.*?<div class="js-intro">(.*?)</div>', re.S)
profile = pattern.findall(content)[0]
# name, password, sex, age, address, tel, head_image, email, followers_count, fans_count,
# articles_count, words_count, likes_count, balance, profile, create_time
balance = str(info[5])
if balance.__contains__('w'):
balance = float(balance.split('w')[0]) * 10000
# 下载用户头像
path_name = str(head_image).split('?')[0].split('/')[-1]
download_images(head_image, path_name)
user = bean.User(name, password, sex, age, address, tel + random.randint(0, 1000), path_name, email, info[0],
info[1], info[2], info[3], info[4], balance, profile)
users.append(user)
# 获取用户的文章
self.get_book_urls(content, classify_id)
# 获取评论信息
def get_comment(self, book_id, classify_id, url):
comment_list = json.loads(get_content(url))["comments"]
for c in comment_list:
# 获取用户
user = c["user"]
# 获取用户url
user_url = self.home_url + "/u/" + user["slug"]
# [classify_id, user_url]
user_urls.append([classify_id, user_url])
# 获取评论
comment = bean.Comment(c["id"], user["id"], book_id, c["compiled_content"], c["likes_count"],
c["children_count"],
random.randint(0, 1))
comments.append(comment)
children_list = c["children"]
for c in children_list:
user = c["user"]
comment = bean.Comment(c["id"], user["id"], book_id, c["compiled_content"], 0, 0, random.randint(0, 1))
comments.append(comment)
user_url = self.home_url + "/u/" + user["slug"]
user_urls.append([classify_id, user_url])
def get_classify_url(self, v):
return self.home_url + '/c/' + v
def entrance(self):
self.get_classify_list()
print("获取文章列表")
for article in articles_list:
print(article)
time.sleep(1)
print("睡眠1s...")
self.get_book(article[0], article[1], article[2])
print("*" * 100)
print("获取用户列表")
for user in user_urls:
print(user)
self.get_user(user[0], user[1])
print("*" * 100)
print("获取评论列表")
for comment in comment_urls:
print(comment)
self.get_comment(comment[0], comment[1], comment[2])
print("*" * 100)
print("用户总数:" + str(len(users)))
print("文章总数:" + str(len(books)))
print("评论总数:" + str(len(comments)))
print("*" * 100)
print("文件写入...")
write_user()
write_classify()
write_book()
write_comment()
def get_comment_url(self, article_id):
# https://www.jianshu.com/shakespeare/notes/91220146/comments?page=1&count=10&author_only=false&order_by=desc
return self.home_url + '/shakespeare/notes/' + str(article_id) + '/comments?page=1&count=' + str(
self.comment_count) + '&author_only=false&order_by=desc'
if __name__ == '__main__':
spider = Spider()
spider.entrance()
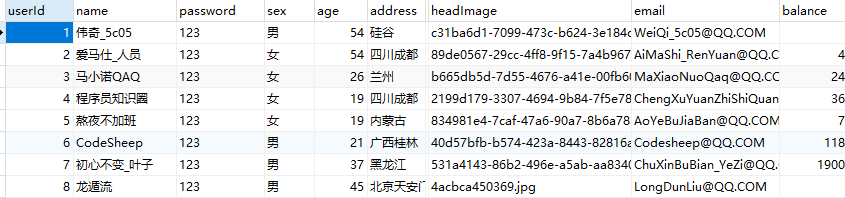
(3)效果展示