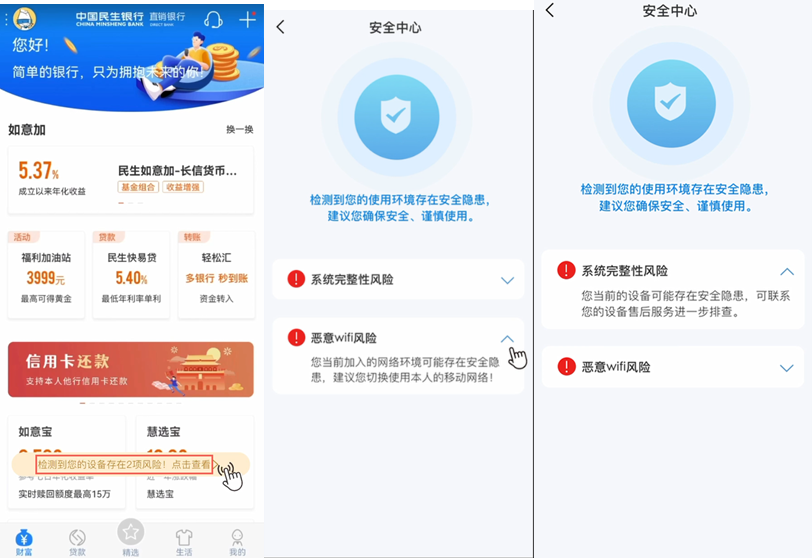
笔者申明:作为一个懒鬼+野生程序员,代码规范更风格啥的就不必苛求了,赶着上课,解析方法也只用了一个,后面有时间看心情补上吧,下面简单说一下遇到的坑点然后就上源码了
不得不说,爬虫这玩意还是比较考验耐性的,尤其是对小白来说,这次是为了完成作业踩上几个小雷,首先,拿到网站请求回来的东西就让人心态爆炸(还试图模拟app,但是遇到重定位,还是网站香啊…)
python"><!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content=