申明:本文对爬取的数据仅做学习使用,不涉及任何商业活动,侵删
爬取豆瓣电影排行榜
这是一个Scrapy框架入门级的项目, 它可以帮助我们基本了解Scrapy的操作流程和运行原理
这次我们要做例子的网站是豆瓣剧情片排行榜, 目标是爬取豆瓣排行榜里的电影信息, 比如片名, 海报, 年份等等
目标页面分析
1>分辨页面数据渲染方式
首先我们打开目标网站, 并按F12来寻找我们需要的影影片信息
 python%E7%88%AC%E8%99%AB.assets/)]" />
python%E7%88%AC%E8%99%AB.assets/)]" />
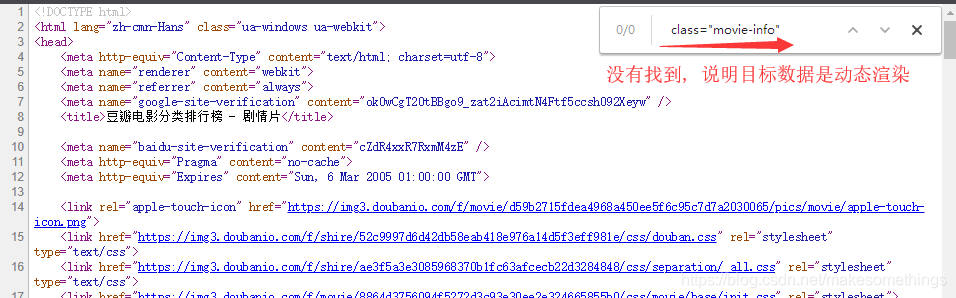
爬取网站前要区分目标数据是如何生成的, 这里看到的是渲染后的页面源码, 我们可以通过以下方式来区分是静态渲染还是动态渲染:
右键页面->选择 查看源代码, 搜索刚才看到的目标数据的信息
2>获取数据源
已经知到了页面的加载方式, 接下来我们就开始针对性的寻找数据源
既然是动态渲染, 那么它要么是通过发送ajax请求获取数据, 要么就是通过静态JS(JavaScript)渲染数据
我们再想一个问题, 这个电影网站具有如此庞大的数据, 它有可能通过静态JS渲染数据吗? 显然是不太可能的, 通过JS渲染大量数据, 需要非常多的代码
那么就只有一种可能, 就是通过JS发送ajax请求, 来从后端获取数据再渲染到页面上, 那么我们的数据源就明确了, 接下来就需要打开F12控制台中的Network, 选中XHR, 然后刷新页面就找到了数据源, 下面Preview显示的就是我们需要的电影数据
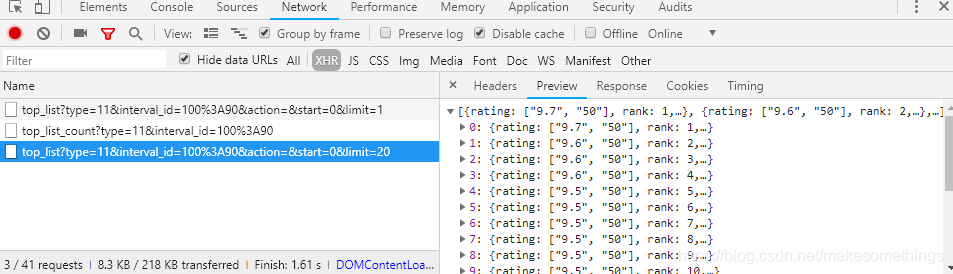
3>分析数据规则
上面获取到的请求url是:
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20
我们来访问一下这个url
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riZ3ui3S-1571143250925)(python%E7%88%AC%E8%99%AB.assets/1571142610930.png)]
显然这就是我们需要的数据, 但是这个页面只有20个结果, 为了实现批量爬取我们还需要更多的这种类型的url
因为豆瓣网的特性我们向下滚动就可以再获得一个ajax请求地址, 来对比一下:
type=11&interval_id=100%3A90&action=&start=0&limit=20
type=11&interval_id=100%3A90&action=&start=20&limit=20
唯一的变化是参数start(开始), limit是限制的意思, 这里可以理解为:
从第0个开始加载20个, 然后再从第20个开始加载
得到了上面的推论我们就可以开始着手写代码了
爬虫代码的编写
环境准备
- 编程语言: Python 3
- 爬虫框架: Scrapy 1.6.0
- 编译器: Pycharm
- 平台: Windows
Scrapy安装参考文档:windows / linux
第一步: 新建项目
- 首先要去创建一个scrapy项目框架:到期望的目录中,使用命令创建项目
scrapy startproject padouban,padouban为项目名称,创建完成后会自动生成下列文件:padouban__init__.pyscrapy.cfg#项目部署的配置文件padouban#项目目录, 包含了项目运行相关的文件__init__.pyitems.py#项目的目标文件middlewares.py#项目的中间件文件pipelines.py#项目的管道文件settings.py#项目的设置文件spiders#项目的爬虫目录__init__.py
- 创建爬虫文件,到padouban\padouban\spiders目录下,运行命令:
scrapy genspider douban movie.douban.com,douban是爬虫文件的名称,movie.douban.com是目标网站的域名,创建好爬虫文件后就可以愉快的写代码了
第二步: 设置项目目标(items)
进入items.py文件中设置爬取的目标
python"># -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class PadoubanItem(scrapy.Item):
# Field是一个容器,用来接收数据
rank = scrapy.Field() # 电影编号
cover_url = scrapy.Field() # 电影海报url
types = scrapy.Field() # 电影类型
regions = scrapy.Field() # 电影地区
title = scrapy.Field() # 电影名
movie_url = scrapy.Field() # 详情页url
release_date = scrapy.Field() # 上映时间
score = scrapy.Field() # 评分
第三步: 设置管道文件
编辑pipelines.py文件, 让目标数据流向到指定点. 这里让爬取到的数据保存到json文件中
python"># -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class PadoubanPipeline(object):
def open_spider(self, spider):
self.file = open('dou.json', 'w')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
注意: 管道文件设置好后, 需要在settings.py文件注册,一定记得注册 , 注册方法在下一步设置
第四步: 修改设置文件
设置UA信息
python"># Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
设置不遵循robots检测
robot协议限制了我们的爬取操作 , 注释掉该选项即可
python"># Obey robots.txt rules
# ROBOTSTXT_OBEY = True
设置爬取时间间隔
最好设置下载间隔 , 避免爬取操作太快被网站的反爬措施封掉
python"># See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
设置管道文件注册
这里就是注册管道 , 必要操作
python"># Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'padouban.pipelines.PadoubanPipeline': 300,
}
第五步: 编写spider
python"># -*- coding: utf-8 -*-
import scrapy
import json
from padouban.items import PadoubanItem
# 运行
class DoubanSpider(scrapy.Spider):
name = 'douban' # 爬虫名
allowed_domains = ['movie.douban.com'] # 目标网站域名
# 起始url, 豆瓣电影分类排行榜 - 剧情片
start_urls = ['https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20']
offset = 0
def parse(self, response):
list_data = json.loads(response.text) # 接收响应加载为json
item = PadoubanItem() # 实例化item对象
if not list_data: # 如果list_data没有数据,则结束执行
return
for data in list_data: # 从响应对象中获取指定数据并添加到字典item中
item['rank'] = data.get("rank")
item['cover_url'] = data.get("cover_url")
item['types'] = data.get("types")
item['regions'] = data.get("regions")
item['title'] = data.get("title")
item['movie_url'] = data.get("url")
item['release_date'] = data.get("release_date")
item['score'] = data.get("score")
yield item # 每执行一次便生成一个字典item
self.offset += 20
url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start={}&limit=20'.format(self.offset) # 目标下一组数据的网址
# 当以上代码执行结束时,使用新的url进行回调,callback即回调parse方法
yield scrapy.Request(url=url, callback=self.parse)
报错了怎么办
先排语法错误
再排拼写错误
继排逻辑错误
后排数据错误
一步一步来, 思路也会越来越清楚
![[python进阶] 线程与线程池](/images/no-images.jpg)


![[django] 会话保持及Form表单](https://img-blog.csdnimg.cn/201906042242316.png)