申明:本文对爬取的数据仅做学习使用,不涉及任何商业活动,侵删
简述
本次爬取目标是:
- 番剧的基本信息(名字, 类型, 集数, 连载or完结, 链接等)
- 番剧的参数信息(播放量, 点赞, 投币, 追番人数等)
- 时间信息(开播时间, 完结时间)
前提条件
- 编程语言: Python 3
- 爬虫框架: Scrapy 1.6.0
- 编译器: Pycharm
- 平台: Windows
Scrapy安装参考文档:windows / linux
一丶页面分析
番剧索引页展示的番剧信息属于动态渲染, 因此要通过获取页面响应来得到我们想要的数据, 按F12到Network中找我们需要的响应数据:


来分析一下Request URL, 先无事其他的参数, 来看我们最需要的一部分: page=1&...&pagesize=20
page:表示当前页码pagesize:表示页面展示的番剧数
可以尝试访问Request URL, 来确认可以拿到我们需要的数据:

这一个请求并不能满足需求, 跟进番剧页链接, 并继续找响应数据:


几乎所有的数据都被我们得到了, 但唯独缺一个番剧类型
跟进番剧简介网址:https://www.bilibili.com/bangumi/media/md102392, 这是一个静态页面, 可以直接从响应中获取到我们需要的信息:
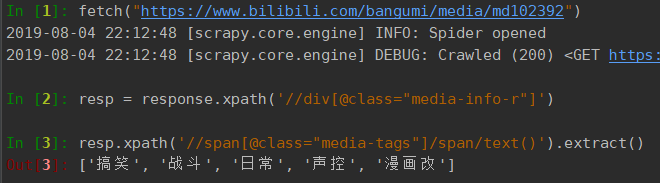
完成可数据源的分析, 接下来开始写代码
二丶创建爬虫
- 打开cmd控制台,然后cd+路径,移动到到期望的目录中,使用命令创建项目
scrapy startproject bilibili_spider,bilibili_spider为项目名称,创建完成后会自动生成下列文件: - 创建爬虫文件,到bilibili_spider\bilibili_spider\spiders目录下,运行命令:
scrapy genspider bilibili bilibili.com,bilibili是爬虫文件的名称,后面是目标网站的域名, 由于本次爬取涉及的站点较多, 这里可以将www省略掉, 以避免出错
items.py
进入items.py文件中设置爬取的目标,基于python之禅简单生于复杂, 我将上述最后两次请求合并到一个, 即从番剧详情页获取评论数和评分
python">import scrapy
class BilibiliSpiderItem(scrapy.Item):
# 索引页的ajax 可以获得以下信息:
season_id = scrapy.Field() # 番剧编号
media_id = scrapy.Field() # 媒体编号
title = scrapy.Field() # 标题
index_show = scrapy.Field() # 集数
is_finish = scrapy.Field() # 是否完结
video_link = scrapy.Field() # 链接
cover = scrapy.Field() # 封面图
pub_real_time = scrapy.Field() # 真实发布日期
renewal_time = scrapy.Field() # 最近更新日期
# 番剧信息的ajax请求:
favorites = scrapy.Field() # 追番
coins = scrapy.Field() # 硬币
views = scrapy.Field() # 播放量
danmakus = scrapy.Field() # 弹幕
# 番剧详情页的ajax请求:
cm_count = scrapy.Field() # 评论数
score = scrapy.Field() # 评分
media_tags = scrapy.Field() # 类型标签
爬虫文件
python"># -*- coding: utf-8 -*-
import json
from datetime import datetime
import scrapy
from scrapy.spiders import CrawlSpider
from bilibili_video.items import BilibiliSpiderItem
class BilibiliSpider(CrawlSpider):
name = 'bilibili'
allowed_domains = ['bilibili.com']
# 索引页的ajax
request_url = 'https://bangumi.bilibili.com/media/web_api/search/result?page={}&season_type=1&pagesize=20'
page = 1
start_urls = [request_url.format(page)]
# 番剧信息的ajax请求
season_url = 'https://bangumi.bilibili.com/ext/web_api/season_count?season_id={}&season_type=1&ts={}'
# 番剧详情页的ajax请求
media_url = 'https://www.bilibili.com/bangumi/media/md{}'
def parse(self, response):
# if self.page == 2: # 限制爬取页数,用于测试爬取状态
# return
list_data = json.loads(response.text).get('result').get('data')
if list_data is None: # 如果响应中没有数据,则结束执行
return
for data in list_data:
ts = datetime.timestamp(datetime.now())
yield scrapy.Request(url=self.season_url.format(data.get('season_id'), ts),
callback=self.parse_details,
meta=data)
self.page += 1 # 生成下一页的请求
yield scrapy.Request(url=self.request_url.format(self.page),
callback=self.parse)
def parse_details(self, response):
item = BilibiliSpiderItem()
meta_data = response.meta
item['season_id'] = meta_data.get('season_id')
item['media_id'] = meta_data.get('media_id')
item['title'] = meta_data.get('title')
item['index_show'] = meta_data.get('index_show')
item['is_finish'] = meta_data.get('is_finish')
item['video_link'] = meta_data.get('link')
item['cover'] = meta_data.get('cover')
item['pub_real_time'] = meta_data.get('order').get('pub_real_time')
item['renewal_time'] = meta_data.get('order').get('renewal_time')
resp_data = json.loads(response.text).get('result')
item['favorites'] = resp_data.get('favorites')
item['coins'] = resp_data.get('coins')
item['views'] = resp_data.get('views')
item['danmakus'] = resp_data.get('danmakus')
yield scrapy.Request(url=self.media_url.format(item['media_id']),
callback=self.parse_media,
meta=item)
def parse_media(self, response):
item = response.meta
resp = response.xpath('//div[@class="media-info-r"]')
item['media_tags'] = resp.xpath('//span[@class="media-tags"]/span/text()').extract()
item['score'] = resp.xpath('//div[@class="media-info-score-content"]/text()').extract()[0]
item['cm_count'] = resp.xpath('//div[@class="media-info-review-times"]/text()').extract()[0]
yield item
项目源码链接:https://github.com/zhanghao19/bilibili_spider
![[django项目] 用户注册功能 之 用户模型与图片验证码](https://img-blog.csdnimg.cn/2019092309411021.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)
![[django项目] 用户注册功能 之 用户名与手机号校验](/images/no-images.jpg)
![[django项目] 用户注册功能 之 发送短信验证码](https://img-blog.csdnimg.cn/20190813202222903.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)
![[django项目] 用户注册功能 之 注册用户到数据库](https://img-blog.csdnimg.cn/20190814071815556.png)
![[django项目] 实现用户登录登出功能](https://img-blog.csdnimg.cn/20190814080820539.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)
![[django项目] 用户注册登录模块复盘+总结](https://img-blog.csdnimg.cn/20190814230545752.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)
![[django项目] 新闻首页功能 之 文章标签导航与新闻列表](https://img-blog.csdnimg.cn/20190819110728943.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)
![[django项目] 新闻首页功能 之 展示点击量最高的文章](https://img-blog.csdnimg.cn/20190819123026471.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21ha2Vzb21ldGhpbmdz,size_16,color_FFFFFF,t_70)