Scrapy框架
-
什么是scrapy框架
Scrapy 是一个为了抓取网页数据、提取结构性数据而编写的应用框架,该框架是封装的,包含 request (异步调度和处理)、下载器(多线程的 Downloader)、解析器(selector)和 twisted(异步处理)等。对于网站的内容爬取,其速度非常快捷。 -
安装
pip install scrapy -
创建一个工程(终端):
python"># 在终端运行如下命令
# 第一步 创建项目
scrapy startproject xxx # xxx是项目的名称
# 第二步 进入项目
cd xxx
# 第三步 创建爬虫文件
scrapy genspider spiderName www.xxxxx.com # 网址为你要爬取的网站刚开始也可以随意写,后面可以在项目中改
创建项目完成后的文件目录结构
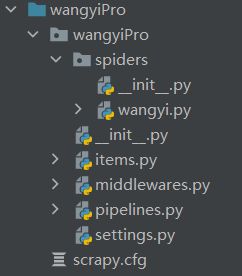
各文件的作用(根据我自己的项目)
- scrapy.cfg: 项目的配置文件,一般不需要更改。
- scrapy文件夹 存放爬虫代码
- wangyi.py: 爬虫代码,初步处理数据
- items.py: 定义爬取的数据类,
- middlewares.py 中间件文件,自定义
- pipelines.py: 管道文件 接受item.py中的数据 当我们的items被返回的时候,会自动调用我们的pipelines类中process_item()(需要加到settings.py里面)
- settings.py: 项目的设置文件。设置伪装方式,ip代理
- piders/: 放置spider代码的目录。
执行工程:
- scrapy crawl spiderName # 运行项目
-
scrapy持久化存储:
- 基于管道:
- 编码流程:
- 数据解析
- 在item中定义相关属性
- 将解析的数据封装储存到list类型的对象
- 将item类型的对象提交给管道进行持久化存储的操作
- 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 在配置文件中开启管道
- 好处:
- 通用性强
- 编码流程:
- 面试题
将爬取到的数据一份存储到本地,一份存储到数据库,如何实现- 管道文件中一个管道类对应的是将数据储存到一个平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接受
- process_item中的return item 表示将item传递给下一个即将被执行的管道类
- 基于管道:
-
scrapy五大核心组件:




