2019独角兽企业重金招聘Python工程师标准>>> 
# 导入 Request模块
# 若本机无自带Request模块,可自行下载或者使用pip进行安装
# python版本Python3
import requests
import json
#######################Get请求#######################
# 发送无参数的get请求
baiDu_response = requests.get('http://www.baidu.com')
# 发送无参数的get请求 设置超时时间 timeout 单位秒
baiDu_response = requests.get('http://www.baidu.com', timeout=1)
# 查看发送请求的url地址
print('无参数的get请求地址为: ' + baiDu_response.url)
# 查看当前返回状态码
# 若状态码为200 等同于 baiDu_response.status_code == requests.codes.ok 返回为True
print('返回的状态码为: '+str(baiDu_response.status_code))
# 查看当前返回内容编码
print('返回内容编码格式为:' + baiDu_response.encoding)
# 查看当前返回内容 text返回的是字符串
print('Text返回的数据内容为:' + baiDu_response.text)
# 查看当前返回内容 content返回的是字节流
# print('Content返回的数据内容为:' + baiDu_response.content)
# 若返回内容为json格式 可用如下语句
# print('返回的Json数据为:' + baiDu_response.json())
# 获取服务器返回的原始数据 增加stream=True
# data = requests.get('https://api.github.com/events', stream=True)
# print(data.raw.read())
# 发送带参数(字典形式)的get请求
sendDictParams = {'key1': 'value1', 'key2': 'value2'}
baiDu_dictParams_response = requests.get('http://www.baidu.com', params=sendDictParams)
# 查看发送请求的url地址
print('普通参数的get请求地址为: ' + baiDu_dictParams_response.url)
# 发送list格式参数的get请求
sendListParams = {'key1': 'value1', 'key2': ['value2', 'value3']}
baiDu_listParams_response = requests.get('http://www.baidu.com', params=sendListParams)
# 查看发送请求的url地址
print('带list参数的get请求地址为: ' + baiDu_listParams_response.url)
#######################Post请求#######################
# tips:强烈建议使用二进制模式打开文件,因为如果以文本文件格式打开时,可能会因为“Content-Length”这个header而出错
# post 请求参数是通过data方式来传递的
# 第一种方式:字典格式
postResponse = requests.post("http://pythontab.com/postTest", data={'key': 'value'})
print('普通参数请求返回状态码为:' + str(postResponse.status_code))
# 第二种方式 json格式 注意json方法为dumps() 不是dump()
jsonParams = {'key': 'value'}
postJsonResponse = requests.post("http://pythontab.com/postTest", data=json.dumps(jsonParams))
print('json参数请求返回状态码为:' + str(postJsonResponse.status_code))
# 第三种方式 发送文件 (该文件同级目录下需要有test.csv文件 )rb 只读模式 wb 若没有 自动创建
files = {'file': open('test.csv', 'rb')}
fileResponse = requests.post('http://pythontab.com/postTest', files=files)
print('文件参数请求返回状态码为:' + str(fileResponse.status_code))
#######################Headers#######################
headers_response = requests.get('http://www.baidu.com')
# 查看请求响应头 :字典格式 输入时转换为字符打印到控制台
print('请求响应头为: ' + str(headers_response.headers))
# 获取请求响应头其中某一个参数
print('请求响应头的Server参数 写法一:' + headers_response.headers['Server'])
# 等同于
print('请求响应头的Server参数 写法二:' + headers_response.headers.get('Server'))
# 自定义headers 并发送
headers = {'user-agent': 'myAgent'}
custom_headers_response = requests.get('http://www.baidu.com', headers=headers)
print('自定义header发送请求状态码为:' + str(custom_headers_response.status_code))
#######################Cookies#######################
cookies_response = requests.get('http://www.baidu.com')
# 查看请求响应头 :字典格式 输入时转换为字符
print('请求地址的Cookies为: ' + str(cookies_response.cookies))
# 自定义Cookies 并发送
cookies = {'user-cookies': 'myCookies'}
custom_cookies_response = requests.get('http://www.baidu.com', cookies=cookies)
print('自定义Cookies发送请求状态码为:' + str(custom_cookies_response.status_code))
#######################代理#######################
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
# 通过代理方式发起请求 此处运行不通过,仅举例使用
# requests.get("http://baidu.com", proxies=proxies)
#######################Session#######################
# 通过requests获取session
session = requests.Session()
# 举例:登录名 密码 key为登陆表单中对应的input的name值
login_data = {'email': 'email@example.com', 'password': 'password'}
# 发送数据
session.post("http://pythontab.com/testLogin", login_data)
# 获取发送的session
session_response = session.get('http://pythontab.com/notification/')
print('session请求返回的状态码为:' + str(session_response.status_code))
#######################下载页面#######################
baiDuHtmlContent = requests.get("http://www.baidu.com")
with open("百度.html", "wb") as html:
html.write(baiDuHtmlContent.content)
html.close()
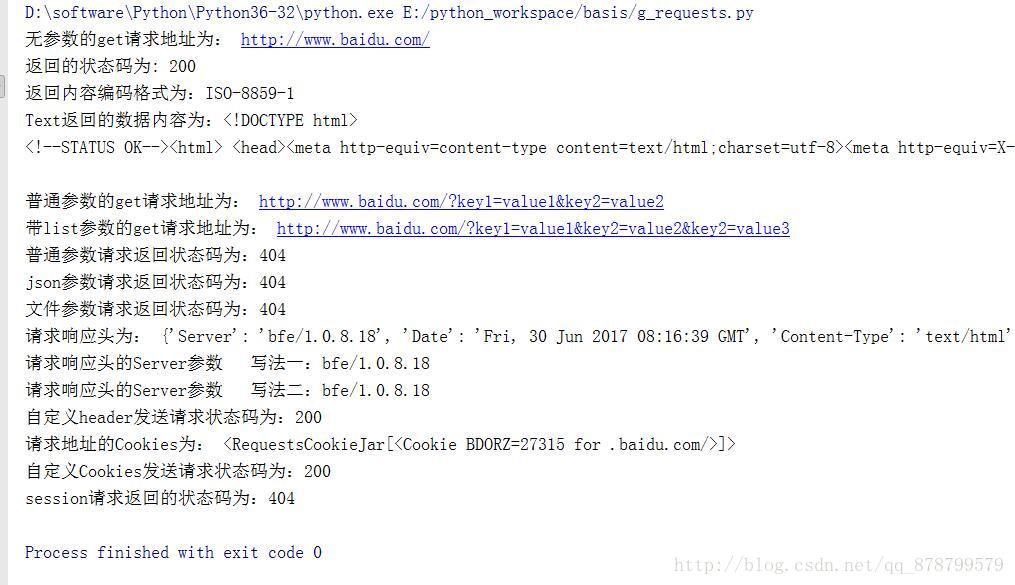
运行结果
参考:www.pythontab.com/html/2017/pythonjichu_0510/1138.html