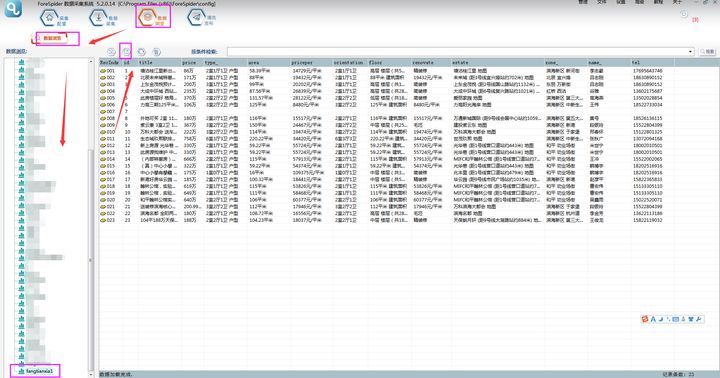
采集网站
【场景描述】通过搜狗搜索的知乎搜索栏目,按关键词搜索采集知乎正文
【入口网址】https://zhihu.sogou.com

【采集内容】
本次采集的数据为知乎文章的标题和内容
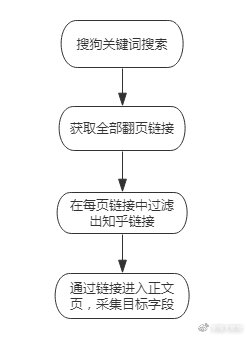
l 思路分析
功能点总结:关键词配置链接、翻页、链接抽取、数据抽取
 配置思路
配置思路
l 配置步骤
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可。由于本次采集是通过关键词采集相关内容,所以【采集类型】要勾选【关键词采集】,填写完成。
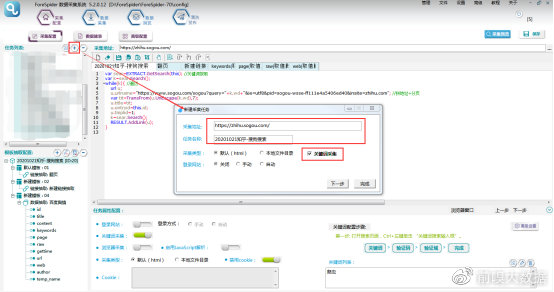
点击【完成】,任务列表里出现本条任务,即为创建成功。
2. 关键词配置
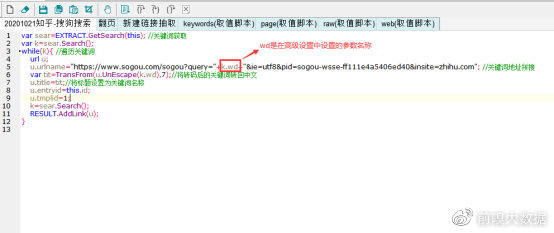
①在入口页搜索不同关键词,发现不同关键词搜索结果的链接,只更换了图中红框部分,而红框部分正是经过转码后的关键词,于是得出关键词链接的拼接规则为:
https://www.sogou.com/sogou?query=关键词
ie=utf8&pid=sogou-wsse-ff111e4a5406ed40&insite=zhihu.com

②得到关键词链接拼接规则后,开始配置关键词搜索:
点击屏幕右下角【高级配置】,将采集地址填写到【请求地址】中,点击【+】添加一个参数,名称可以自定义,此项配置是用于后期脚本能将关键词从关键词列表中取出,配置完成点击【确定】即可。
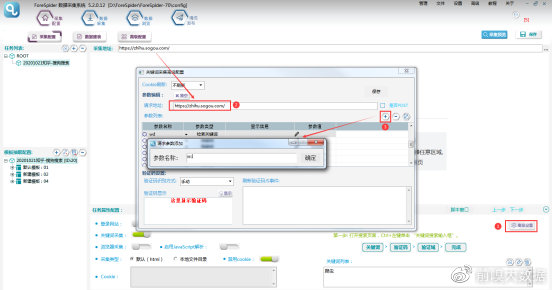
③由于本模板是以关键词搜索为入口,所以在【模板抽取配置】选择频道(即任务名称),选择【脚本窗口】,将关键词搜索配置在频道处即可。
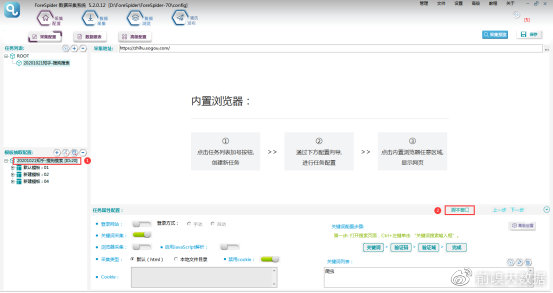
④具体配置脚本如下:
⑤效果预览:
在【关键词列表】中填写关键词,点击【保存】,点击【采集预览】,即可看到配置效果。
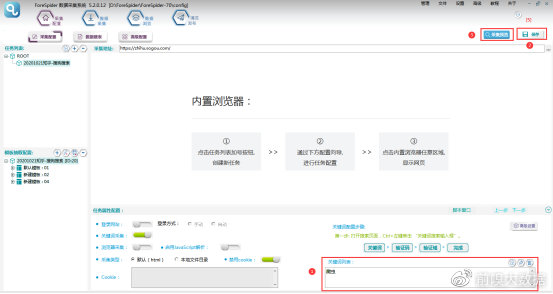
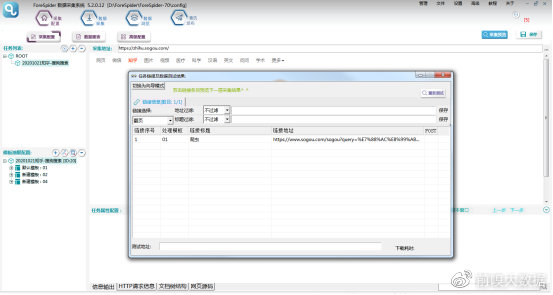
3. 翻页配置
关键词配置完成,下一步是获取关键词搜索结果中的全部翻页链接。
①右键点击【默认模板:01】,选择添加链接抽取。
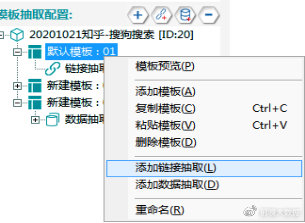
②同样选择【脚本窗口】,配置翻页脚本。
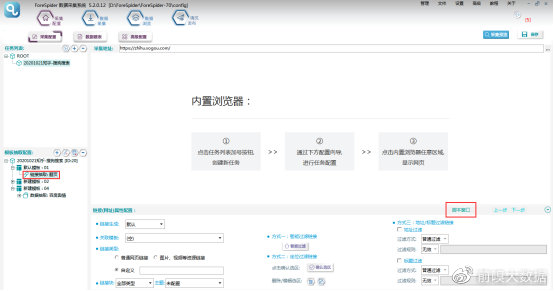
③对关键词搜索出的网页翻页,观察网页地址的变化,发现在原地址中增加了“&sut=2674&sst0=1617764379159&lkt=1%2C1617764379044%2C1617764379044&page=2&ie=utf8”部分,随着页码的改变,仅有page参数的值在变化。page为页码的配置参数,其它不变部分,直接拼接在链接中即可。

④具体配置脚本如下:
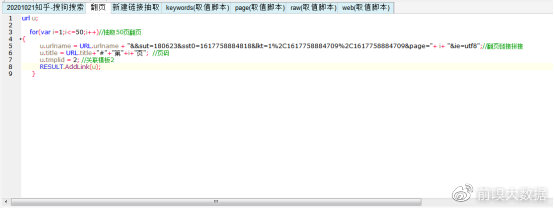
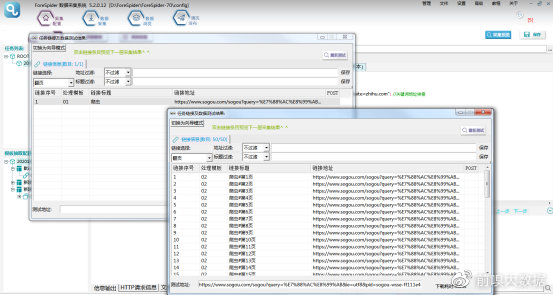
⑤效果预览:
4. 链接抽取
这一步是在获取的翻页链接中,提取每页全部知乎问题链接:
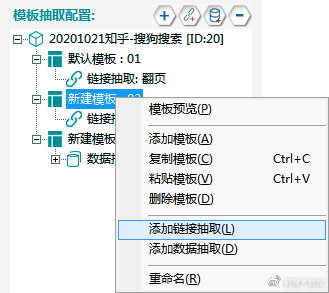
①在原有模板基础上,右键选择【添加模板】
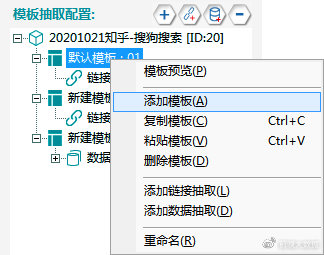
②右键新添加的模板,选择【添加链接抽取】
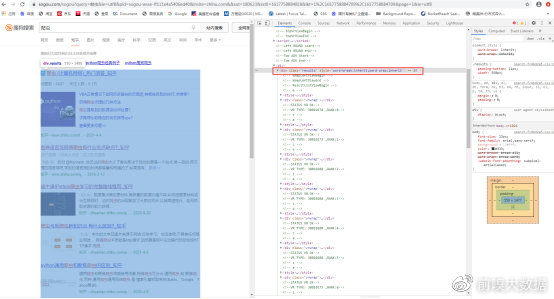
③以第一页为例,查看网页结构(可以使用F12查看,但需确认源码与F12内容一致)。
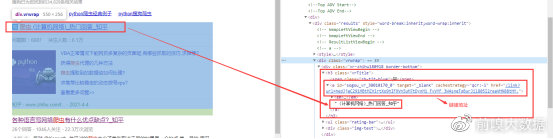
通过查看网页结构,发现所需要的链接全部包含在“results”类中。每个链接块对应一个“vrwrap”类,我们所需要的内容,全部包含在“vrwrap”类的h3结点“vrTitle”中,“vrTitle”的子结点a标签内为该条内容的链接地址和标题内容。
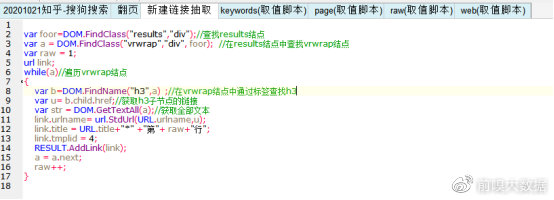
④同样选择当前链接抽取,在【脚本窗口】中编写脚本,具体脚本内容如下:
⑤效果预览:
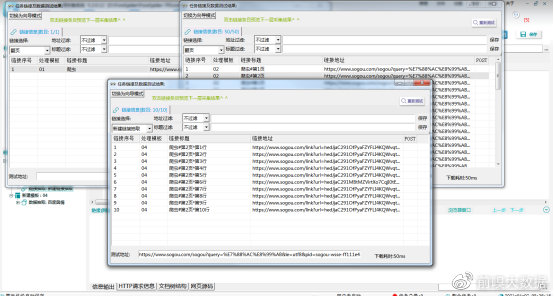
5. 数据抽取
①链接抽取完成进入数据页,在原有模板基础上,右键选择【添加模板】,新添加的模板,右键【添加数据抽取】。
②此时要完成数据建表的工作:
a.选择【数据建表】,点击【采集数据表结构】中的【+】,即可添加数据表,名称可以自定义。
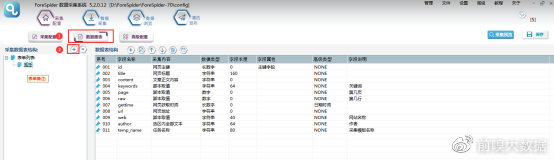
b.选中数据表,在数据表结构中点击【+】,添加字段。如图所示,我们需要的字段均以添加到数据表中,额外添加了网页地址、获取时间、任务名称等是为了后期查找内容更方便。另外需要注意,每一个表单都需要配置主键字段,需要使用脚本的字段,在高级类型中选择脚本取值才可进行脚本操作,其它字段根据实际需求配置即可。
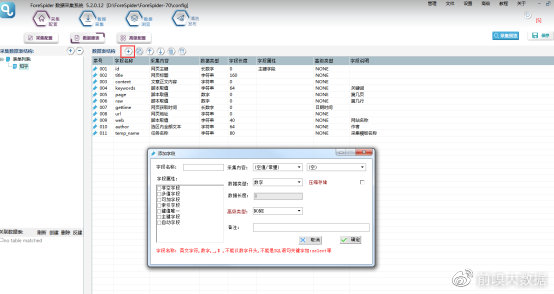
③数据表配置完成,选择【数据抽取】右侧数据属性配置,表单选择刚建立的“知乎”数据表,则可看到表单中的字段在右侧显示。
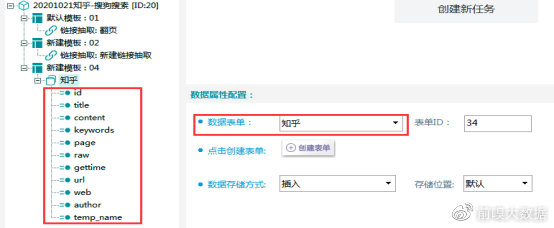
④需要配置哪一个字段,点击该字段,在右侧字段属性中配置即可,选择脚本配置的字段,在脚本窗口中进行代码配置。
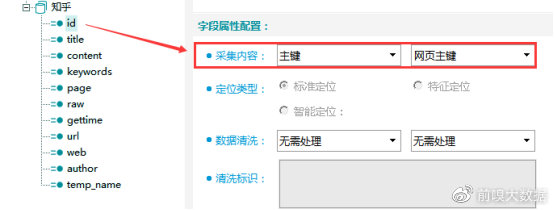
id字段:主键字段,采集内容选择【主键】-【网页主键】,主键为当前网页的MD5值。
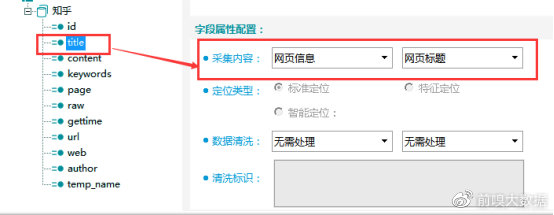
title字段:网页标题字段,采集内容选择【网页信息】-【网页标题】
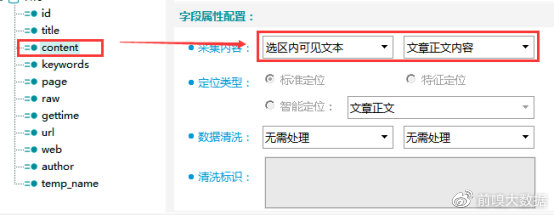
content字段:正文字段,采集内容选择【选区内可见文本】-【文章正文内容】
keywords字段:关键词字段,该字段是用脚本处理的,由于关键词字段仅是频道脚本中的局部变量,且后期页面均没有出现,所以需要将关键词字段赋值在全局变量中,才能在数据抽取时将关键词字段提取出来,此处将其赋值与全局变量title。

同理,数据表中需要采集当前数据在第几页出现,而页面数据同样为翻页模板中的局部变量,后面模板无法提取,所以需要将当前翻页脚本中的页数记录在全局变量中,同样将页数记录在title中以“#”与关键词分隔。
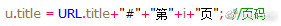
当前数据出现在某页第几行,页码已经记录在全局变量title中,链接抽取中当前链接行数也是唯一出现的局部变量,同样需要记录才能传值,于是将行数也赋值在title中以“*”与页码分隔。
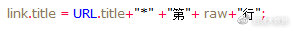
所以最终记录在title中的值包含以下部分:
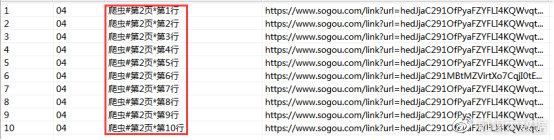
对于keywords字段来说,取出全局变量title中“#”左边部分即可。
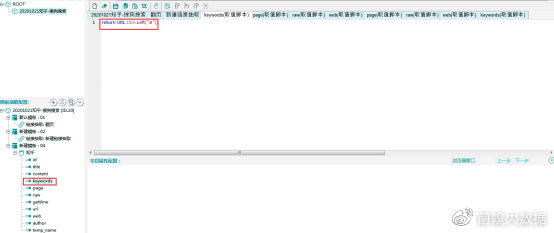
page字段:页码,同keywords字段,取全局变量title中“#”和“*”中间部分。
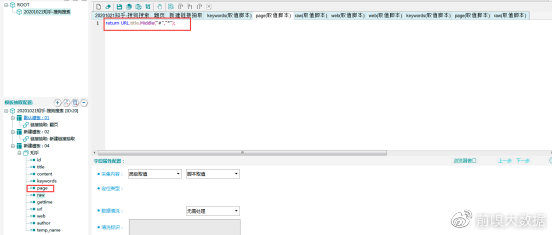
raw字段:行数,同keywords字段,取全局变量title中“*”右侧部分。
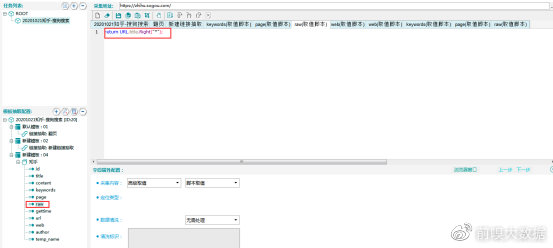
gettime字段:网页采集时间,采集内容选择【时间信息】-【网页获取时间】
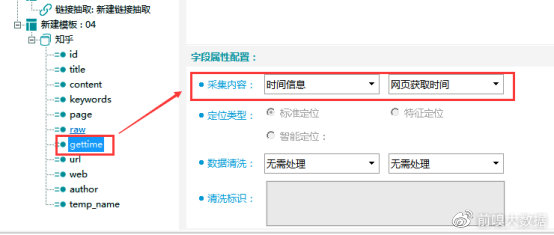
url字段:网页地址,采集内容选择【网页信息】-【网页地址】
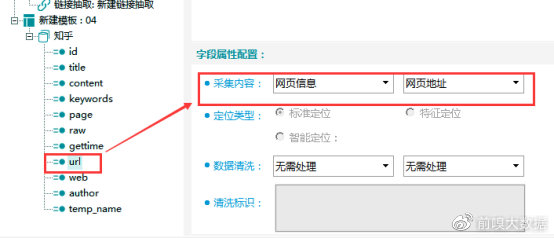
web字段:网站名,脚本返回“知乎”。
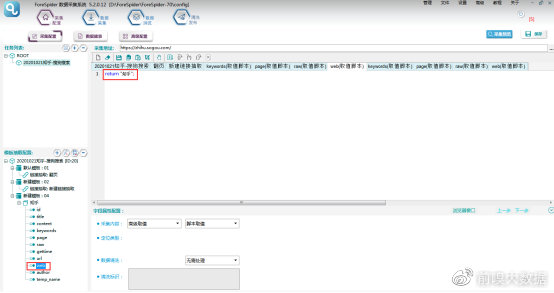
author字段:可以采用可视化配置,【采集内容】选择【选区内可见文本】-【选区内全部文本】,【定位类型】选择【标准定位】,Ctrl+鼠标左键选中选区,点击下方【字段定位取值】,然后确认选区,字段配置完成。
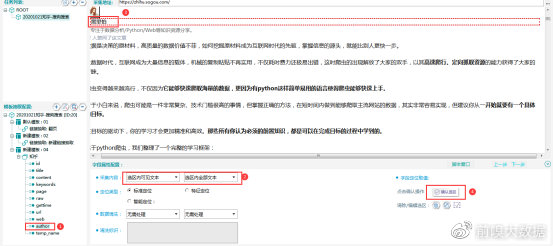
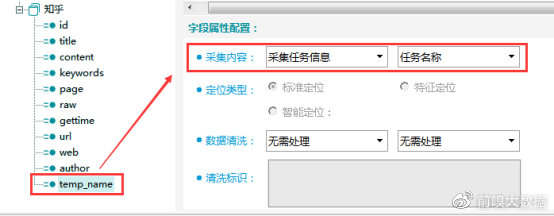
temp_name字段:模板名称,采集内容选择【采集任务信息】-【任务名称】
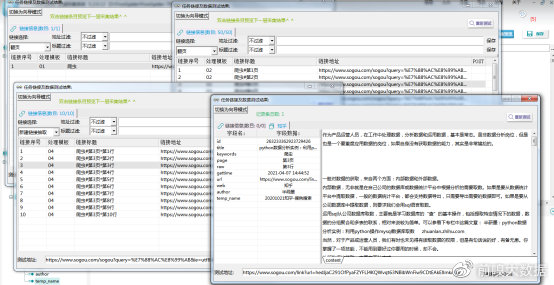
⑤以上完成全部字段配置,效果预览如下:
l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
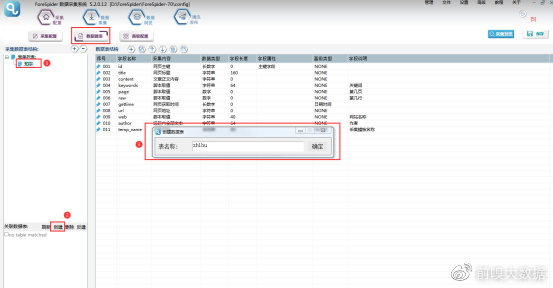
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为zhihu(注意命名不能用数字和特殊符号),点击【确定】。
创建完成,勾选数据表。
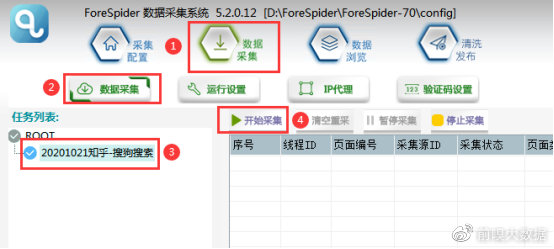
②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
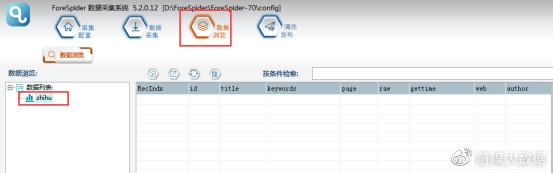
③可以在【数据浏览】中,选择数据表查看采集数据。
l 课后回顾
GetSearch():返回关键词列表中的关键词。

Search():反复调用来遍历关键词列表。
FindClass(class名,标签类型,开始查找结点):当符合条件的class名称唯一时,使用class名来查找结点。
FindName(标签名,开始查找结点):当查找范围内,符合条件的数据标签唯一时,可以使用标签名称查找标签结点。
GetTextAll(需要获取文本的结点,使用的字符编码):获取该html标签节点及所有子节点的可见文本。