l 采集网站
【场景描述】采集上海交通大学最新招聘信息。
【爬虫下载】http://forenose.com/view/forespider/view/download.html
【入口网址】https://postd.sjtu.edu.cn/bshzp/10.htm
【采集内容】
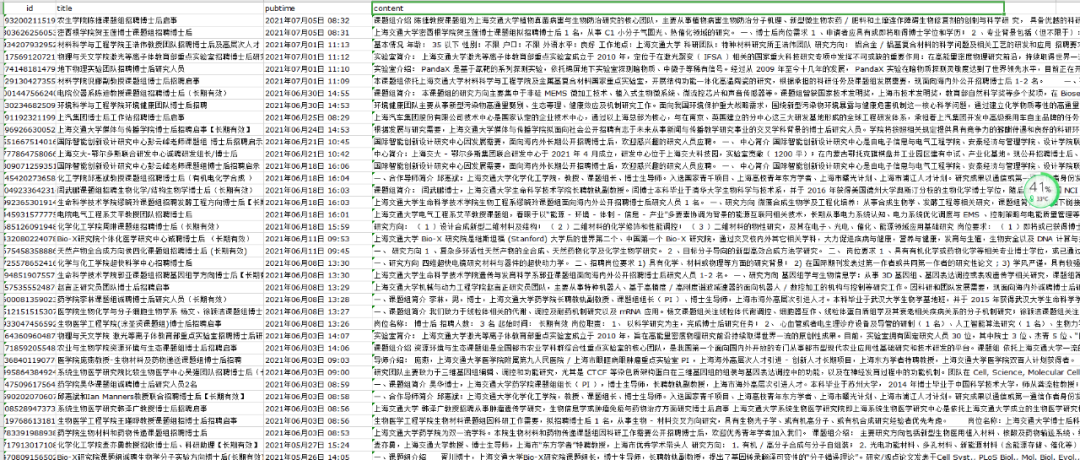
采集该网站上发布的招聘公告信息,采集字段为:招聘标题、发布时间、招聘正文。
l 思路分析
配置思路概览:

l 配置步骤
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
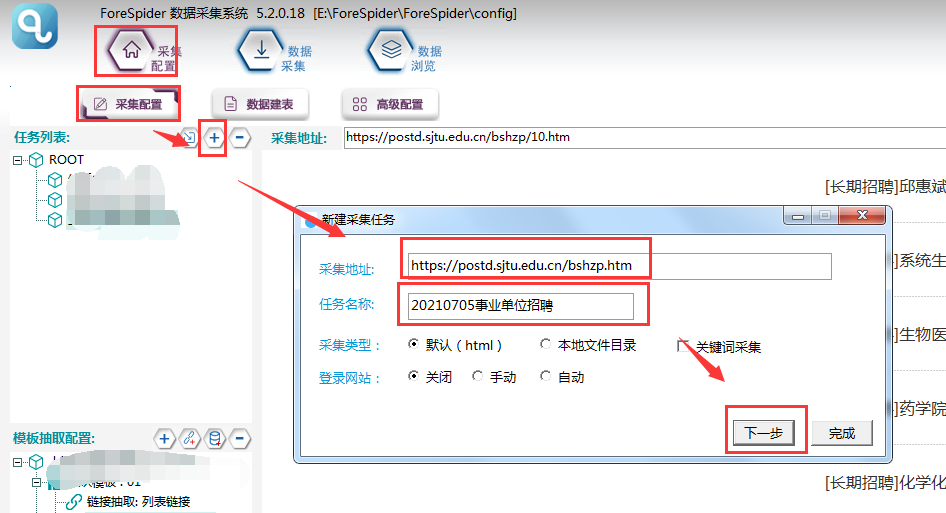
继续勾选列表链接、普通翻页,然后点击完成,创建成功。
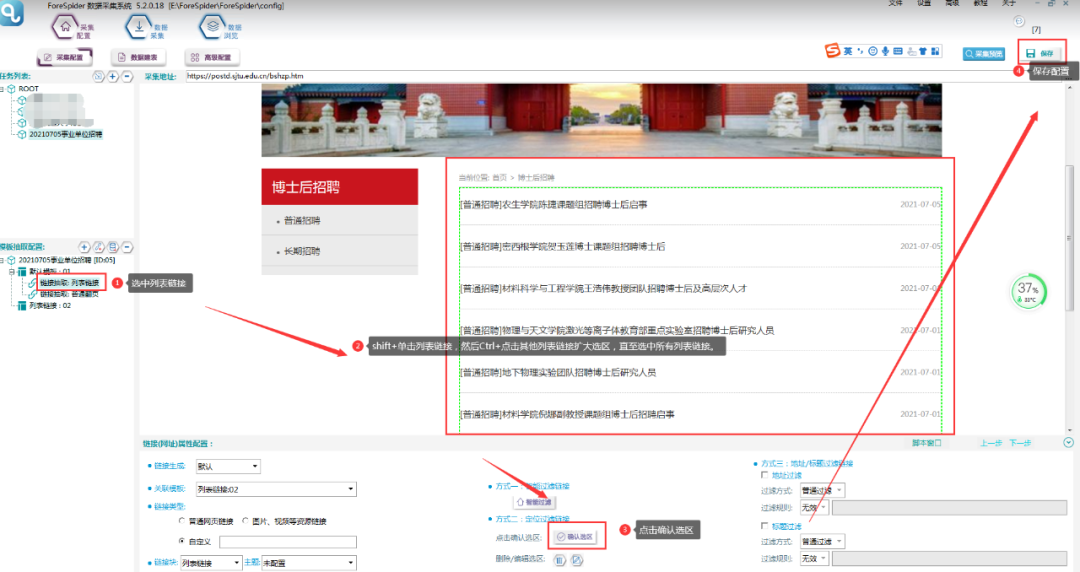
2. 抽取列表链接
配置列表链接,将所有招聘公告的链接都抽取出来,在此使用定位过滤链接的方法来抽取列表链接。具体操作如下图所示:
①选中模板中的链表链接。
②选中列表链接选区,shift+鼠标单击某个链接,Ctrl、+鼠标单击其他翻页扩大选区,从而选中所有列表链接。
③点击【确认选区】。
④保存配置。
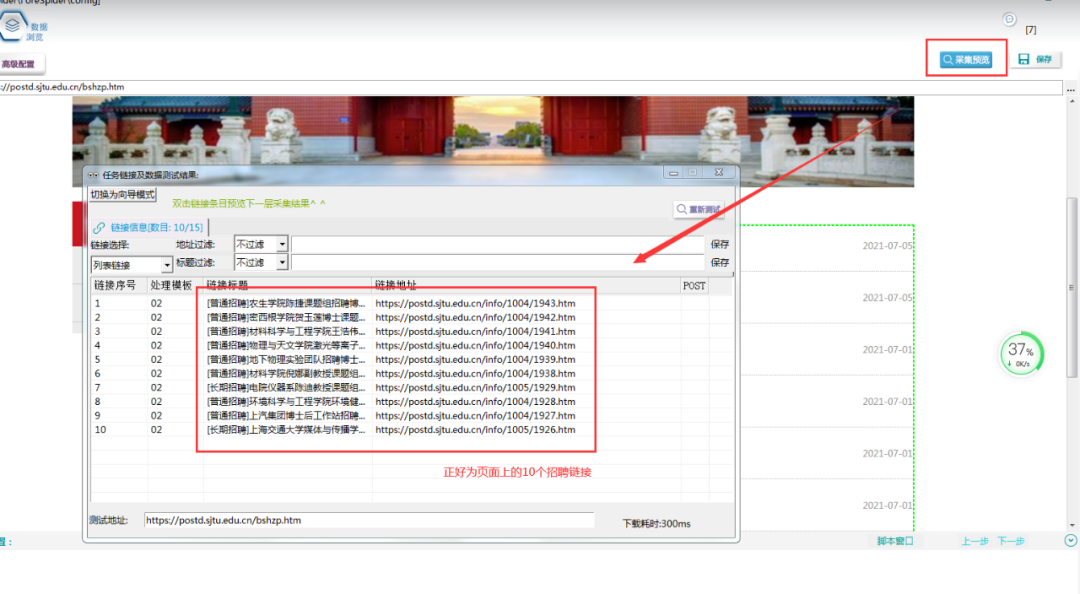
⑤采集预览
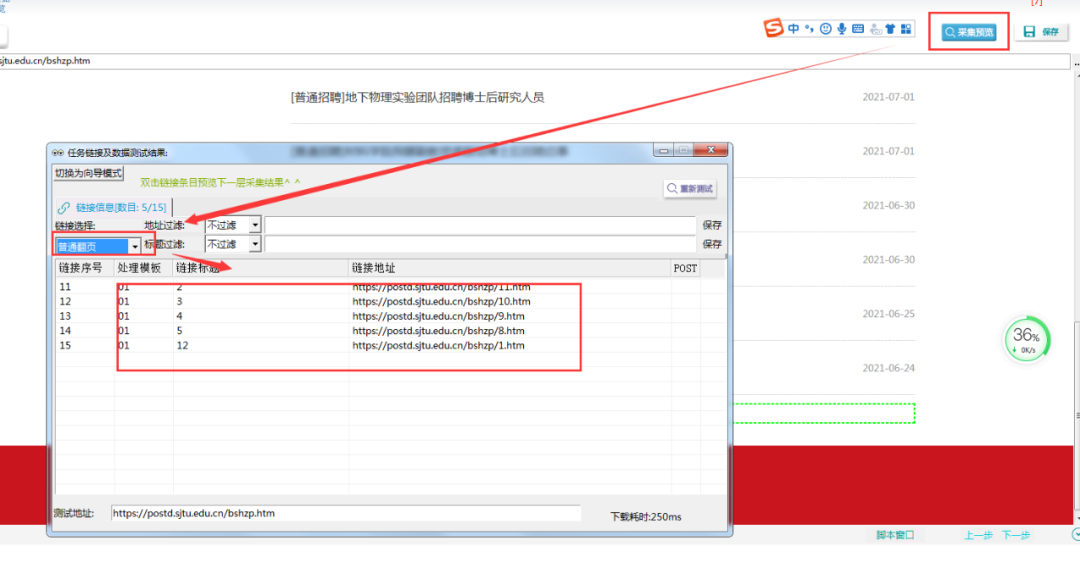
点击右上角【采集预览】,看所需要的列表链接是否都抽取出来。
3. 抽取翻页
翻页抽取也是用定位过滤链接的方法,进行抽取。具体如下图所示:
①选中模板中的普通翻页链接抽取。
②选中所有翻页选区,shift+鼠标单击某个翻页,Ctrl+鼠标单击其他翻页扩大选区,从而选中所有翻页。
③确认选区。
④点击【保存】按钮,保存配置。
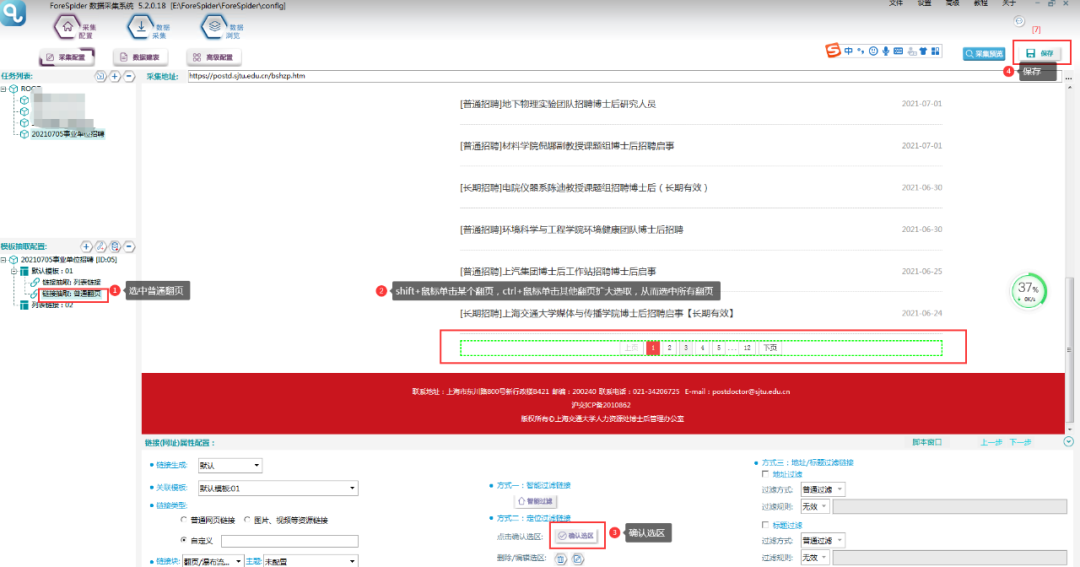
⑤采集预览
点击右上方【采集预览】,选择普通翻页,查看是否采集到所以翻页,如下图所示即为采集到。
4. 关联模板
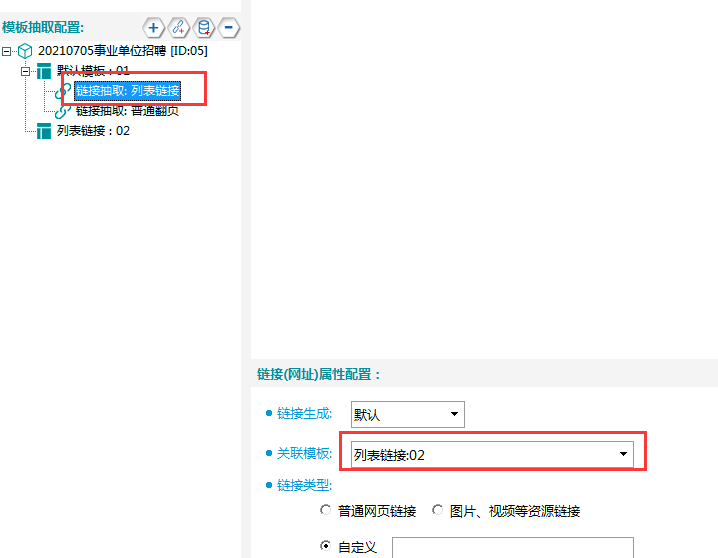
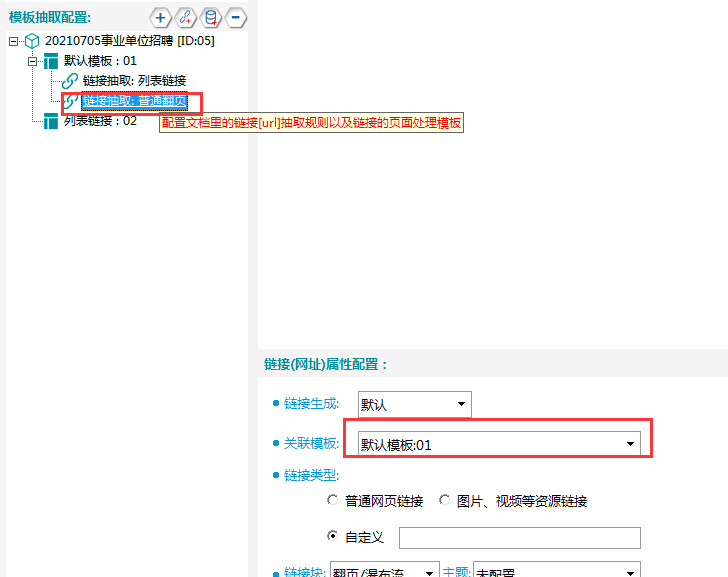
检查模板01中的两个链接抽取关联模板是否正确。列表链接应关联模板02,普通翻页应关联模板01,分别如下图所示。
5. 数据抽取
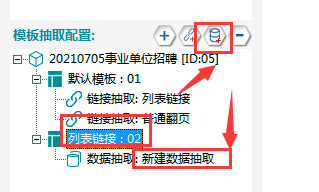
①选中列表链接02,新建一个数据抽取。具体操作如下图所示:
②此时要完成数据建表的工作:选择【数据建表】,点击【采集数据表结构】中的【+】,即可添加数据表,名称可以自定义。
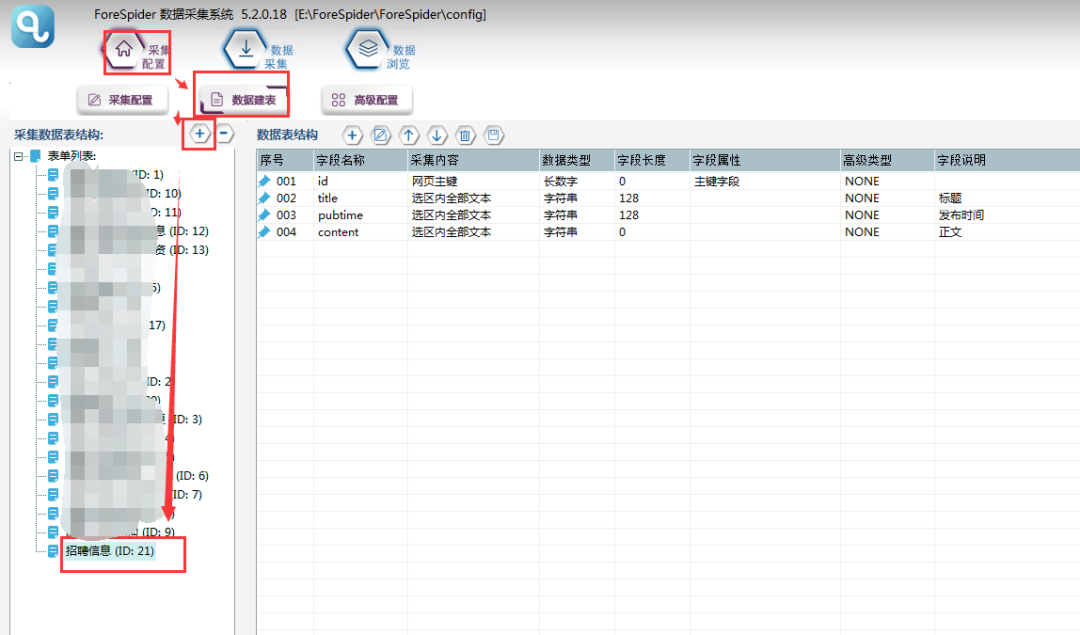
添加字段,各字段属性如下图所示:

③数据表配置完成,选择【数据抽取】右侧数据属性配置,表单选择刚建立的“招聘信息”数据表,则可看到表单中的字段在右侧显示。
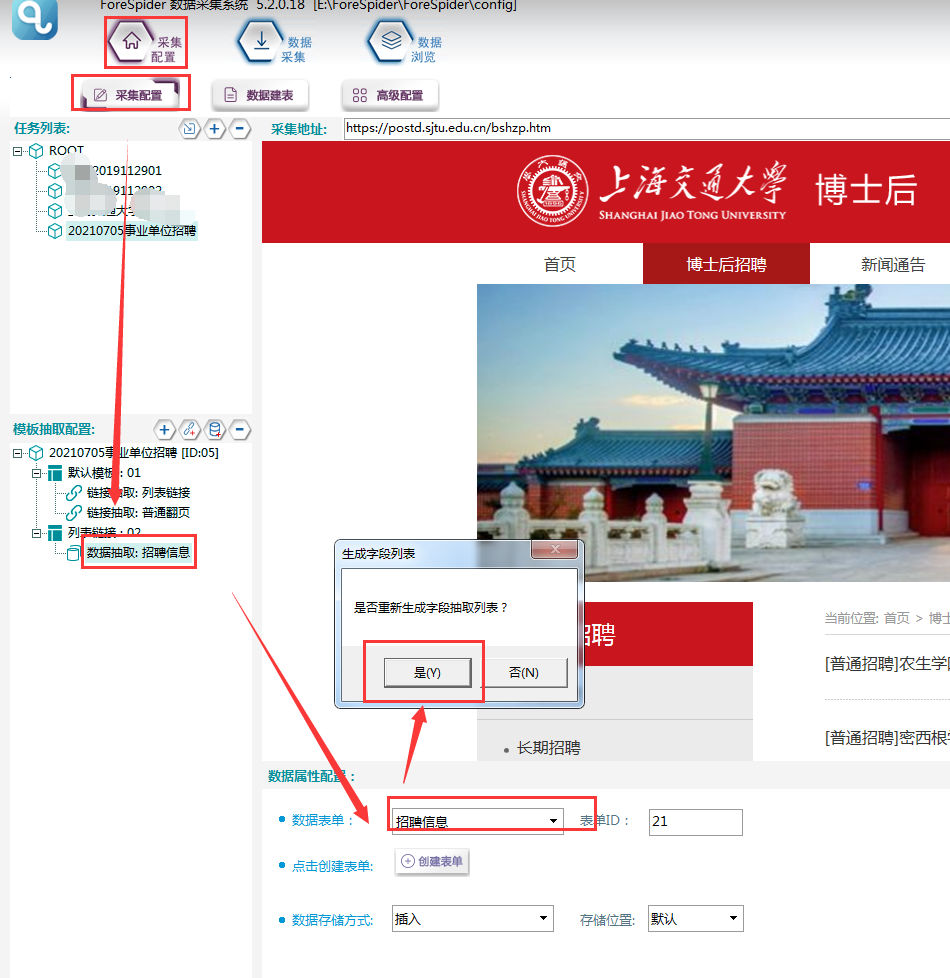
④填写示例地址
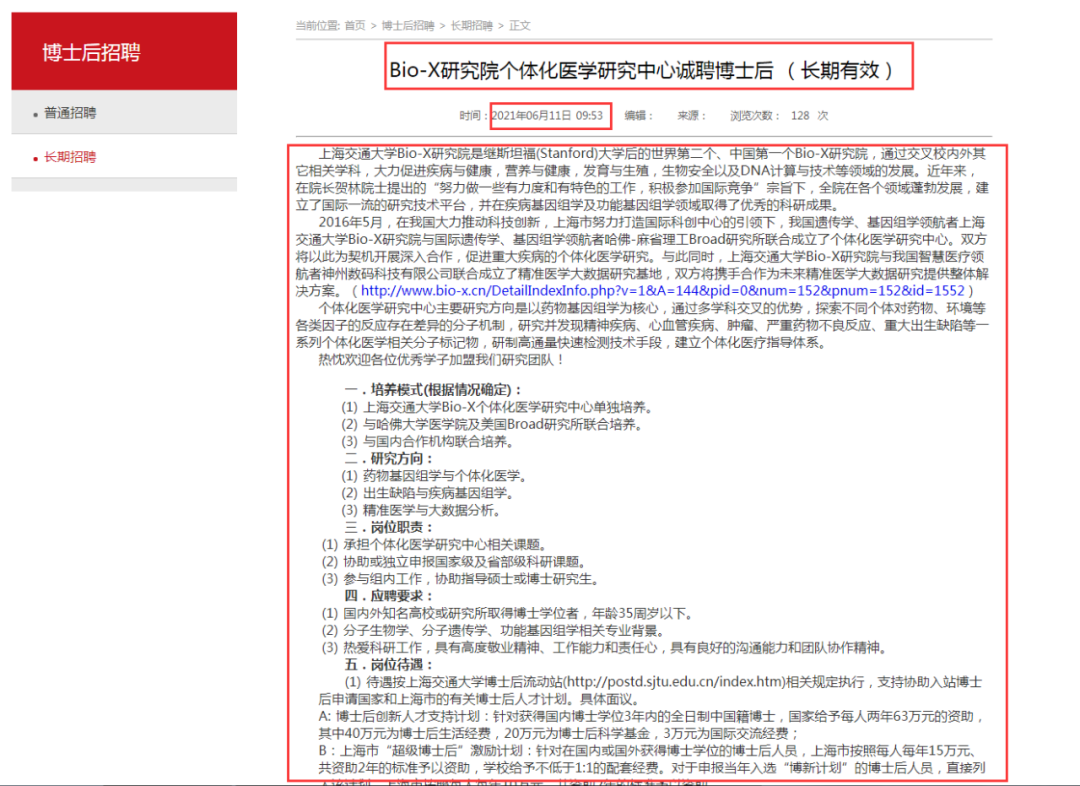
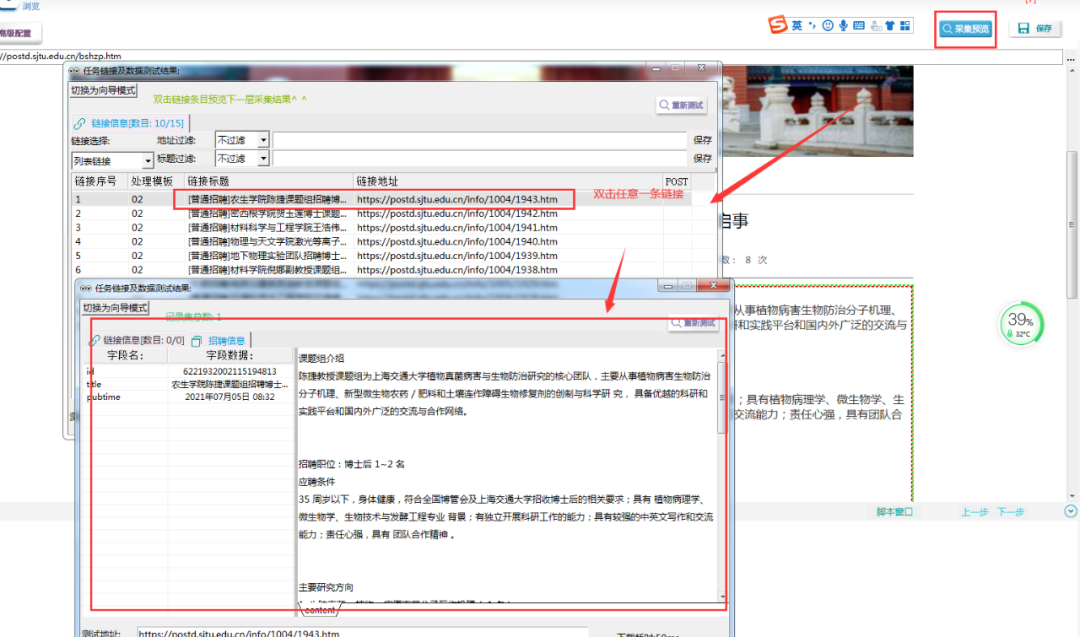
采集预览,右击任意一条链接,复制该招聘链接。
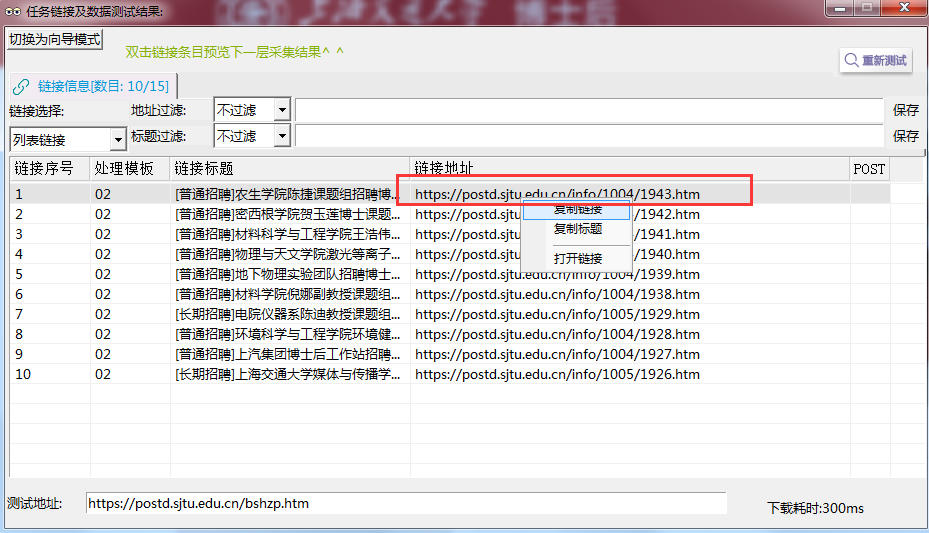
将该链接填写在模板02的示例地址中,并点击右上角保存按钮。如下图所示:
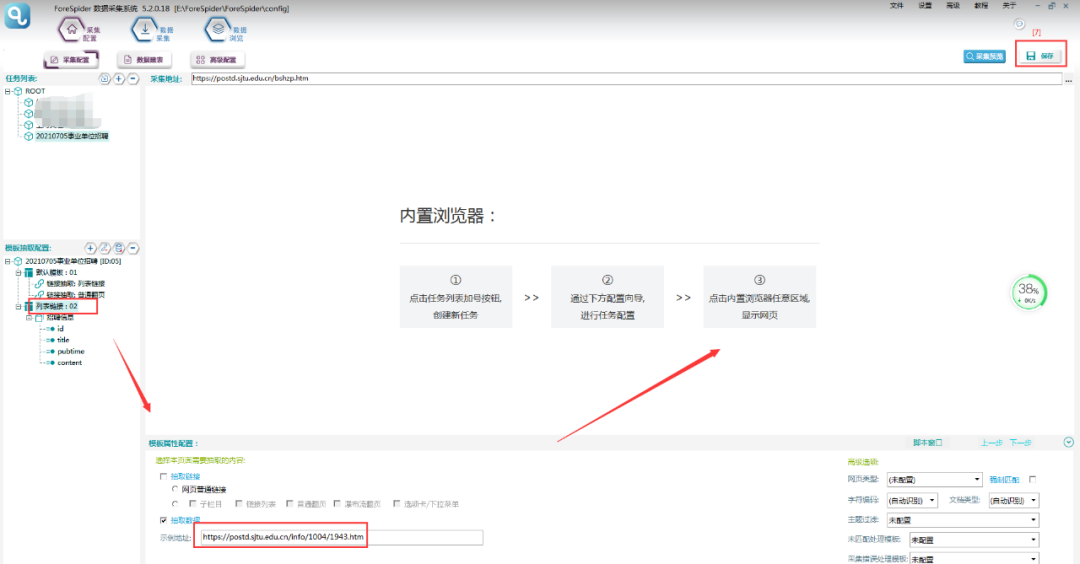
⑤抽取字段数据
双击内置浏览器空白处,这时内置浏览器显示为刚才示例地址页面,使用定位过滤的方法配置每一个字段。
title字段:选中title字段,shift+点击页面中标题,ctrl+鼠标单击扩大选中区域,选中标题后,点击【确认选区】按钮,点击【保存】按钮。

pubtime字段:操作步骤类似,但是由于选中的为【时间:2021年07月05日】,所以使用数据清洗功能,清洗掉【时间:】,具体设置如下图所示:
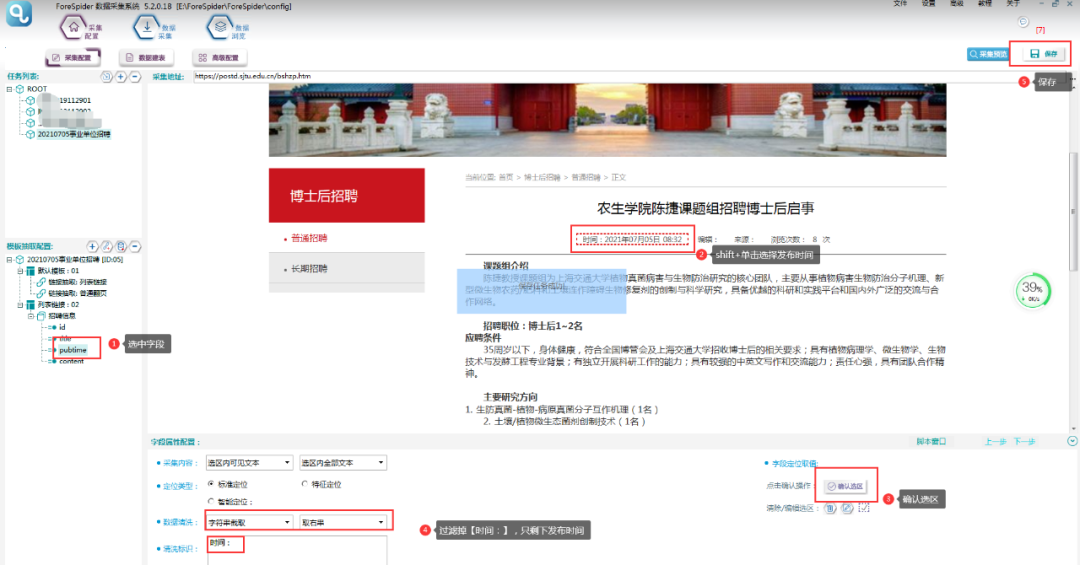
content字段:操作步骤类似,具体如下图所示:
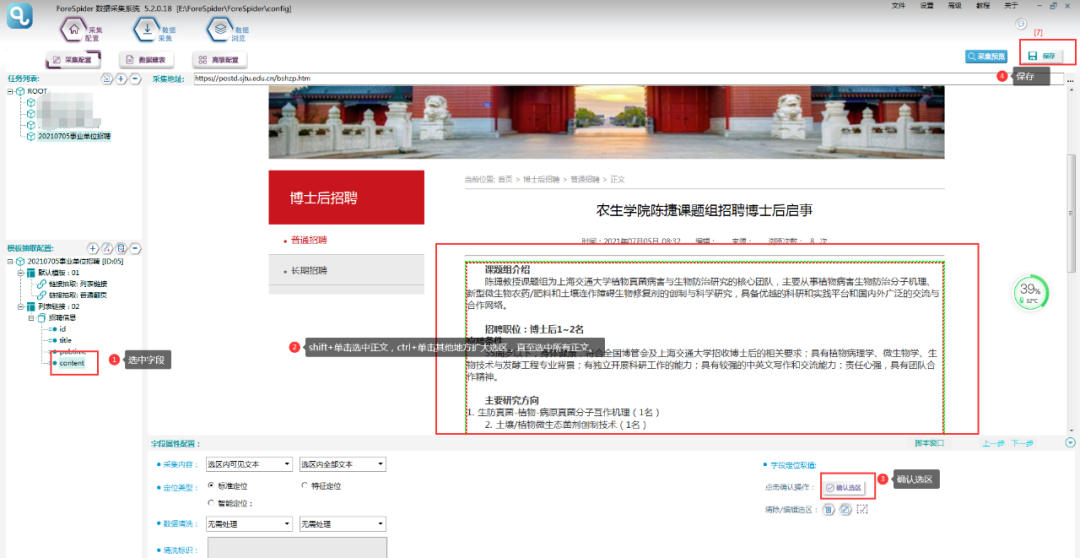
⑥以上完成全部字段配置,效果预览如下:
6.数据采集
模板配置完成,采集预览没有问题后,可以进行数据采集。
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为zhaopin(注意命名不能用数字和特殊符号),点击【确定】。
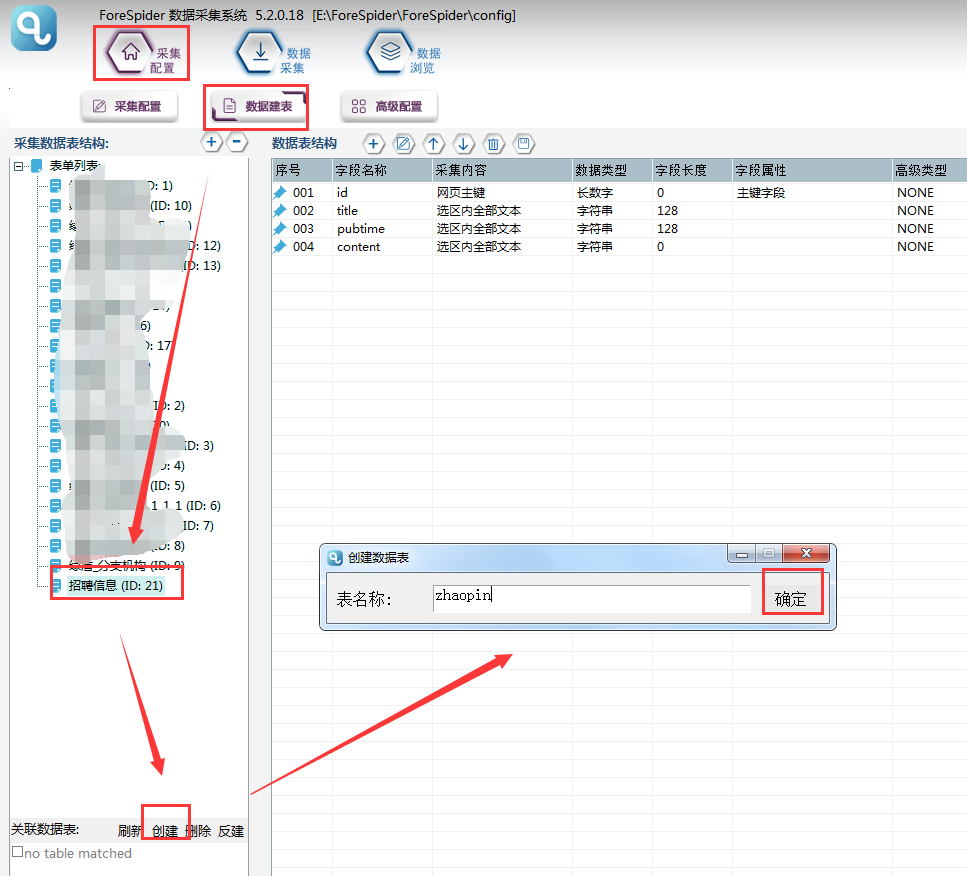
创建完成,勾选数据表,点击保存。
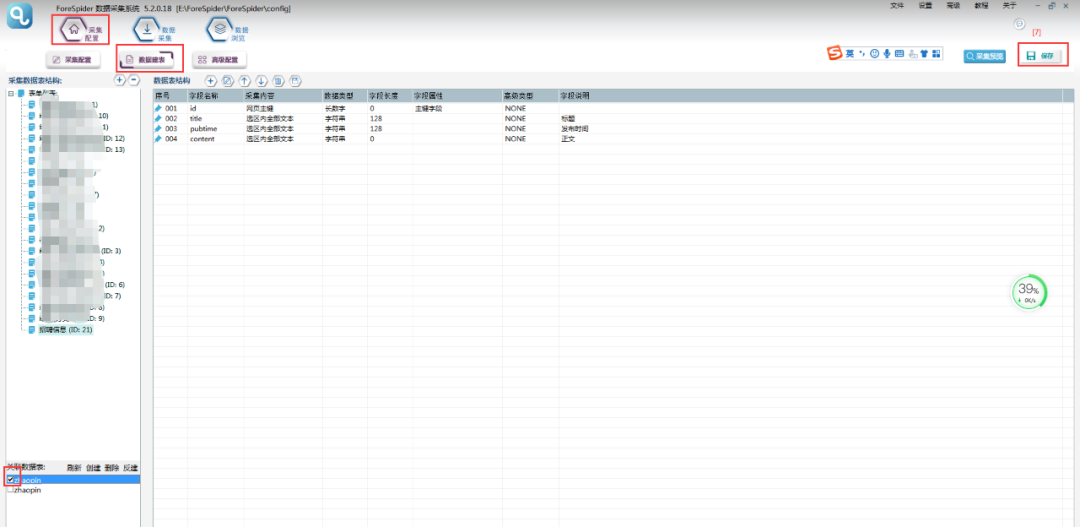
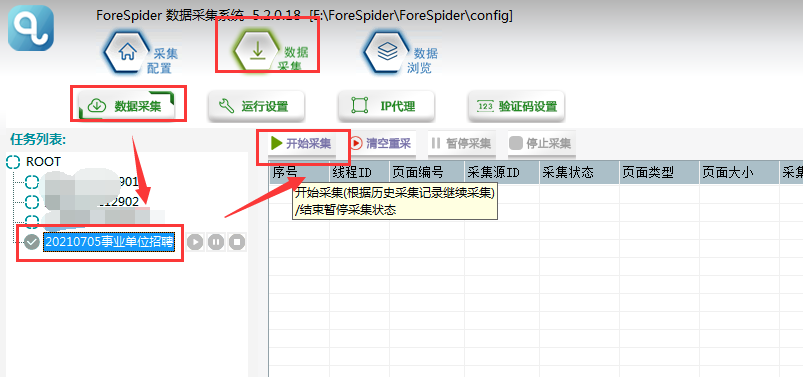
②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
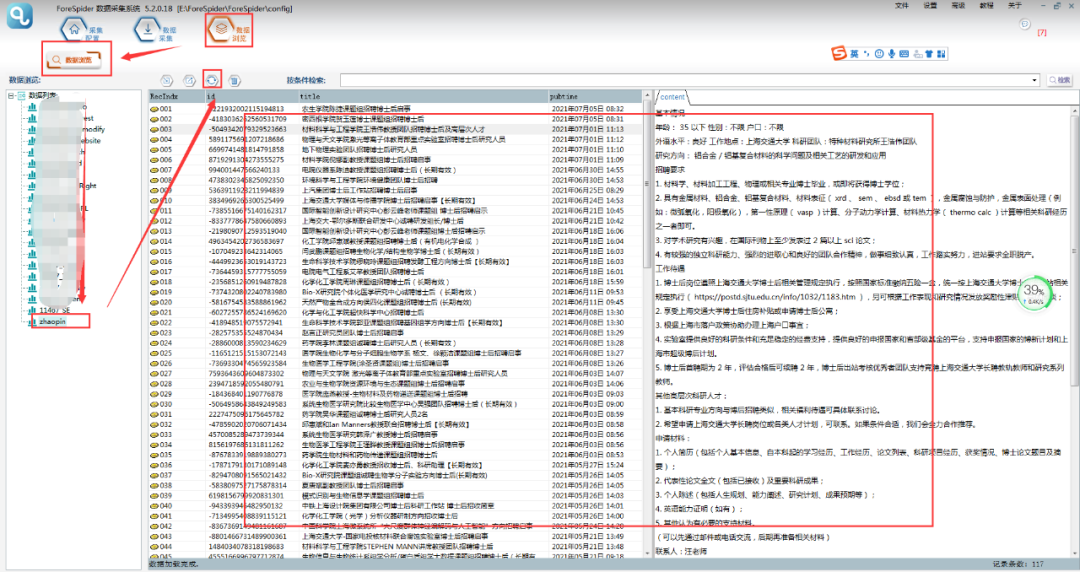
③可以在【数据浏览】中,选择数据表查看采集数据。
④导出数据
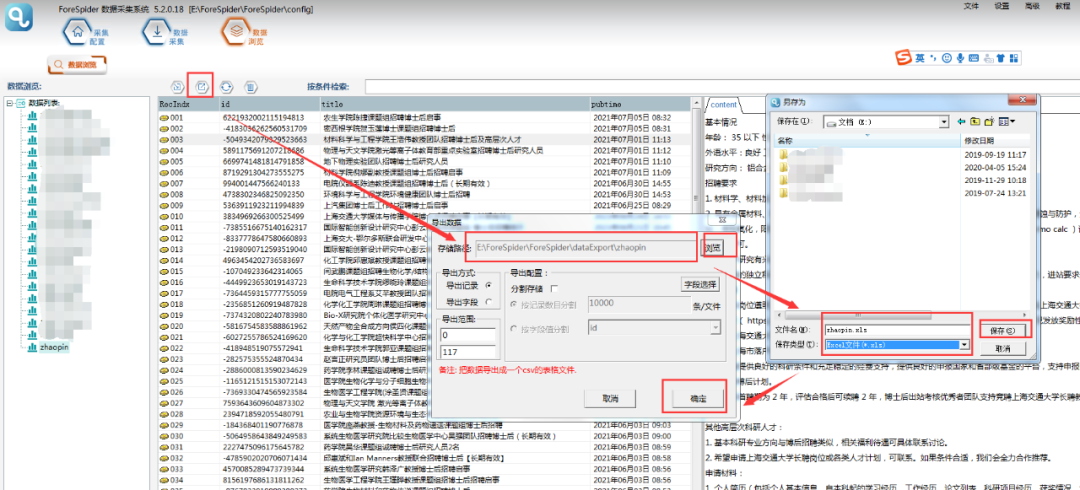
导出数据表如下图所示: