置顶 “前嗅大数据”
和数据大牛一起成长,做牛气哄哄的大数据人

【场景描述】采集带有翻页的网页中的数据。
【使用工具】前嗅ForeSpider数据采集系统,免费下载:

ForeSpider免费版本下载地址
【教程说明】
采集带有翻页的网站,需要先获取所有的翻页链接,常见的翻页链接有三种:数字翻页、点击加载更多/下一页、瀑布流翻页。接下来将为大家介绍不同翻页的配置方法。
1. 数字翻页
下图所示为一个典型的数字翻页:
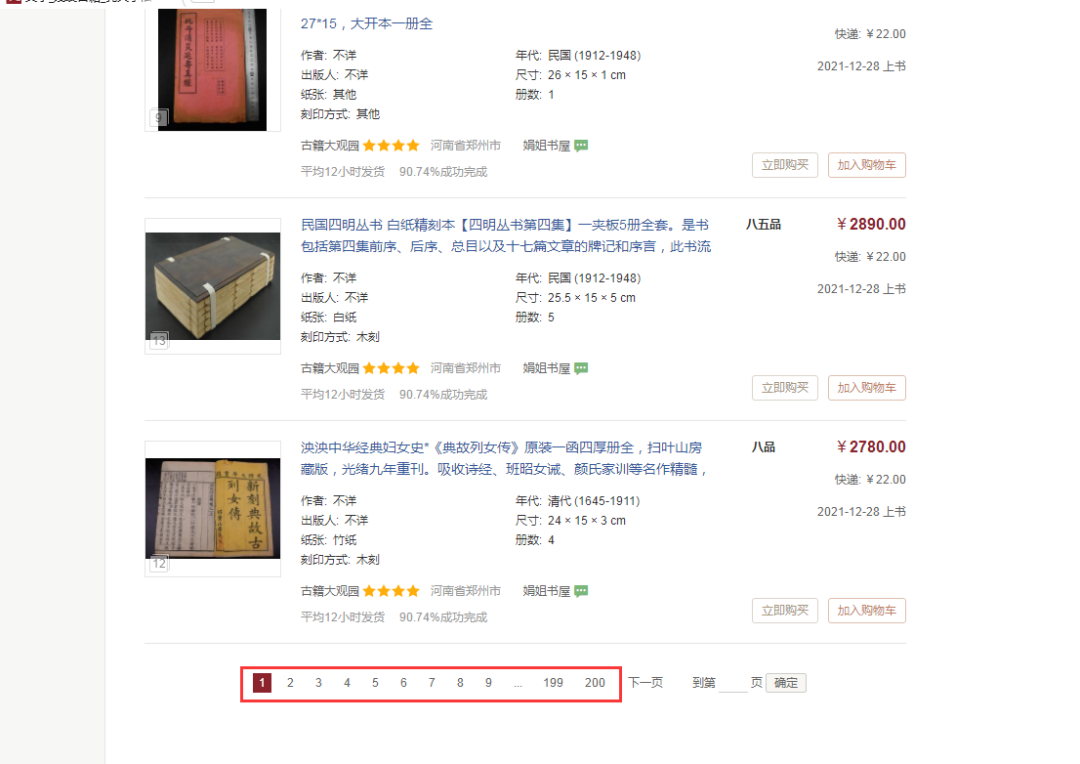
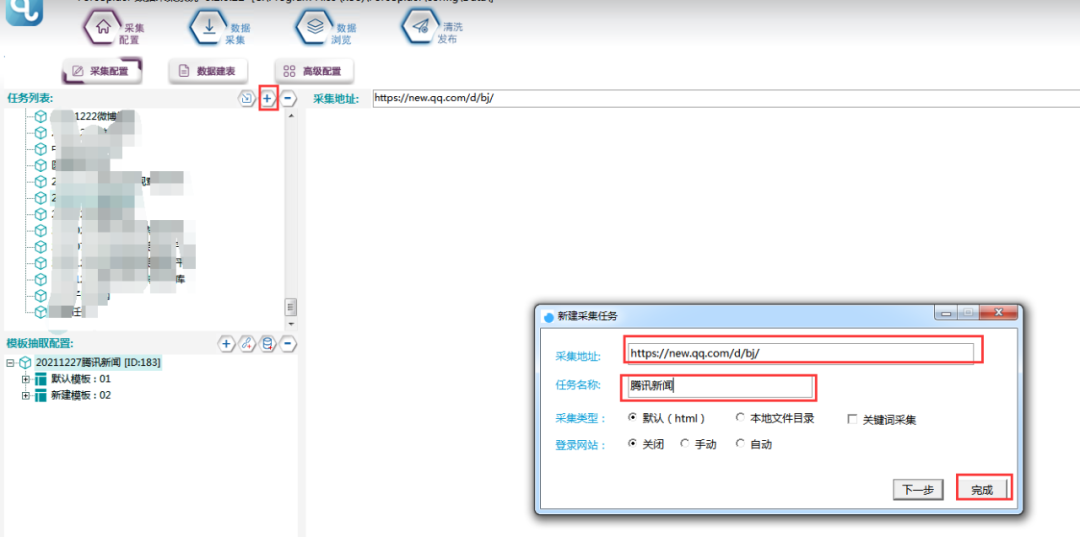
开始配置前,先新建一个任务模板:
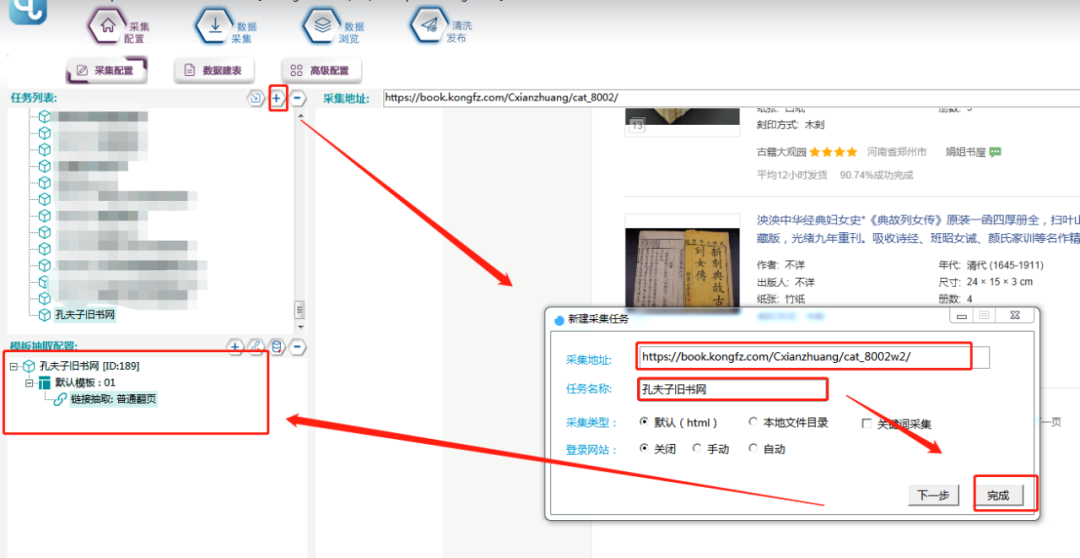
抽取翻页链接方法有三种:
①智能过滤法:
打开前几个翻页链接,观察链接规律,
第二页:文学_线装古籍_孔夫子旧书网
第三页:文学_线装古籍_孔夫子旧书网
第四页:文学_线装古籍_孔夫子旧书网
打开智能过滤界面:
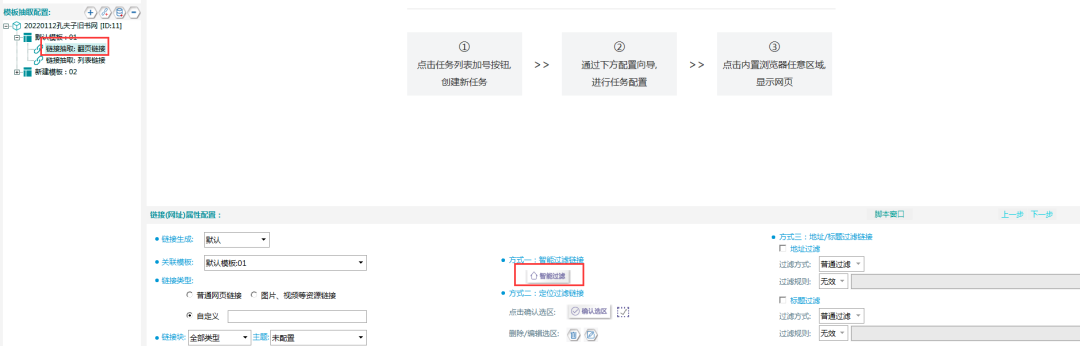
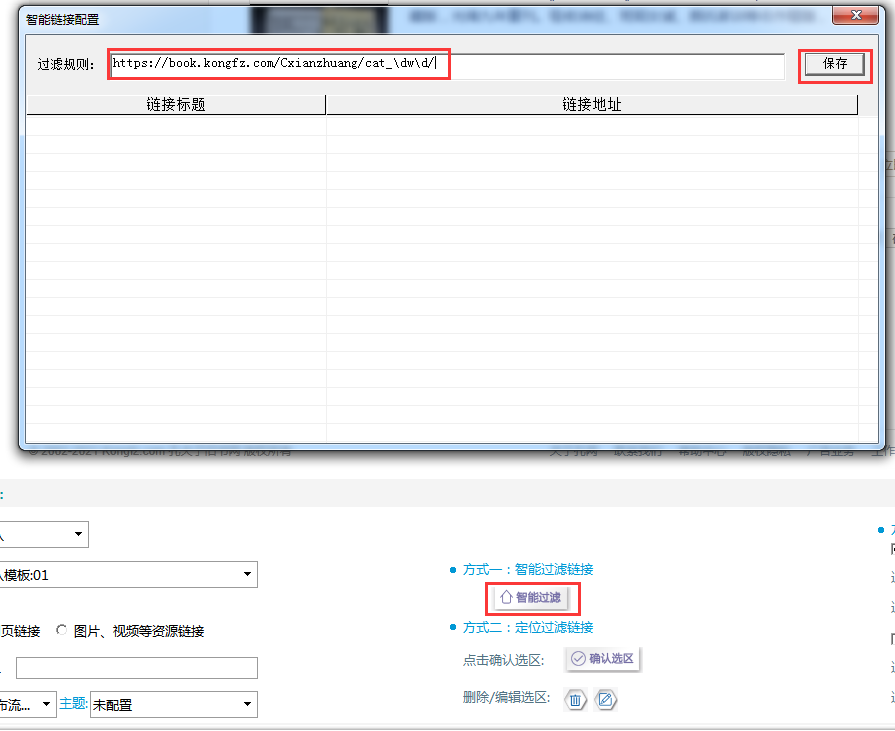
根据规律输入过滤规则:https://book.kongfz.com/Cxianzhuang/cat_\dw\d/
(其中\d表示数字串)
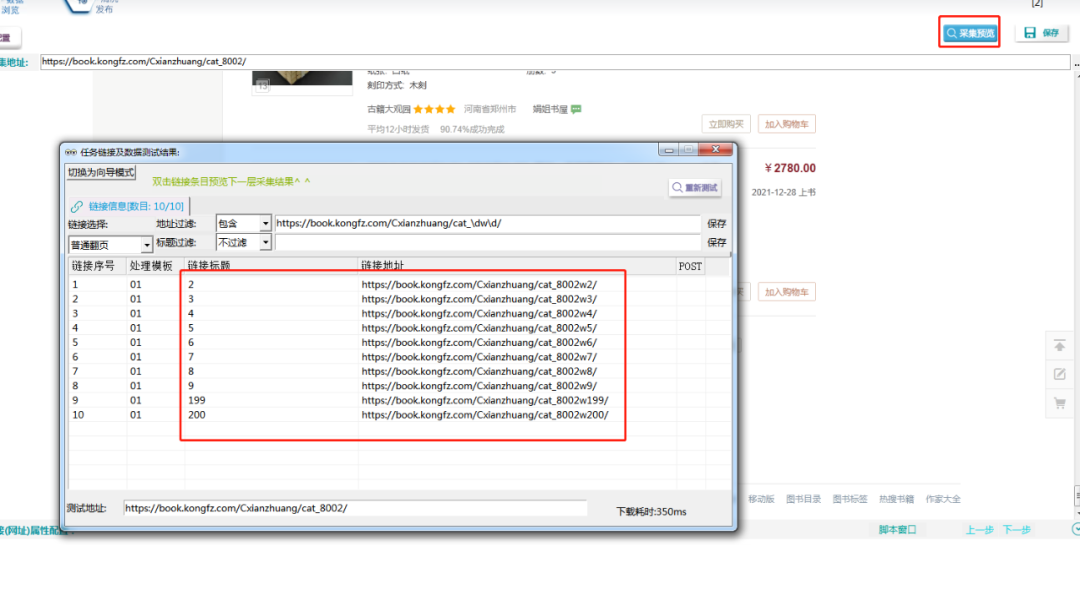
配置后,点击采集预览,发现翻页链接已经都采集到了。
②定位取值法
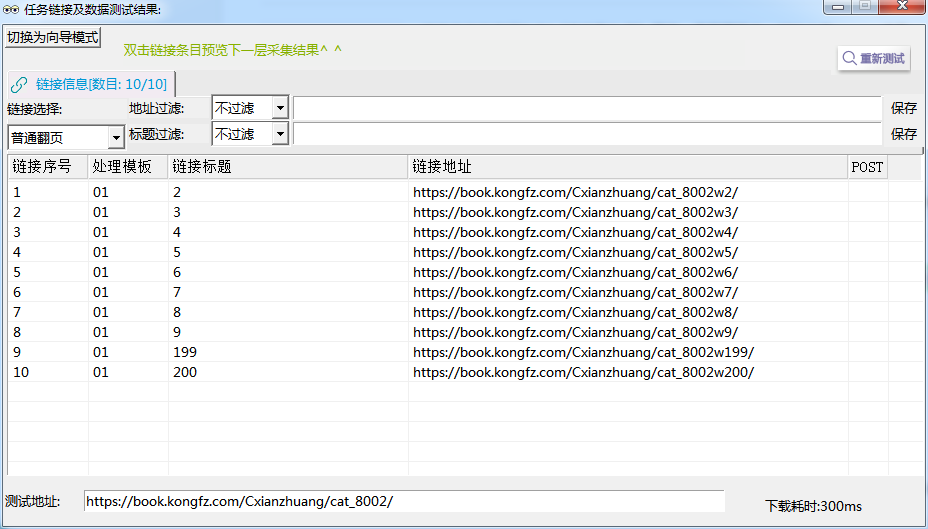
按住ctrl+鼠标单击任意一个翻页,然后按住shift+鼠标单击任意一个未选中翻页扩大选区,直至选中所有翻页,然后确认选区后保存。

采集预览,发现所有翻页都被抽取出来了。
③地址/标题过滤
类似智能过滤,先观察翻页链接规律(步骤可参考方法一),找到规律后,使用地址过滤的方法进行过滤保存,如下图所示,标题过滤跟地址过滤类似,是对标题内容进行过滤。

点击查看完整教程:采集孔夫子旧书网
2. 点击加载更多/下一页
示例地址:http://mbook.kongfz.com/Ckexue/
下图所示为一个典型的下一页:
①智能过滤
观察下一页链接规律,如下所示:
下一页1:自然科学_古旧书籍及收藏品交易_孔夫子旧书网
下一页2:http://mbook.kongfz.com/Ckexue/w3/
下一页3:http://mbook.kongfz.com/Ckexue/w4/
进行智能过滤,步骤参考数字翻页智能过滤。
②定位过滤
步骤参考数字翻页定位过滤。
③地址/标题过滤
一般用标题过滤多一些,如下图所示:
3. 瀑布流翻页
示例地址:https://new.qq.com/d/bj/
瀑布流翻页是用鼠标往下翻,一直能出来新的数据的翻页。比如腾讯新闻,如下图所示:

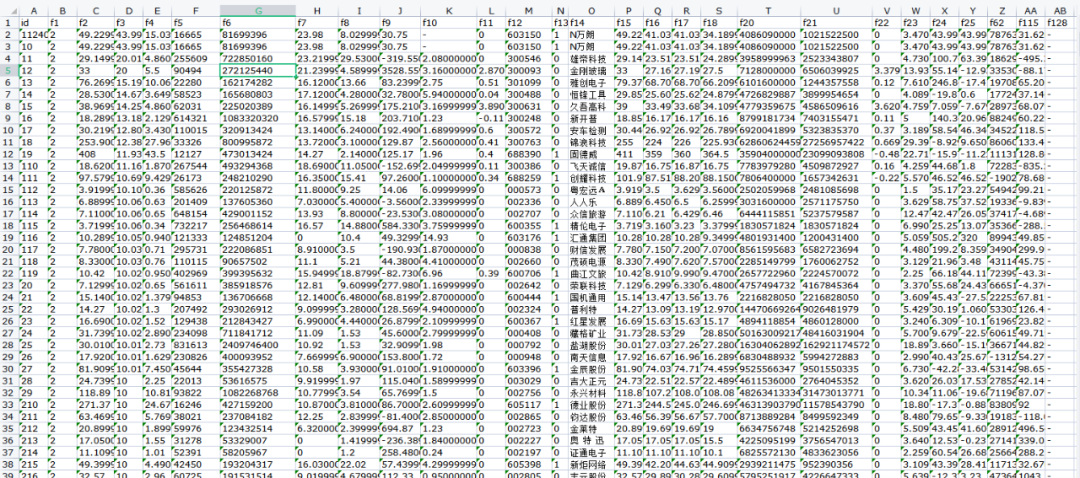
此类翻页的翻页链接在页面请求中,需要先找到请求链接,然后用脚本拼出链接。具体操作步骤如下所示:
在浏览器中打开页面后,点击F12,清空所有请求后,刷新页面。
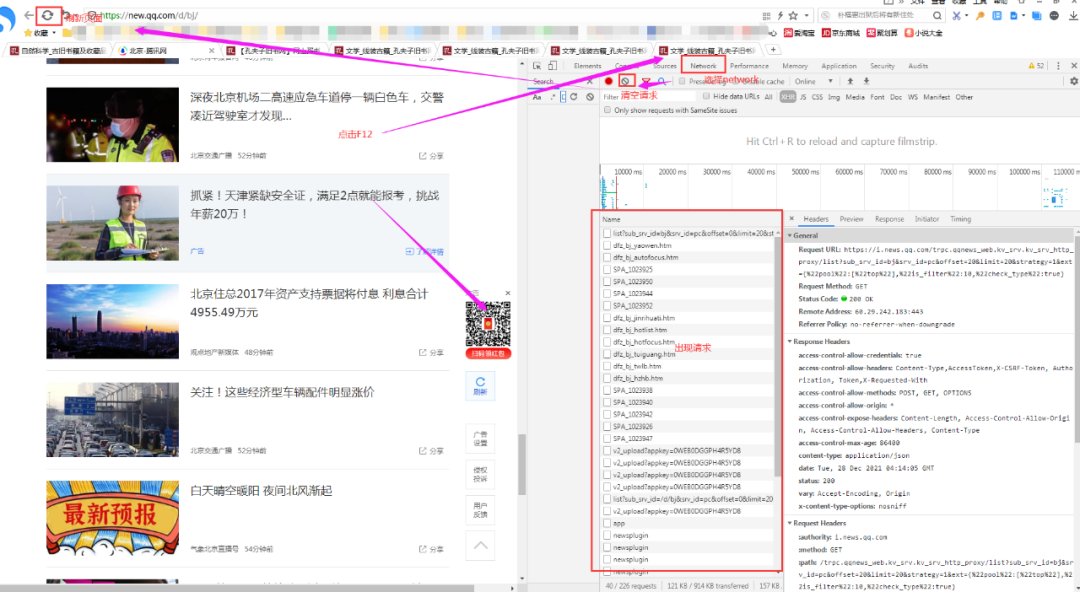
鼠标往下浏览新闻,会发现出现很多新闻,右侧也出现很多请求。观察请求,找出翻页请求链接。
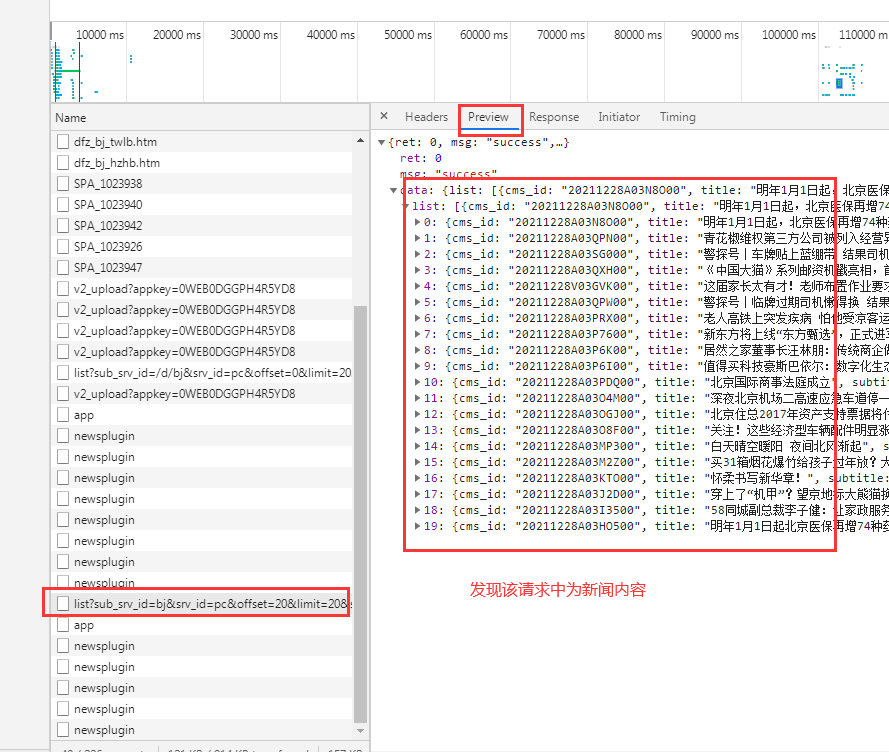

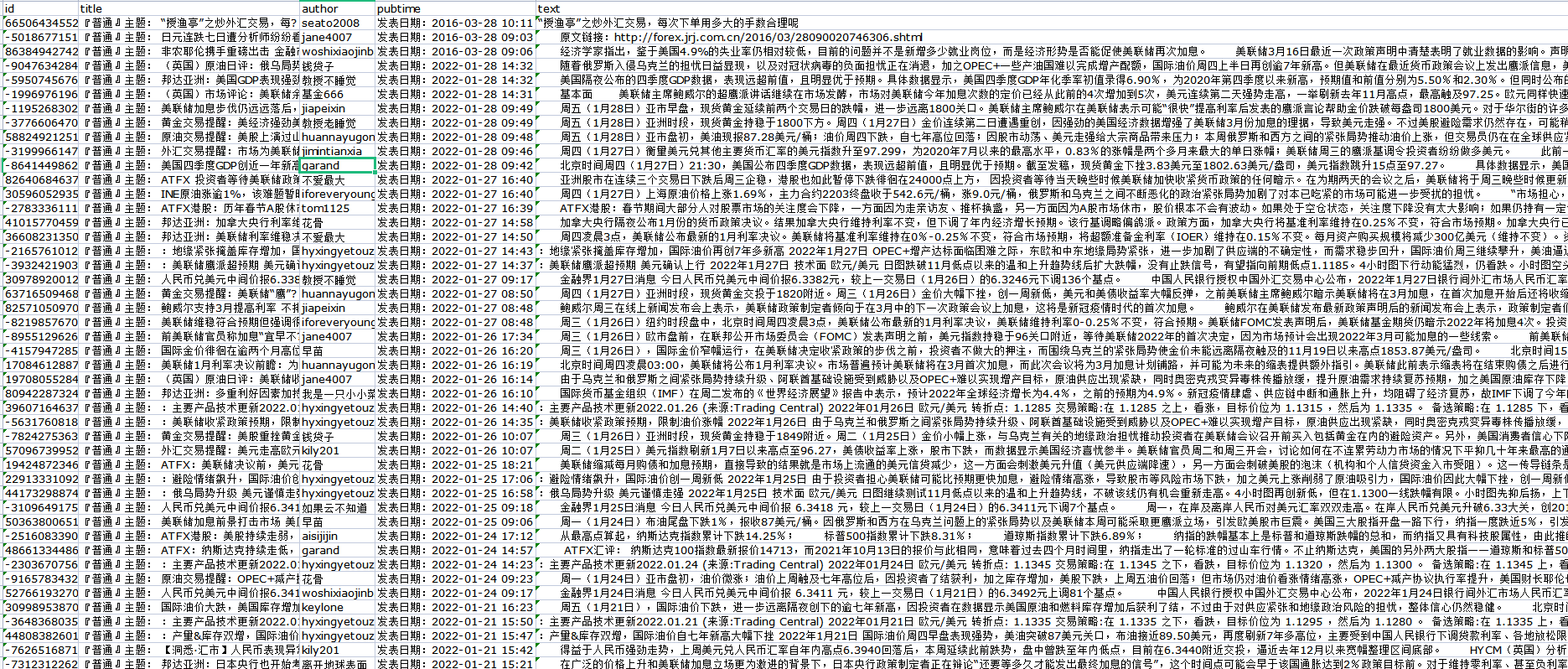
将多个请求链接复制出来,观察链接规律:
https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=bj&srv_id=pc&offset=20&limit=20&strategy=1&ext={%22pool%22:[%22top%22],%22is_filter%22:10,%22check_type%22:true}
https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=bj&srv_id=pc&offset=40&limit=20&strategy=1&ext={%22pool%22:[%22top%22],%22is_filter%22:10,%22check_type%22:true}
https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=bj&srv_id=pc&offset=60&limit=20&strategy=1&ext={%22pool%22:[%22top%22],%22is_filter%22:10,%22check_type%22:true}
观察发现请求链接中只有一个参数不同,分别为20、40、60,该参数规律为:翻页数*20,根据这一规律,使用脚本拼写翻页链接。
首先新建一个任务模板:选中链接抽取后,打开脚本窗口:

写一个for循环来拼取翻页链接:
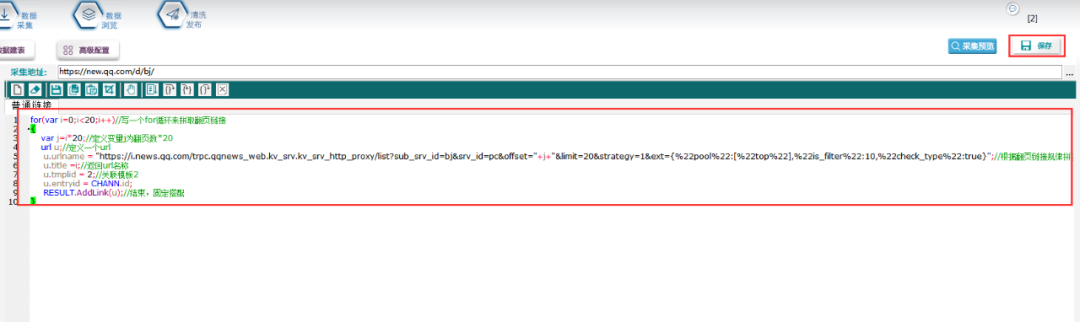
只要是用脚本拼写链接的,都需要用到这个。
脚本写完以后,点击保存,然后点击采集预览,即可看到拼好的链接。

点击查看完整教程:采集腾讯新闻数据
本教程仅供教学使用,严禁用于商业用途!
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于为大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!