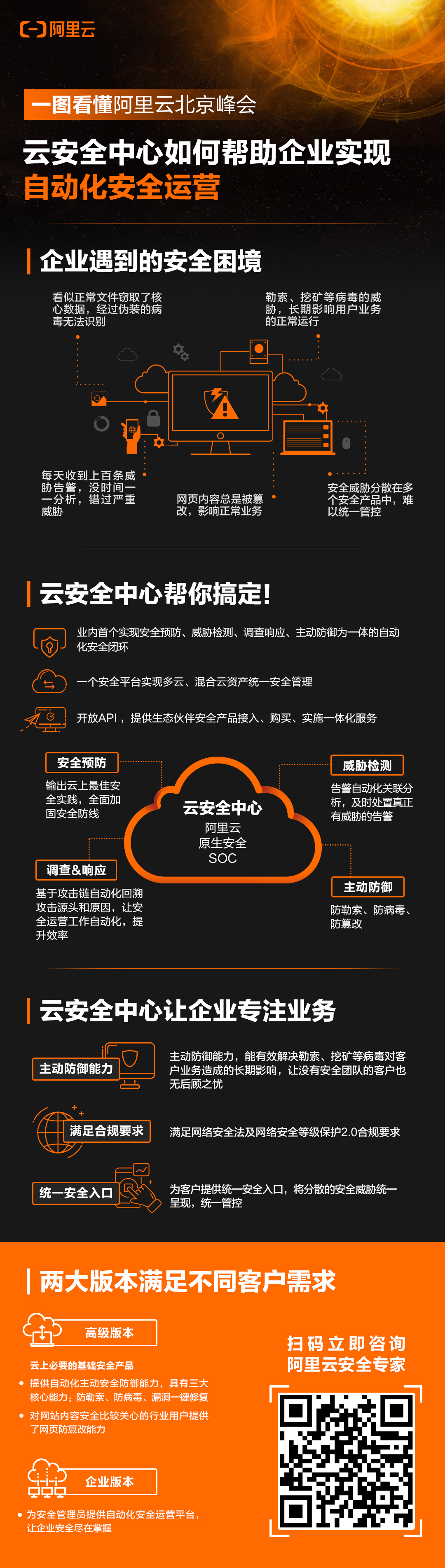
数据采集一般可分为两种:集中式数据采集和分布式数据采集。
我们通常所说的采集某个或某些平台上的数据一般属于集中式采集,指的是一个爬虫采集一个或多个网站的情况。
那么什么是分布式集群采集呢?
在此之前我们先来了解什么是分布式。
举个例子:
你开发一个网站想要别人访问,这就需要把网站部署到服务器上,如下图所示:
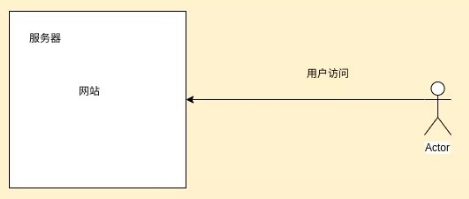
当网站用户增多的时候,原来部署的服务器就不满足需求了。这时就需要把网站部署到各个服务器上,如下图所示:
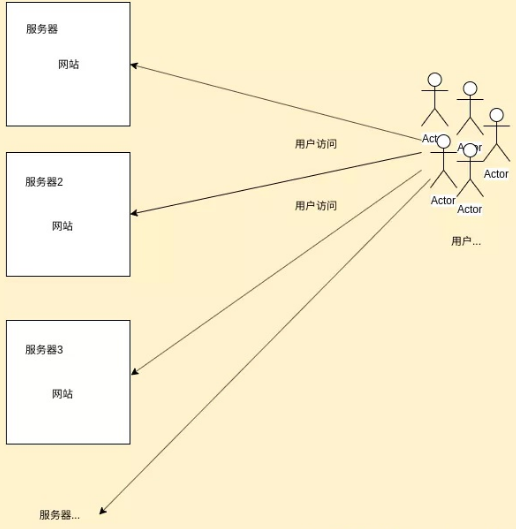
这种情况我们称之为:集群,即把整个网站的所有功能,都部署到不同的服务器上去。
由于有些功能并发量并不高(如后台管理等功能),所以我们就把这个网站的不同功能筛分出来,让每个模块只负责具体的某一个或多个功能,比如登录模块、内容管理模块等。
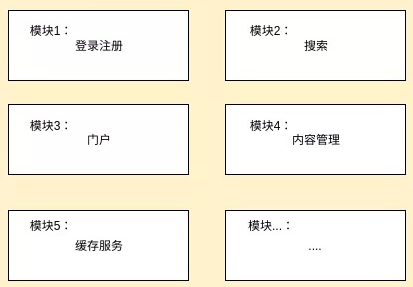
然后将并发量大的模块部署到各个服务器上,从而更好地降低耦合度,并发量小的模块也不会形成资源浪费。
不过这需要让模块与模块之间产生联系,调度好各功能,如下图所示:
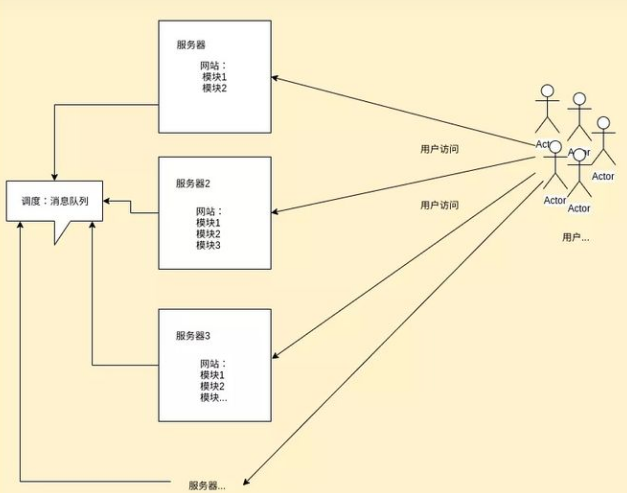
这就是分布式啦~
分布式集群采集,简单来说就是以我们刚才说的分布式形式,分别部署到多个服务器上,一起或分别去采集一个或多个网站的数据。
ForeSpider数据采集分析引擎,针对采集领域独创分布式算法,由调度服务器统一进行操作管理,采集服务器可以横向无限扩展,采集算法与采集策略自动同步,采集过程中可并行调度采集,可以为企业提供任何场景的分布式部署方案。
针对采集领域独创分布式算法,由调度服务器统一进行操作管理,采集服务器可以横向无限扩展,采集算法和采集策略自动同步,支持多台采集服务器同时启停和对某台采集服务器单独启停。
不同的采集场景,会有不同的分布式采集策略,不过不论使用分布式采集的部门如何繁多、采集的网站如何量大,常见的分布式场景无非以下三种:
1.分布采集统一存储
多个服务器分开采集数据,将数据统一存储到总服务器中。
2.分布采集分布存储
多个服务器分开采集数据,分开存储到各自服务器中。
3.分布采集分布存储交叉调用
多个服务器分开采集数据,分开存储到各自服务器中,各服务器可调用指定服务器中的数据。
那么这些分布式场景一般运用在哪些采集案例中呢?
我们经常遇到的分布式集群采集有以下几种情况:
1.企业多部门协调采集
当企业多部门同时使用采集系统协调采集一个或多个网站数据时,需要根据部门结构分布式部署,实现协调采集。
2.采集海量数据
需要采集的网站上数据量非常大,并想快速获取时,需要分布式部署,加快采集速度。
3.采集海量网站
需要快速采集千万个网站上的数据时,可以分布式集群采集,提高采集效率。
对于这些常见的分布式集群采集场景,前嗅不断的进行研发更新,现在ForeSpider数据采集分析系统可在多台机器上部署同一个任务,降低单机内存压力,提升采集效率。
软件内置分布式引擎,可以快速进行分布式集群,具备支持大规模IT系统的能力,并行情况下可支撑百亿以上规模数据链接,堪与百度等搜索引擎系统媲美。
ForeSpider数据采集引擎主要通过下列技术,不断优化采集效率,使得爬虫软件的爬取效率达到最佳。
1.分布式部署+多线程+采集策略最大限度提高采集效率。
2.针对重点关注的目标单独分配资源和策略。
3.代理池预检测机制,确保使用速度最快的代理。
4.异常及时预警,减少错误发现周期。
5.有效防重算法,避免重复访问网页。
所以ForeSpider服务器集群采集能力可达 8 亿-16 亿,即每天能发送8亿—16亿采集请求,获取8-16亿采集链接。
在面对各种复杂或海量的大数据集群采集项目时,ForeSpider可以毫无压力的灵活部署,用最低的成本为客户提供强有力的数据支持。
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于为大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!