爬虫学习
- 3.
爬虫深度优先和广度优先">爬虫深度优先和广度优先

爬取网页会存在环路的情况:比如导航栏

通过URL去重,跳过已经爬取的URL
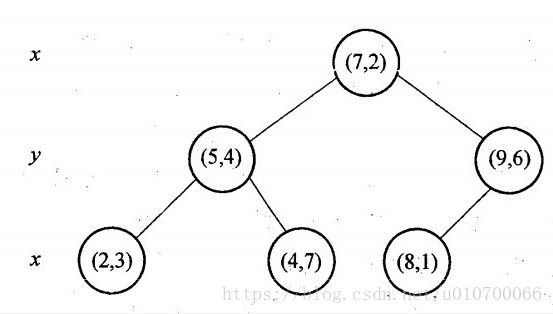
深度优先
按照垂直进行(scrapy是用这个方法)

深度优先算法:
def depth_tree(tree_node):
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left)
if tree_node._right is not None:
return depth_tree(tree_node._right)i
广度优先
按照层次进行访问

广度优先算法:
# 广度优先算法
def level_queue(root):
# 利用队列实现树的广度优先遍历
if root is None:
return
my_queue = []
node = root
my_queue.append(node)
while my_queue:
node=my_queue.pop(0)
print(node.elem)
if node.lchild is not None:
my_queue.append(node.lchild)
if node.rchild is not None:
my_queue.append(node.rchild)爬虫去重策略">爬虫去重策略
- 将访问过的URL保存经过md5方法哈希后到set中
- 用
bitmap方法,将访问过的URL通过hash函数映射到某一位,用0,1表示有没有存储数据,用地址表示URL映射
| bit | bit | bit | bit | bit | bit | bit | bit |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
1. bloomfilter方法对bitmap进行改进,多重hash函数降低冲突
通过伯乐在线
1. 伯乐在线的文章结构:
2. 文章首页,每一页,下一页
调试方法:直接通过scrapy命令进行调试

调试命令在这个里面:


![算法图解[Aditya Bhargava]--读书笔记](https://img-blog.csdn.net/2018070417310679?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTA3MDAwNjY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)