import time
import json
import requests
import xlrd
import random
import os
from xlutils.copy import copy #导入模块
excel = r'C:\Users\Administrator\Desktop\查排名.xls'
try:
rdx = xlrd.open_workbook(excel, formatting_info=True) #打开Excel,并保留原格式
except:
print( "no excel in %s " % excel )
newb = copy(rdx) #复制一份做输出
#sh = rdx.sheet_by_index(name)
print('\033[31;1m已录入型号 :\033[0m',(rdx.sheet_names())) #所有sheets.name
#sh=rdx.sheet_names()
for sheet_n in rdx.sheet_names(): #循环整个工作簿
sh1=rdx.sheet_by_name(sheet_n) #工作表对象
w_sheet=newb.get_sheet(sheet_n) #获取sheet名称查
id=str(int(sh1.cell_value(0,1))) #int浮点转整数 str转字符串
print('id' ,sh1.cell_value(0,1), id ,type(id))
print('\033[31;1m查询型号 :\033[0m'+ sheet_n)
tplt = "{:3}\t{:23}" #这里控制输出 行数
for i in range(sh1.nrows): #非空行行数 整个型号的词循环
i1=str(sh1.cell_value(i, 0))
if i1=="": #空行退出
break
time.sleep(random.uniform(1.5,3.6)) #随机浮点数
url='https://s.m.taobao.com/search?q='+i1+'&sst=1&n=20&buying=buyitnow&m=api4h5&token4h5=&abtest=3&wlsort=3&page=name'
#url获取地址
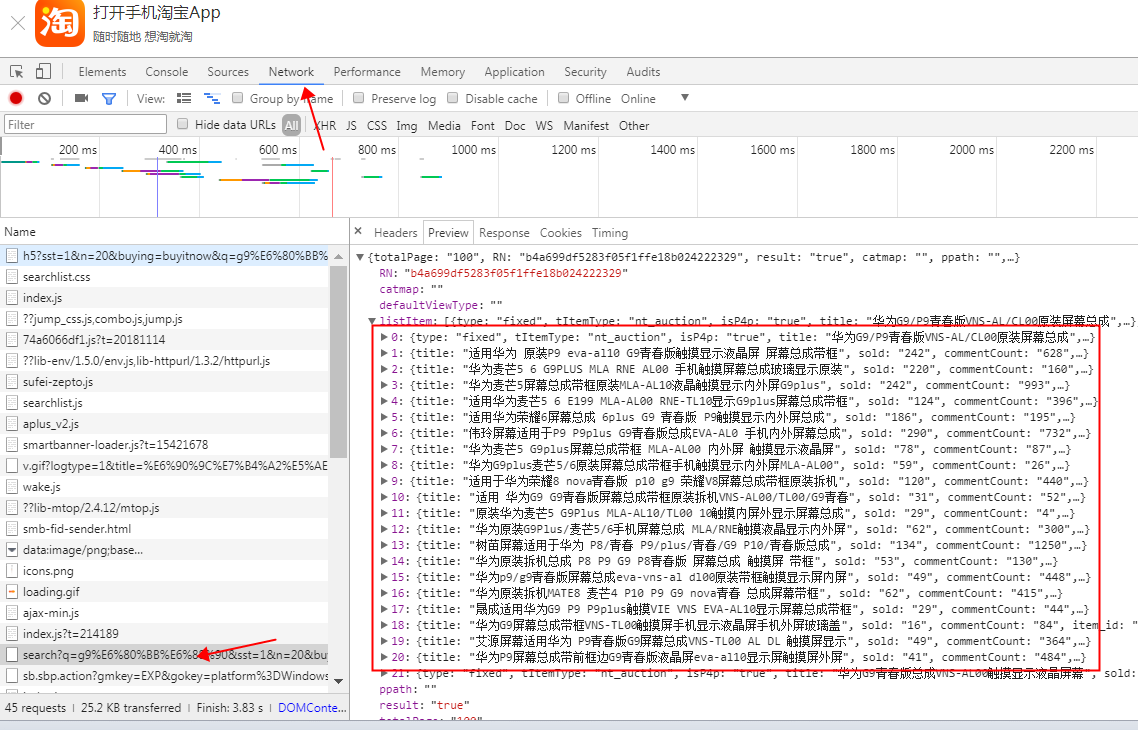
1.淘宝手机端链接地址登录s.m.taobao.com
2.输入查询的关键字 审查元素 这里记得刷新一次
3.network 右侧name 一个个打开 需要的信息就在preview里面
4.恭喜找到自己需要的信息
# url='https://s.m.taobao.com/search?q='+i1+'&sst=2&n=40&buying=buyitnow&m=api4h5&abtest=22&wlsort=22&page=name'
#这里是找到目标真正的地址
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.name; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
comments = requests.get(url,headers=headers)
#这里有问题临时处理办法
try:
js = json.loads(comments.text)
except json.decoder.JSONDecodeError:
continue
count=0
for j in js['listItem']: #所有店铺信息
count+=1
if j['item_id']==id: #如果id相同
print('j]',j['item_id']==id)
w_sheet.write(i,2,count)
break
else :
# print(tplt.format('没找到',i1))
w_sheet.write(i,2,'没找到')
w_sheet.write(i+1,2,time.strftime('%m-%d ',time.gmtime()))
print(" 任务完成!")
os.remove(r'C:\Users\Administrator\Desktop\查排名.xls')
newb.save(r'C:\Users\Administrator\Desktop\查排名.xls')
print('\033[32;1m查询完成!\033[0m','\n','warning:以上是查询无线两页45位结果!')
ps:记得Excel 不要有多于空白工作表 不然会报错