一、爬虫对象
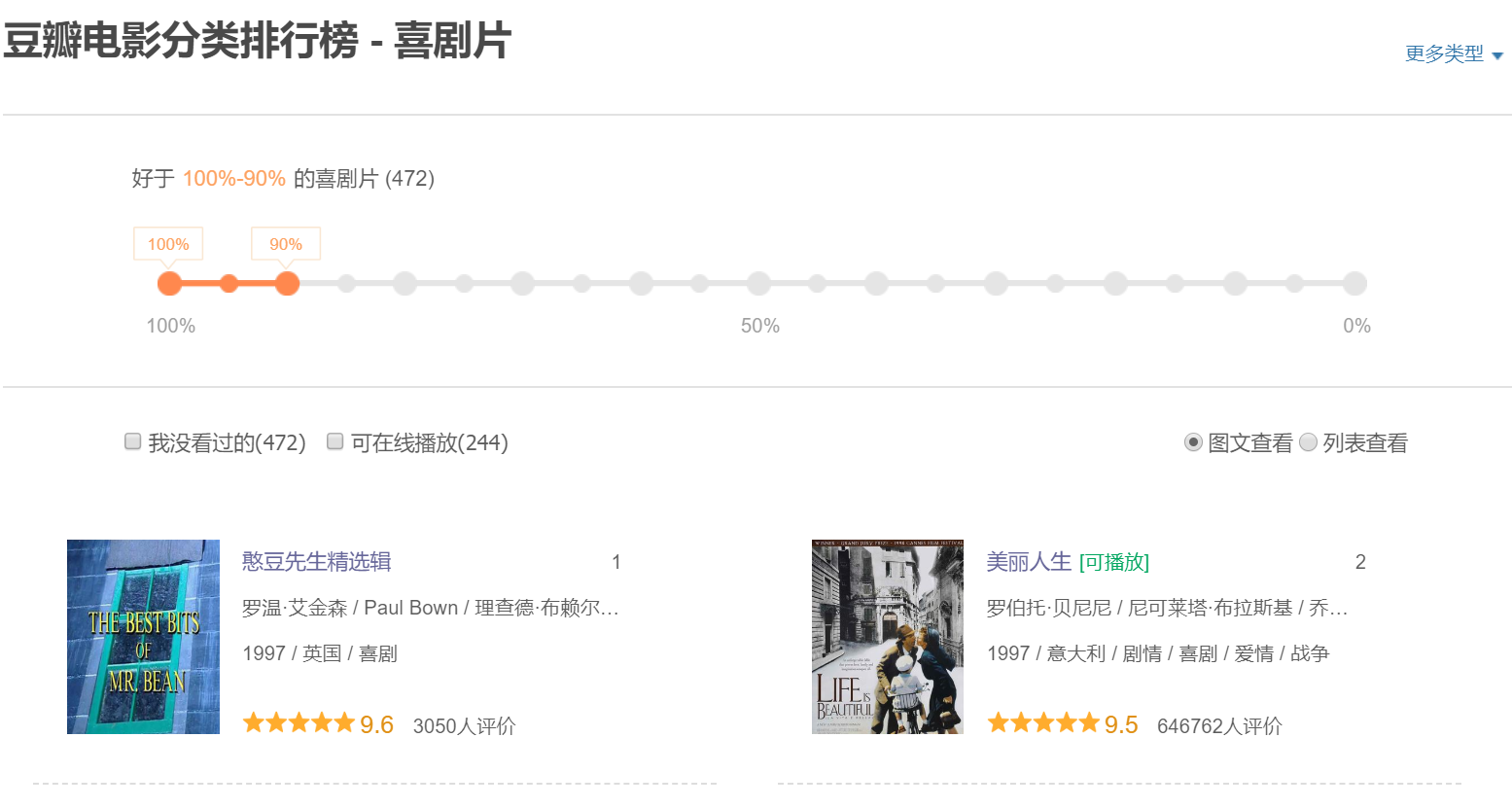
豆瓣电影里面喜剧片的排行榜:
二、代码如下:
设置了多个user-agent,模拟成真实的浏览器去提取内容:

user = ["Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",\
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",\
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",\
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",\
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",\
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",\
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER"]
def get_user():
user_id = random.choice(user)
return user_id
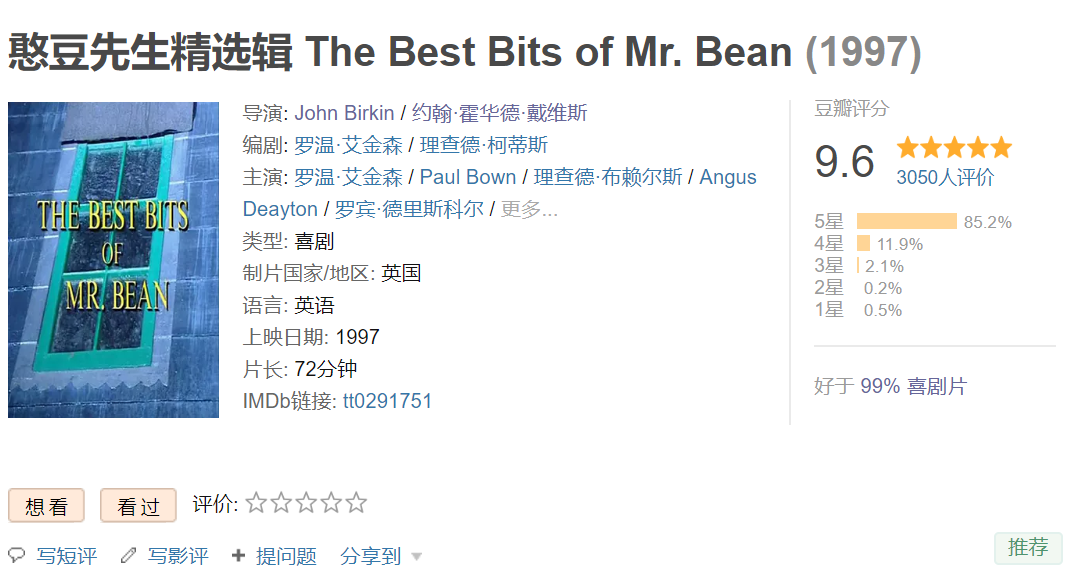
抓取电影的信息:
#获取索引页
def get_index_page(url):
try:
headers = {'user-agent':get_user()}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
print('获取索引页错误')
time.sleep(random.random()*3)
return get_index_page(url)
#解析索引页
def parse_index_page(url):
data_list = get_index_page(url)
dataUrl = json.loads(data_list)
detail_list = []
if dataUrl:
for item in dataUrl:
detail_list.append(item['url'])
return detail_list
#获取详情页
def get_movie_page(url):
detailUrl = parse_index_page(url)
movie = []
for i in range(len(detailUrl)):
html = detailUrl[i]
headers = {'user-agent':get_user()}
time.sleep(random.random()*3)
res = requests.get(url=html,headers=headers)
res.encoding = 'utf-8'
soup=BeautifulSoup(res.text,"html.parser")
movie_dict = {}
movie_dict['name'] = soup.find("span", {"property": "v:itemreviewed"}).text
movie_dict['evaluate'] = soup.find("span", {"property": "v:votes"}).text.strip( '' )
movie_dict['score'] = soup.find("strong", {"property": "v:average"}).text.strip()
movie_dict['director'] = soup.find("a", {"rel": "v:directedBy"}).text
movie_dict['region'] = soup.find("span", text="制片国家/地区:").nextSibling.strip()
movie_dict['year'] = soup.find("span", {"class": "year"}).text.lstrip("(").rstrip(")")
movie.append(movie_dict)
return movie
三、把爬的电影数据保存起来
部分截图(一共抓取了600部电影):

四、数据分析
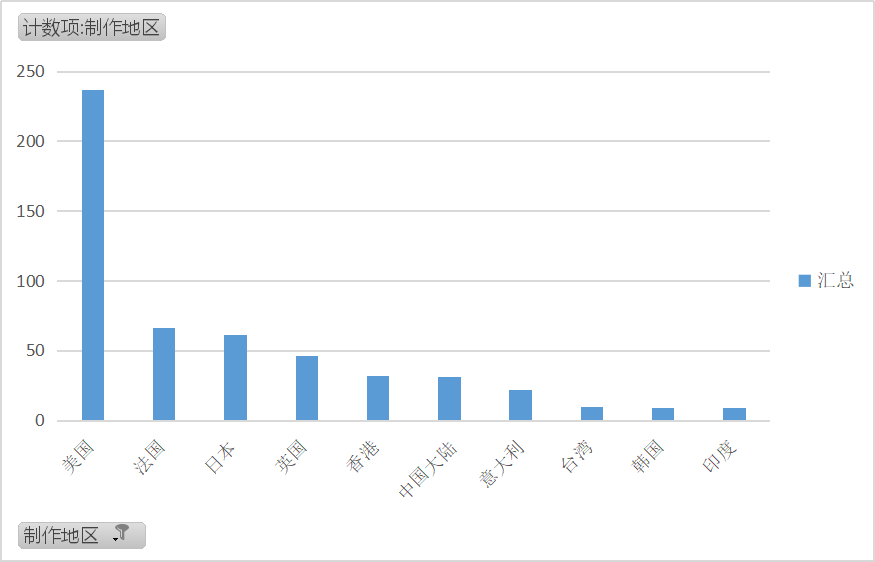
通过此柱形图可以发现美国地区居于首位,毕竟美国发展得比较快,电影事业崛起。

通过对前三个国家的喜剧片分析,近年来美国拍的喜剧片逐步上升,法国和日本就平平而过。
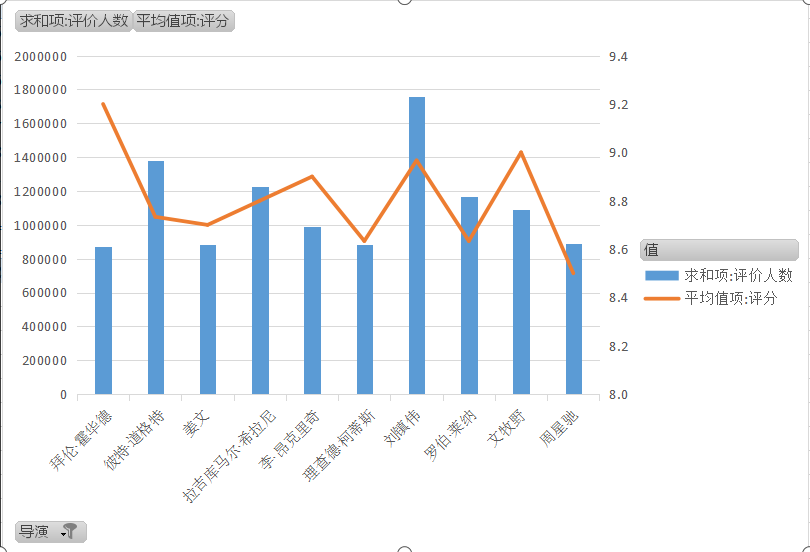
通过分析导演拍喜剧电影的评分和评价数,刘镇伟导演的喜剧电影应该更多人喜欢看,评价又多评分也高,大家若想看喜剧电影的话,不妨找找刘镇伟导演的喜剧电影,仅供大家参考。
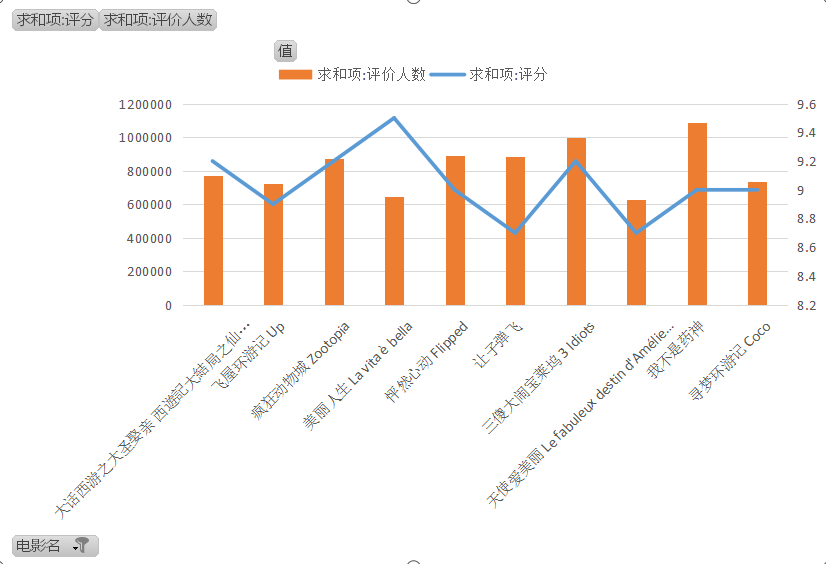
推荐:这几部电影评分比较高,看的人也比较多,喜欢看喜剧电影的不妨找这几部看看。