前言

一本本书,是一扇扇窗,为追求知识的人打开认知世界的窗口
一本本书,是一双双翅膀,让追求理想的人张开翅膀翱翔
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

前面写了一篇文章关于爬虫的系列内容一步一步教大家写一个完整的GUI小说下载神器。
这一期想给大家趴一趴外甥女想买的书籍,因为前几天学校让买课外书籍,这不?
网上的书籍太多了,想让我参考一下,正好今天有时间研究了一下,直接批量下载了一些,看
看那些评论好,对比一下再买!
今天就给大家一步步分析一下是我是如何爬取数据,采集某网站的书籍并做一个数据分析滴~

正文

一、准备环境
1)环境安装
本文用到的环境如下——
Python3、Pycharm社区版,requests、parsel、自带的库只 要安装完 Python就可 以直接使
用了, 需要安装 的库的话看教程下🎐
一般安装:pip install +模块名
镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名
(之前有说过安装报错的几种方式跟解决方法,不会安装的可以去看下,还有很多国内镜像源
也有文章的)二、安装问题
何配置pycharm里面的python解释器?
1. 选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器) 。
2. 点击齿轮, 选择add 。
3. 添加python安装路径 。pycharm如何安装插件?
1. 选择file(文件) >>> setting(设置) >>> Plugins(插件) 。
2. 点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输
入 Chinese 。
3. 选择相应的插件点击 install(安装) 即可 。
4. 安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效。三、数据来源分析
1. 明确需求: - 采集的网站是什么?
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1 - 采集的数据是什么? 书籍相关的数据内容: 名字/价格/评价/推荐/作者....

2. 分析书籍信息在那个数据包
<请求那个url地址>里面 通过开发者工具进行抓包分析 。
- 打开开发者工具: F12 / 鼠标右键点击检查选择network
刷新网页: 让网页数据内容重新加载一遍 <F5/ctrl+R>
搜索功能: 通过关键字<你要的数据>去搜索查询相对应的数据包 。
由上述可得: 请求这个: http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-
recent7-0-0-1-1 就可以得到相应书籍信息。四、代码展示
1)主程序
# 导入数据请求模块 --> 第三方模块 需要安装 pip install requests
import requests # 灰色不是报错, 而是导入模块没有使用
# 导入数据解析模块 --> 第三方模块 需要安装 pip install parsel
import parsel
# 导入csv表格模块 --> 内置模块, 不需要安装
import csv
# 创建文件对象
"""
data.csv <文件名> 代码在哪里就保存在哪里
mode='a' 保存方式, 追加保存
encoding='utf-8' 编码格式
newline='' 换行
f --> 文件对象
fieldnames --> 字段名, 表头
如何批量替换:
1. 选择替换内容 ctrl + R
2. 勾选上 .* <正则>
3. 输入正则命令
:.*
,
"""
f = open('data.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'评论',
'推荐',
'作者',
'时间',
'出版社',
'售价',
'原价',
'折扣',
'电子书',
'详情页',
])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 安装模块
1. win + R 输入cmd 输入安装命令
2. 点击pycharm终端, 输入安装命令
如果觉得安装速度太慢可以换源
- 把python代码伪装成浏览器去发送请求
headers请求头 --> 字典数据类型, 要构建完整键值对
- 自定义变量
不以数字开头, 不建议用关键字命名
其他你喜欢就好
多页的数据采集 --> 分析请求链接变化规律
第一页: http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1
第二页: http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-2
第三页: http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-3
"""
for page in range(1, 26):
# 包含1 但是不包含26
# 请求链接
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{page}'
# 伪装模拟 --> 70%左右网站加User-Agent 就可以了, 如果不行, 你加其他 cookie host referer
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量response接收返回数据
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具: response <网页源代码>
response<响应对象>.text<文本> --> 获取响应的文本数据 <html字符串数据类型>
3. 解析数据, 提取我们想要的数据内容
- 书籍基本信息
解析方法:
re正则 --> 对于字符串数据直接进行解析提取
css选择器 --> 根据标签属性内容提取数据
xpath --> 根据标签节点提取数据
早退是没有资料没有录播, 课后会签到, 找助理老师获取录播 代码也可以
分两次提取:
- 第一次提取所有书籍信息
- 第二次提取具体每一本书籍内容
"""
# 把获取下来html字符串数据<response.text>, 转换成可解析对象
selector = parsel.Selector(response.text) # <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>
# 提取所有li标签 --> 会复制就可以了
lis = selector.css('.bang_list_mode li') # --> 返回列表, 列表里面元素是Selector对象 lis[0] 索引取值, 提取第一个元素
# 把列表里面元素一个一个提取出来 --> for循环遍历
for li in lis:
"""
.name a --> 定位一个class类名为name下面a标签
a::attr(title) --> 获取a标签里面title属性
attr() --> 获取属性
get() --> 获取第一个标签数据, 返回字符串数据类型
.tuijian::text --> 获取文本
div:nth-child(6) --> 第6个div标签
css选择器/xpath/re 在系统课程里面 三节课, 7.5个小时才讲完 --> 理论+案例
跟着老师系统学, 有问题随便问, 知识也会教
"""
title = li.css('.name a::attr(title)').get() # 提取标题
comment = li.css('.star a::text').get() # 提取评论
recommend = li.css('.tuijian::text').get() # 提取推荐
author = li.css('.publisher_info a::attr(title)').get() # 提取作者
date = li.css('.publisher_info span::text').get() # 时间
press = li.css('div:nth-child(6) a::text').get() # 出版社
price_n = li.css('.price .price_::text').get() # 售价
price_r = li.css('.price .price_r::text').get() # 原价
price_s = li.css('.price .price_s::text').get() # 折扣
price_e = li.css('.price_e .price_n::text').get() # 电子书
href = li.css('.name a::attr(href)').get() # 详情页
# 以字典方式保存数据
dit = {
'标题': title,
'评论': comment,
'推荐': recommend,
'作者': author,
'时间': date,
'出版社': press,
'售价': price_n,
'原价': price_r,
'折扣': price_s,
'电子书': price_e,
'详情页': href,
}
# 写入数据
csv_writer.writerow(dit)
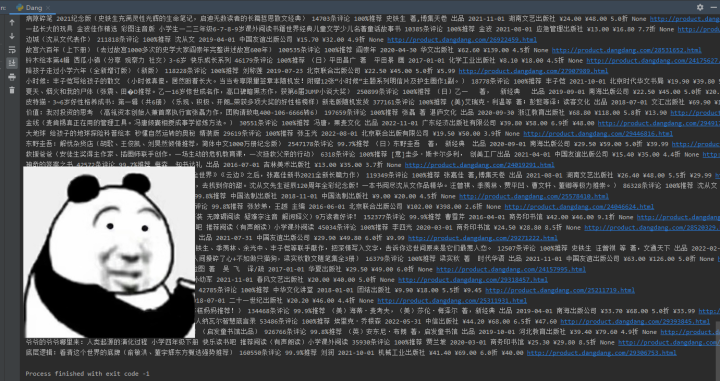
print(title, comment, recommend, author, date, press, price_n, price_r, price_s, price_e, href) 2)效果展示
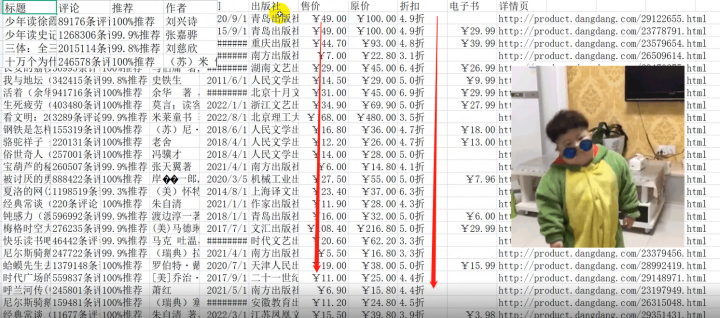
2)效果展示
爬取数据——
保存到表格——
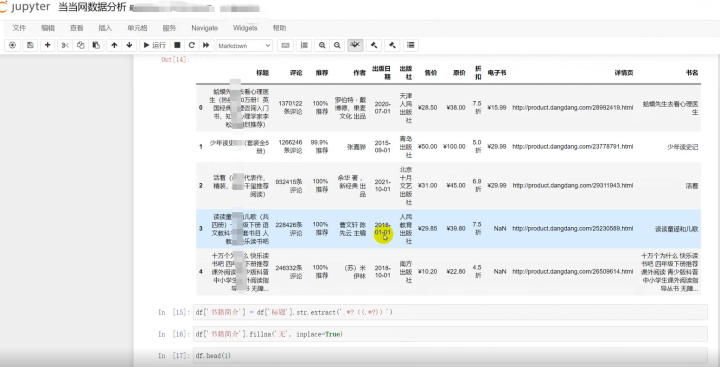
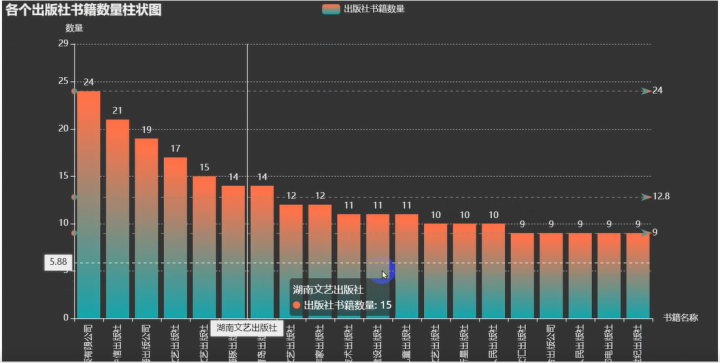
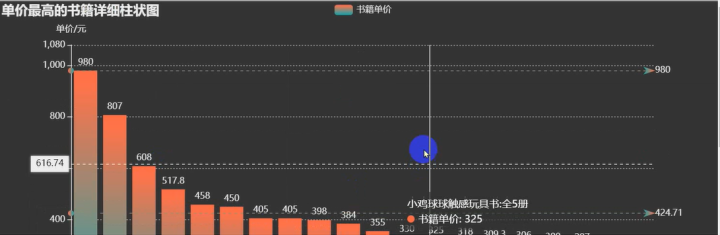
数据可视化——
可视化的代码很多这里就不一一展示了。
总结

好啦!今天的文章内容写到这里就结束了哈,想学习的可以找我啦~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目0.9 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目1.0 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.7 【Python爬虫实战】 不生产小说,只做网站的搬运工,太牛逼了~(附源码)
项目0.8 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
项目1.2
【Python实战】如果没有音乐,生活就是一个错误 :n首回味无穷的歌,总有一曲深得你心哦~
项目1.3
【Python实战】美哭你的极品壁纸推荐|1800+壁纸自动换?美女动漫随心选(高清无码)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)