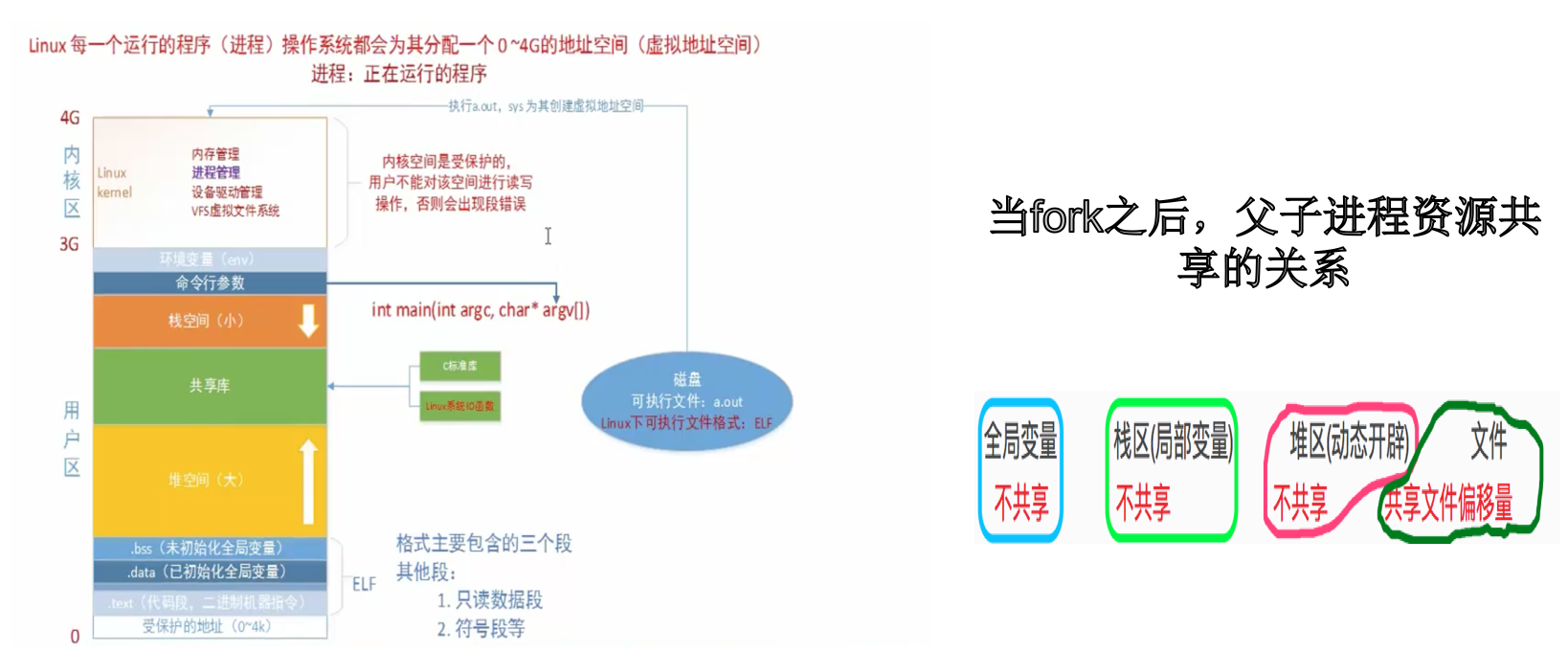
问题描述
初学python,在用python中的urllib.request.urlopen()和urllib.request.urlretrieve方法打开网页时,有些网站会抛出异常: HTTP Error 403:Forbidden
问题原因
网站对爬虫的操作进行了限制
解决方法
伪装成浏览器,
headers = {'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
req=urllib.request.Request(url=target_url,headers=headers)
urllib.request.urlopen(req).read()
import urllib.request opener = urllib.request.build_opener() opener.addheaders = [('User-agent', 'Mozilla/5.0')] urllib.request.install_opener(opener) urllib.request.urlretrieve("type URL here", "path/file_name")
基础用法如下:
1.urlopen()方法
urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
参数url表示远程数据的路径,一般是网址;
参数data表示以post方式提交到url的数据(玩过web的人应该知道提交数据的两种方式:post与get。如果你不清楚,也不必太在意,一般情况下很少用到这个参数);
参数proxies用于设置代理。
urlopen返回 一个类文件对象,它提供了如下方法:
read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样;
info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息
getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到;
geturl():返回请求的url;
import urllib url = "http://www.baidu.com/" #urlopen() sock = urllib.urlopen(url) htmlCode = sock.read() sock.close fp = open("e:/1.html","wb") fp.write(htmlCode) fp.close #urlretrieve() urllib.urlretrieve(url, 'e:/2.html')
2.urlretrieve方法
直接将远程数据下载到本地。
urllib.urlretrieve(url[, filename[, reporthook[, data]]])
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
下面通过例子来演示一下这个方法的使用,这个例子将新浪首页的html抓取到本地,保存在D:/sina.html文件中,同时显示下载的进度。
import urllib def callbackfunc(blocknum, blocksize, totalsize): '''回调函数 @blocknum: 已经下载的数据块 @blocksize: 数据块的大小 @totalsize: 远程文件的大小 ''' percent = 100.0 * blocknum * blocksize / totalsize if percent > 100: percent = 100 print "%.2f%%"% percent url = 'http://www.sina.com.cn' local = 'd:\\sina.html' urllib.urlretrieve(url, local, callbackfunc)