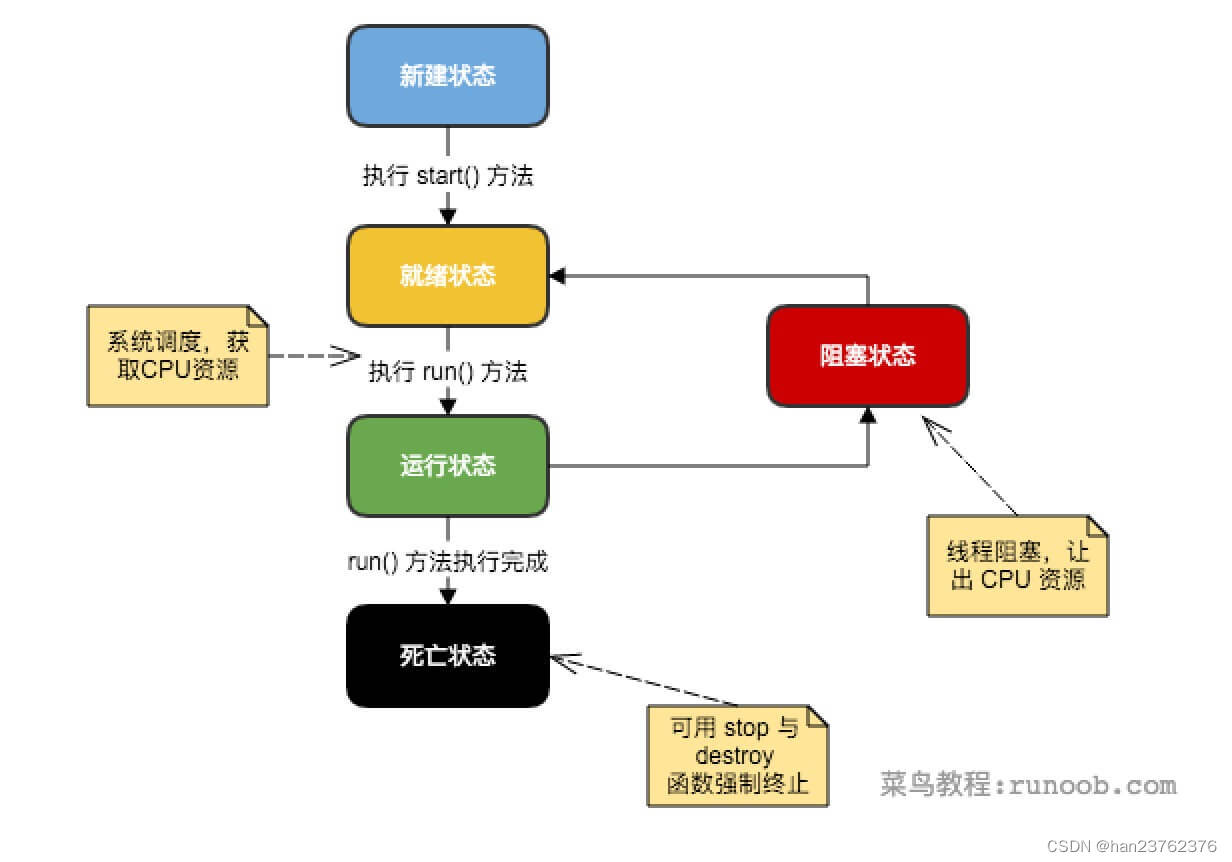
爬虫简介
爬虫与网络请求
网络爬虫是一个自动提取网页的程序,一般都分为3步:数据爬取,数据解析,数据存储。数据爬取就是模拟浏览器发送请求,所以需要对网络请求HTTP/HTTPS有一定了解
相关概念:
HTTP:超文本传输协议(Hyper Text Transfer Protocol)是一个请求-响应协议,指定了客户端可能发送给服务器的消息类型以及得到的响应类型。请求和响应消息的头以ASCII形式给出。
HTTPS:超文本传输安全协议(Hypertext Transfer Protocol Secure)是在HTTP的基础上通过SSL(传输加密和身份认证)保证传输安全的协议
HTML:超文本标记语言(Hyper Text Markup Language)是包括一系列标签的标记语言。通过浏览器识别,形成浏览器上看到的网页
请求方式
get请求:请求指定的页面信息,并返回实体主体(较便捷但不安全且请求参数的长度有限制)
post请求 :向指定资源提交数据进行处理请求(较安全且数据整体没有限制)
put请求:从客户端向服务器传送的数据取代指定的文档的内容(不要求掌握)
delete请求:请求服务器删除指定的页面(不要求掌握)
patch请求: PUT 方法的补充,用来对已知资源进行局部更新(不要求掌握)
head请求:类似 GET 请求,用于获取报头,无响应中具体的内容
请求头/响应头参数(部分常用)
Accept:文本的格式
Accept-Encoding:编码格式
Connection:规定长链接 /短链接
Cookie:验证用的
Host:域名
Reference:标志从哪个页面跳转过来的
User-Agent:浏览器和用户的信息
请求状态码
1xx:信息,请求收到,继续处理
2xx:成功,行为被成功地接受、理解和采纳 (如200 - 请求成功)
3xx:重定向,为了完成请求,必须进一步执行的动作 (如301 - 资源(网页等)被永久转移到其它URL)
4xx:客户端错误,请求包含语法错误或者请求无法实现 (如404 - 请求的资源不存在)
5xx:服务器错误,服务器不能实现一种明显无效的请求(如500 - 内部服务器错误)
爬虫入门:
爬虫的价值:
买卖数据(高端的领域价格特别贵)
数据分析:出分析报告
流量
指数阿里指数百度指数
爬虫的合法性
政府没有法律规定爬虫是违法的,也没有法律规定爬虫是合法的公司概念:
公司让你爬数据库(窃取商业机密)责任在公司
爬虫的范围
爬虫只能爬取用户能访问到的数据
例:爱奇艺的视频(vip非vip)
1.普通用户只能看非vip 爬取非vip的的视频
2.vip 可爬取vip的视频
3.普通用户想要爬取vip视频(黑客)
爬虫的分类:
通用爬虫
使用搜索引擎:百度谷歌360雅虎搜狗
优势:开放性 速度快
劣势:目标不明确
返回内容:基本上%90是用户不需要的
不清楚用户的需求在哪里
聚焦爬虫(学习的重点)
特点:目标明确;对用户的需求非常精准;返回的内容很固定
增量式爬虫
特点:从第一页请求到最后一页
深度爬虫(学习的重点):
可爬取静态数据(html css)和动态数据(js代码加密的内容)
爬虫的流程
(1)确认url
(2)发送请求(get,post)获取数据(通过urlopen,requests等)
(3)解析数据(通过正则,xpath,bs4等)
(4)数据持久化(数据保存json csv mys)